『 SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. 2015. 』
SegNet은 도로를 달리면서 촬영한 영상에 대해 pixel-wise semantic segmentation을 수행하기 위해 설계된 모델이다. 기존 semantic segmentation 모델들이 해상도가 떨어진다는 단점을 Encoder-Decoder 구조를 통해 극복하였고, 이후 semantic segmentation task에 많은 영향을 끼친 모델이다.
0. Abstract
본 논문에서는 Semantic pixel-wise segmentation에 사용하는 SegNet 모델을 제안한다. 이 모델은 Encoder-Decoder에 pixel-wise classification layer를 붙인 구조로 이루어져 있다. Encoder 구조는 VGG16에서 classification layer를 제외한 13개의 convolution layer와 동일하고, Decoder는 Encoder를 거쳐 나온 저해상도 feature map을 pixel-wise classification을 위해 input 해상도와 같은 feature map 으로 매핑하는 역할을 한다.
SegNet에서 사용한 새로운 아이디어는 Decoder에서 낮은 해상도 feature map을 Up-sampling 하는 것이다. 이 때 Up-sampling에는 max pooling을 할 때 계산된 index를 기억해서 max unpooling을 해주는 방식인데 이 방법에 대해서는 밑에서 자세히 기술하도록 하겠다.
SegNet은 메모리와 computational time 측면에서 모두 효율적으로 설계되었으며 다른 모델들보다 parameter의 수가 매우 적어 End-to-End 학습이 가능하다. 또한 road scene segmentation, SUN RGB-D indoor scene segmentation task에서 좋은 성능을 낸다.
Up-samping
https://dacon.io/en/forum/406022
여러가지 Upsampling 방식들
dacon.io
1. Introduction
이전까지 Semantic Segmentation Task에서 사용한 Max pooling과 Sub-sampling은 feature map의 해상도를 떨어뜨린다는 문제를 가진다. 때문에 논문에서는 이를 극복할 수 있는 pixel-wise semantic segmentation을 사용한 SegNet 모델을 제안한다. 이를 통해 도로, 건물, 자동차, 보행자와 같은 정보를 잘 이해할 수 있고 class간의 경계를 잘 구분할 수 있다.

SegNet의 구조는 위 그림과 같다. 가장 먼저 나오는 Encoder 구조는 VGG16 모델의 Convolution layer와 동일하고, Decoder에서는 대응하는 Encoder로 부터 Index를 수신받아 Max Unpooling을 수행한다. 이를 통해 boundary delineation(외형 그리기, 묘사)을 향상시키고, End-to-End 학습시 계산하는 parameter를 줄이고, 약간의 수정만으로 다른 Encoder-Decoder 아키텍처에 통합할 수 있다.
이 논문의 저자들은 CamVid road scene segmentation과 SUN RGB-D indoor scene segmentation으로 성능을 평가했다.
2. Literature Review
2장에서는 본 논문에서 사용한 방법과 Task에 대한 설명을 기술한다. (CamVid, FCN, CRF 등.. )
3. Architecture
SegNet의 모델 구조는 위의 Figure 2와 같다. 우선 Encoder는 VGG16모델의 13개 Convolution Layer와 같은 구조로, VGG16 모델에서 Classification Layer를 제거한 이유는 parameter를 줄이고 메모리 사용량을 줄이기 위해서이다. 이 때 Encoder는 VGG16 구조를 따르기 때문에 pre-trained weight를 사용할 수 있다. Convolution Layer에는 Bacth Normalization, ReLU 함수, stride 2인 2x2 max pooling을 사용하였다.
Max pooling과 sub-sampling을 사용하게 되면 feature map의 해상도가 떨어지게 되어 boundary delineation이 나빠진다. 따라서 SegNet은 max unpooling 기법을 사용했는데, 아래의 그림과 같이 Encoder에서 max pooling을 진행할 때 그 위치 Index를 기억해 두었다가 Decoder에서 Up-sampling을 할 때 해당 Index를 기억해서 해당 위치에 값을 넣어주고 나머지는 0으로 채워주는 방식이다.
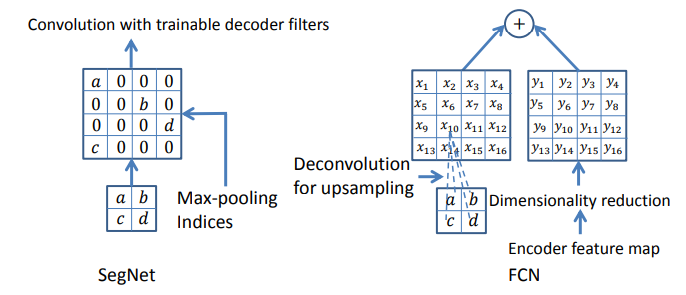
이런식으로 Up-sampling을 진행시 Transposed Convolution을 사용하지 않아 전체 Parameter를 줄일 수 있다. DeconvNet과 U-Net 모델과 비슷하지만, DeconvNet과는 Fully Connected Layer, U-Net과는 conv5, max-pool 5 block의 유무에서 차이가 있다.
3.1. Decoder Variants
여기서는 논문의 저자들이 Decoder 구조를 조금씩 변환해 가면서 실험해본 결과를 기술한다.
(1) SegNet-Basic
: 위에서 기술한 SegNet 방법과 동일
(2) FCN-Basic
: Decoder에서 FCN 방법을 사용 (FIgure 3의 오른쪽 방법)
(3) SegNet-Basic-SingleChannelDecoder
: SegNet-Basic과 동일하지만, Decoder의 Filter가 1개의 채널을 가지게 한다. 이를 통해 parameter를 줄이고 Inference의 속도가 빨라진다.
(4) FCN-Basic-NoAddition
: Encoder feature map의 addition step을 삭제하고 Up-sampling만 학습
(5) Bilinear-Interpolation
: 위 모델에서 Up-sampling layer에 fixed bilinear interpolation weight를 사용
(6) SegNet-Basic-EncoderAddition
: 기본 모델의 각각의 layer에 64 채널짜리 feature map을 추가
(7) FCN-Basic-NoDimReduction
: Encoder에서 차원 축소를 하지 않음
3.2. Training
논문에서는 CamVid road scenes dataset을 사용
- 학습 데이터 367장, 테스트 데이터 233장, 360x480, 11개 Class(road, builing, cars, pedestrinas...)
- He initialization, SGD optimizer, learning rate = 0.1
Class의 크기에 따라 Loss에 미치는 영향이 달라진다. 따라서 논문에서는 Median Frequency Balancing을 사용하였다.
Median frequency balancing
이미지 분류 문제에서 클래스 불균형 문제를 해결하기 위한 기술 중 하나로 손실 함수의 가중치를 클래스별로 조정하여 클래스 불균형 문제를 해결한다. 가중치는 클래스의 빈도수를 기반으로 계산됩니다. 빈도가 낮은 클래스는 높은 가중치를 가지고, 빈도가 높은 클래스는 낮은 가중치를 가지게 되어 모델이 빈도가 낮은 클래스를 무시하지 않고 잘 학습할 수 있도록 돕는다.
Median frequency balancing은 Semantic Segmentation 분야에서 주로 사용되며, 특히 자동차 등의 객체 검출 및 분할 문제에서 높은 성능을 보인다.
3.3. Analysis
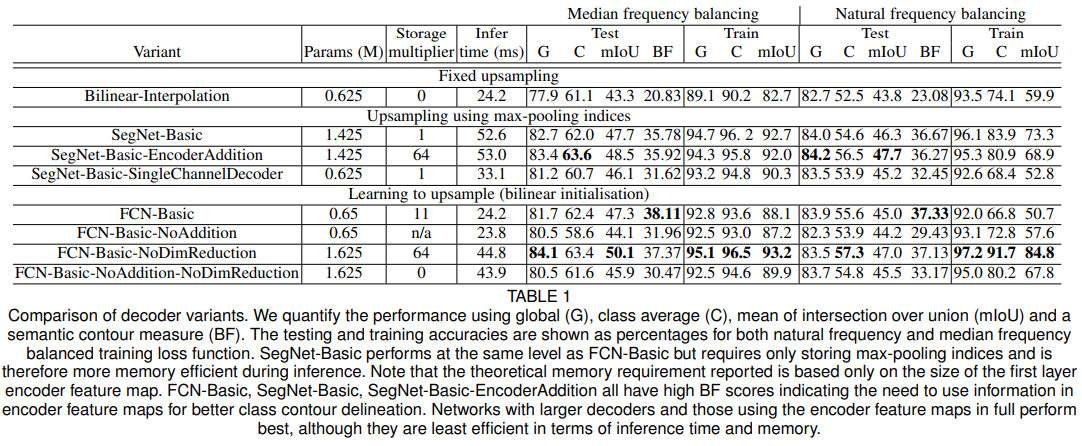
위에서 만든 여러가지의 Decoder Variants를 평가하기 위해 3가지 척도를 사용했다.
(1) Global Accuracy : 올바르게 분류된 픽셀 수 / 전체 픽셀 수
(2) Class Average Accuracy : 클래스마다 계산한 Accuracy의 평균
(3) Boundary F1 Score
이후는 분석 내용 기술.... (Decoder Variants 마다 성능이 이렇고 이렇다 -> Table 1 실험 결과 참고)
실험 결과를 정리하자면
1. Encoder에서 추출한 Feature map을 원본 크기 그대로 사용할 때 최고의 성능을 얻을 수 있다.
2. Inference 과정에서 메모리 제약이 있을 경우, Feature map의 차원을 축소하거나 Max pooling Index 처럼 압축된 형태로 사용할 경우 성능을 향상시키는데 도움이 된다.
3. Encoder에 대한 Decoder의 크기가 커질수록 모델의 성능이 향상된다. (Encoder에서 추출한 Feature map을 더 정확하게 복원할 수 있기 때문에)
4. Benchmarking
Road Scene Segmentation, Indoor Scene Segmentation 2가지 Dataset에 대한 평가를 진행
4.1. Road Scene Segmentation
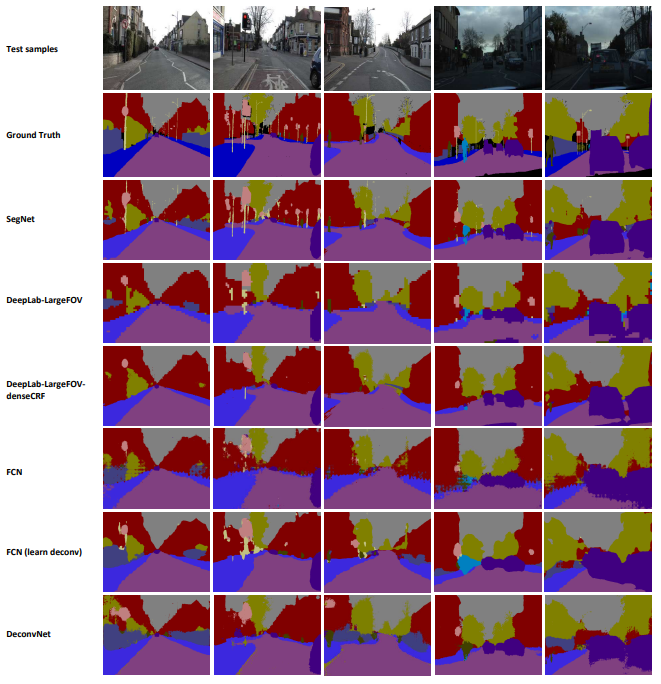
SegNet이 다른 모델들보다 경계를 잘 구분하고 작은 객체를 잘 잡아내는 것을 확인할 수 있다.
4.2. SUN RGB-D Indoor Scenes

SUN RGB-D Dataset으로 평가한 결과를 확인해 보면 SegNet 모델이 정성적으로 평가했을 때 가장 좋은 성능을 보이는 것을 확인할 수 있다.

정량적으로 평가 했을 때는 mIoU, BF 성능이 절대적으로 낮지만, 다른 모델들 보다는 좋은 성능을 보인다.
<참고자료>
2) SegNet
SegNet은 2016년에 공개된 모델로, 도로를 달리면서 촬영한 영상(road scene)에 대해 pixel-wise semantic segmentation 하기 위해 설계된 …
wikidocs.net
https://eremo2002.tistory.com/120
SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
arxiv.org/pdf/1511.00561.pdf Abstract SegNet이라는 pixel-wise segmentation 모델을 제안한다. SegNet은 encoder-decoder로 아키텍처로 encoder는 f.c layer를 제외한 VGG16을 사용하고 decoder는 학습 파라미터가 필요 없는 un-ma
eremo2002.tistory.com
세 줄 요약
1. 기존 Semantic Segmentation 방법이 해상도가 낮아지는 문제를 Encoder-Decoder로 극복한 SegNet 모델 제안
2. Max pooling시 Index를 기억해 Up-sampling 시 활용하는 Max Unpooling 기법을 사용해 메모리, 속도 성능 UP
3. Road Scene, Indoor Task에서 좋은 성능을 보였고 이후 Semantic Segmentation 모델들에 많은 기여를 함

'논문 paper 리뷰' 카테고리의 다른 글
| [Paper Review] GLocal-K 논문 이해하기 (1) | 2023.04.27 |
|---|---|
| [X:AI] RetinaNet 논문 이해하기 (0) | 2023.04.14 |
| [Paper Review] Factorization Machines 논문 이해하기 (0) | 2023.04.09 |




댓글