『 Focal Loss for Dense Object Detection. 2017. 』
본 논문은 Object Detection task에서 사용하는 Label 값에서 상대적으로 Background에 비해 Foreground의 값이 적어 발생하는 Class Imbalance 문제를 극복할 수 있는 Focal Loss Function을 제안한다.
0. Abstract
1-stage Detector 모델들은 빠르고 단순하지만, 아직 2-stage Detector 모델들의 정확도를 넘지 못했다. 논문에서는 그 이유를 class imbalance로 파악했다. 따라서 이를 극복할 수 있는 Focal Loss와 이 방법이 활용된 RetinaNet을 제안하였다.
1. Introduction
R-CNN 같은 2-stage Detector 모델들은 첫번째 stage에서 Region Proposal을 생성하고, 두번째 stage에서 Convolution을 이용한 Classification을 진행한다. 이 방법은 첫번째 stage에서 object가 존재할 만한 Region Proposal을 뽑아주기 때문에 class imbalance 문제가 발생하지 않는다. (또한, 두번째 stage에서 foreground-background를 1:3 비율로 만들어줌)
하지만, 1-stage Detector 모델들은 하나의 이미지에서 매우 많은 후보들을 처리해야하기 때문에 비효율적이다. 따라서 본 논문에서는 이러한 class imbalance 문제를 해결하기 위한 Focal Loss 방법을 제안한다. 이 방법은 객체를 잘 파악할 수 있는 쉬운 예시에 대해 가중치를 줄여 어려운 예시에 집중할 수 있게 한다.
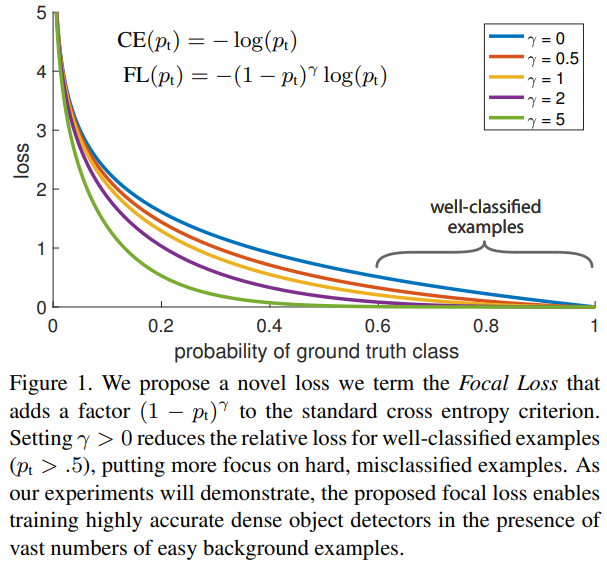
기존 Cross Entropy Loss에 factor를 추가한 형태로 기존의 Cross Entropy 방법($\gamma$=0)보다 Focal Loss 방법을 적용하였을 때 성능이 더 좋아지는 것을 확인할 수 있다.
또한 논문에서는 Focal Loss의 효율성을 보여주기 위해 ResNet-101-FPN을 backbone으로 하는 RetinaNet을 제안한다.
2. Related Work
Classic Object Detectors : HOG, DPM (Sliding Window)
2-stage Detector : R-CNN, Faster R-CNN 등 (Region Proposal - Classification)
1-stage Detector : YOLO, SSD 등 (2-stage에 비해 정확도 낮음), RPN의 anchor와 SSD의 feature pyramid를 사용
Class Imbalance : 1-stage Detector는 객체가 별로 없음에도 이미지마다 많은 후보군을 처리해야한다. 이러한 불균형은 두가지 문제를 야기하는데 첫번째는 training이 비효율적이라는 것이고 두번째는 negative 값이 training에 영향을 준다는 것이다. 이에 대한 해결 방안은 hard negative mining이다.
Robust Estimation : 이전까지는 robust한 loss function을 많이 사용하였는데(Huber Loss는 큰 error를 가지는 example의 weight를 줄여 outlier들의 기여를 줄임), Focal Loss는 이와 반대로 easy example의 weight를 줄인다.
물론 지금까지 2-stage Detector에서 Class Imbalance를 해결하려는 노력이 없었던 것은 아니다.
R-CNN, SSD : hard negative mining
YOLO : conditional class probability를 계산해 object와 background 판단
3. Focal Loss
Focal Loss는 1-stage object detection task의 학습과정에서 foreground와 background간의 imbalance를 해결하기 위해 설계되었다.


$p$ : 모델이 예측한 값
Binary Classification에서 일반적으로 사용하는 Cross Entropy 식이다. $p_t$를 위의 식에 맞게 변형하면 $-log(p_t)$형태가 된다. 이 때 $p_t$가 0.5 이상이면 easy example이다.
3.1. Balanced Cross Entropy
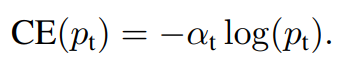
Class Imbalance를 해결하기 위해 weighting factor $\alpha$를 적용한 형태로 Positive에는 0~1사이의 $\alpha$를, Negative에는 1-$\alpha$를 적용한다.
이 Loss는 Focal Loss의 기반이 된다. (Positive와 Negative 사이의 balance를 잡아주지만, Easy와 Hard example에 대해서는 balance를 잡아주지 못함)
3.2. Focal Loss Definition
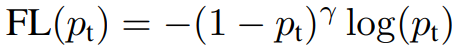
Easy Example이 Loss에 미치는 영향을 줄이기 위해 위와 같은 factor를 추가하였다.
$p_t$가 0.5보다 큰 값이 easy example이기 때문에 예를들어 easy example의 $p_t$는 0.7이고 hard example은 0.3이라고 할 때 앞에 있는 factor는 각각 $0.3^{\gamma}$, $0.7^{\gamma}$이 된다. 결국 제곱할 수록 값이 작아져 easy example이 최종 Loss에 미치는 영향은 hard example보다 적어진다.
$\gamma$는 가중치를 줄이는 정도를 조정하며 0일 때는 Cross Entropy Loss와 같은 형태이다. $\gamma$를 키울 수록 factor의 영향력이 커지고, 실험 결과 $\gamma$가 2일 때 가장 좋은 성능을 보였다.

또한 위의 식처럼 $\alpha$를 사용하지 않았을 때보다 $\alpha$를 사용했을 때 성능이 더 좋았다.
3.3. Class Imbalance and Model Initialization
기존의 Classification에서는 output을 1과 -1로 두었는데, 본 논문에서는 object에 대해 모델이 예측한 p(prior)를 추가하였다. 이는 Class Imbalance한 경우 Cross Entropy와 Focal Loss에서모두 학습 안정성을 향상시켰다.
3.4. Class Imbalance and 2-stage Detectors
2-stage Detector에서는 2-stage cascade와 biased minibatch sampling 방법으로 Imbalance 문제를 해결한다. Focal Loss는 이러한 매커니즘을 1-stage에서 다루기 위해 디자인되었다.
4. RetinaNet Detector
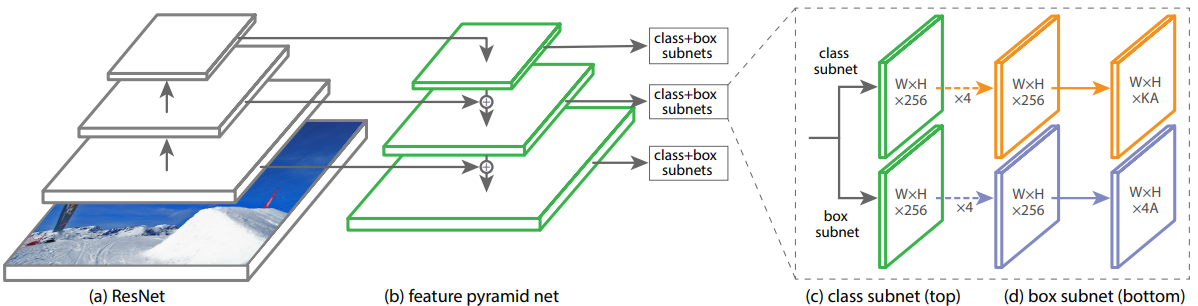
논문에서는 앞에서 제안한 Focal Loss 실험을 위한 RetinaNet 모델을 제안한다. RetinaNet은 FPN(Feature Pyramid Network)을 Backbone으로, 각각 Classification과 Box Regression을 담당하는 Subnet을 사용한다. ResNet 아키텍처의 맨 위에서 FPN을 사용하며 이를 통해 rich, multi-scale convolution feature pyramid를 만들 수 있다.
Backbone을 거쳐 나온 output에 대해 class subnet은 Classification을, box subnet은 bounding box regression을 수행한다.
RetinaNet은 Focal Loss의 효율성을 판단하기 위해 의도적으로 단순하게 디자인 되었다고 한다.
Feature Pyramid Network Backbone
FPN 모델은 하나의 해상도를 가지는 Input 이미지에 대해 multi-scale feature pyramid를 생성한다. Pyramid의 각 level은 다른 scale의 object를 detect하는데 사용된다.
Anchors
논문에서는 3개의 aspect ratios(1:2, 1:1, 2:1)와 3개의 anchor size($2^0, 2^{1/3}, 2^{2/3}$)을 가지는 9개의 anchor를 사용하였다. Anchor의 threshold는 0.5로 설정하였고 만약 0~0.4면 background, 0.4~0.5는 무시하였다.
[Object Detection] Anchor Box 설명과 pytorch 구현
안녕하세요 pulluper 입니다 😊 오늘은 object detection에서 많이 쓰이는 anchor box 에 대하여 알아보겠습니다. Anchor 란 "닻"을 의미합니다. 배를 움직이지 않게 하고 배가 어느 위치에 있는지 확인하는
csm-kr.tistory.com
Classification Subnet
각 anchor에서 object가 존재할 확률을 계산한다. RPN 방식과 다르게 subnet이 깊고, 3x3 convolution 만을 사용하며, parameter를 공유하지 않는다.
Box Regression Subnet
FCN(Fully Convolutional Network)를 붙여서 사용하고, anchor 별로 4개의 offset(x, y, w, h)를 Regression한다. Classification Subnet과 Box Regression Subnet은 파라미터를 공유하지 않는다.
Inference
Figure 3 구조와 같은 모델로 Inference를 진행하였고, 속도를 높이기 위해 box prediction 점수가 높은 1000개만 사용하였고 NMS 기법을 적용하였다.
Focal Loss
Classification Subnet의 output에 대해 Focal Loss를 적용했다. $\gamma$가 2이고 $\alpha$가 0.25일 때 성능이 가장 좋았고 0.5 ~ 5일 때 RetinaNet이 상대적으로 robust했다.
Initialization
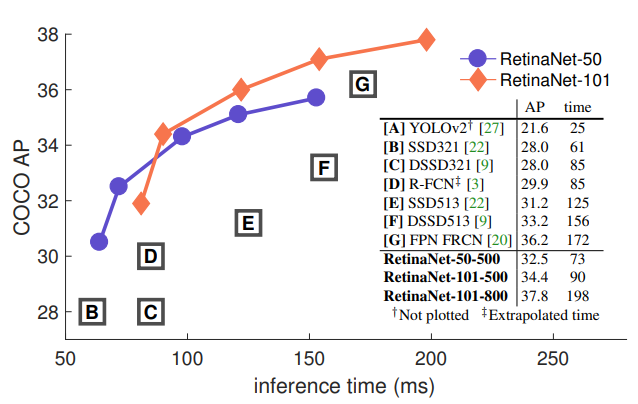
ResNet-50-FPN과 ResNet-101-FPN을 Backbone으로 실험하였고 FPN은 원본 논문대로 초기화하였다. 마지막 layer를 제외한 Convolution layer는 Bias = 0, Gaussian weight fill = 0.01로 초기화하였다.
Optimization
RetinaNet에서 최적화에 사용한 하이퍼 파라미터 기술 (SGD, Learning rate 등..)
<참고자료>
https://talktato.tistory.com/13
[논문 리뷰] (RetinaNet) Focal Loss for Dense Object Detection
나의 정리 RetinaNet은 one-stage로 동작하고 end-to-end 학습이 가능하다. network design은 RPN의 anchor, SSD의 feature pyramid 방식을 사용하여 기존의 network와 거의 비슷하지만 class imbalance 문제를 focal loss를 사
talktato.tistory.com
세 줄 요약
1. 1-stage Detector에서 발생하는 Class Imbalance 문제를 해결하기 위한 Focal Loss 제안
2. FPN을 backbone으로 사용하고 2개의 subnet 구조를 가지는 RetinaNet 모델 제안
3. 단순하게 Loss Function을 바꾸는 것으로 속도와 성능 개선을 이끌어냄

'논문 paper 리뷰' 카테고리의 다른 글
| [X:AI] SegNet 논문 이해하기 (0) | 2023.04.19 |
|---|---|
| [Paper Review] Factorization Machines 논문 이해하기 (0) | 2023.04.09 |
| [X:AI] Transformer 논문 이해하기 (0) | 2023.03.21 |




댓글