『Human Motion Instruction Tuning. CVPR. 2025.』
이번에 정리할 논문은 MotionGPT, MotionLLM 모델에 이어 등장한 LLaMo 논문이다. Motion이나 Video Input에 대해 사람이 질문을 던졌을 때, 해당하는 질문에 걸맞는 응답을 생성하는 모델을 만드는 것이 목표로, Video와 Motion에 대해 통합된 Visual Representation을 구성하여 LLM 모델로 하여금 Video와 Motion을 잘 이해하게 만들었다.
어찌보면 기존 MotionLLM의 모델 구성에 Video-LLaVA의 방법론(Image+Video)을 차용한 것으로 보이는데, 그럼 이 논문이 어떻게 Motion정보와 비디오 정보를 합쳐 LLM 모델의 멀티모달 추론 능력을 향상시켰는지 파악해보자.
Github[25.04.26. 기준 아직 미공개]
https://github.com/ILGLJ/LLaMo
GitHub - ILGLJ/LLaMo
Contribute to ILGLJ/LLaMo development by creating an account on GitHub.
github.com
0. Abstract
본 논문에서는 LLaMo(Large Language and Human Motion Assistant)라는 Human Motion Instruction Tuning 기반 Multimodal Framework를 제안한다. 기존 Instruction Tuning 방식들은 입력 비전 데이터를 Language Token으로 변환하는 접근이 대다수였지만, LLaMo에서는 Motion 데이터의 원래 형태를 유지한채로 Instruction Tuning을 진행한다. 그 결과 Motion 고유의 세밀한 정보를 유지할 수 있으며, Video와 Motion 데이터를 동시에 처리함으로써 보다 유연한 분석이 가능하다.
High-complexity 도메인에서 실험한 결과, LLaMo 모델의 우수한 성능을 확인하였다.
1. Introduction

디지털 휴먼이나 Motion 중심 애플리케이션이 확장됨에 따라 Motion 데이터의 특성을 효과적으로 활용할 수 있는 모델을 개발하는 것이 중요해지고 있다. 최근 Motion 분석에 있어 MotionGPT, MotionLLM과 같이 LLM을 활용해 Motion을 언어처럼 변환하여 멀티모달 처리를 진행한 연구가 좋은 성능을 보이고 있으나, 이러한 모델들은 Motion 데이터를 Tokenizing하거나 텍스트로 변환하는 과정에 의존하다보니, 공간 또는 시간적인 정보가 손실되는 문제가 발생한다.
본 논문에서는 기존 접근 방식의 한계점을 다음과 같이 지적한다.
- Motion 데이터의 Tokenizing 문제: Motion을 Discrete Token으로 Quantization할 때(ex. MotionGPT) 세밀한 움직임 정보가 사라진다.
- Text 변환 문제: Motion을 Text로 변환할 경우 움직임의 미묘한 차이를 잃게되어 행동 해석 능력이 저하된다.
- 3D 구조 정보 손실: Motion 데이터는 3D 구조와 행동 간의 연결성을 담고있으나, 언어 토큰 기반의 표현은 이를 완전히 반영하지 못한다.
- Video와 Motion 데이터의 분리 처리: 기존 방법은 Video와 Motion 데이터를 별개로 처리하여 비디오가 제공하는 맥락과 상호작용을 충분히 활용하지 못한다.
- Video 기반 방식의 비용 문제: 비디오는 정보량이 풍부하지만, 계산량이 많기 때문에 실시간 시스템에 적용하기가 어려움
이러한 문제들을 해결하기 위해 본 논문에서는 LLaMo 모델을 제안한다.
LLaMo는 Motion 데이터를 Text로 변환하지 않고 독립된 모달리티로 처리하며, Motion Estimator와 Enhancer를 도입하여 Motion 데이터와 Video 데이터를 직접 입력할 수 있도록 설계하였다. 또한 Cross Talker 모듈을 통해 Motion과 Text 특징을 동적으로 정렬하고, Text 기반으로 Motion Representation을 강화하였다.
실험 결과 MoVid-Bench, BABEL-QA 등의 벤치마크에서 SOTA 성능을 보였으며, 본 논문의 Contribution은 다음과 같이 정리할 수 있다.
- LLaMo는 Motion 데이터를 독립적인 모달리티로 다루어, Motion 고유의 세부정보를 보존한다.
- Cross Talker라는 모듈을 제안하여 Text 지침에 따라 핵심 Motion Frame Feature를 동적으로 집계하여, 중요한 Motion Feature 만을 선택할 수 있도록 하였다.
- LLaMo 아키텍처는 Raw Motion과 Video를 모두 입력으로 받을 수 있어 스포츠 분석, 헬스 케어 등 다양한 Human-centric 분야에 적용할 수 있다.
2. Related Work
2.1. Human-Centric Multimodal Representation
Multimodal Representation을 학습하는 연구는 Human-centric 분석에 있어 필수적인 요소이다. 관련 연구로는 최근에 등장한 Video-LLaVA가 있으며, 이 모델은 이미지와 비디오의 시각 데이터를 공유된 Linguistic Feature Space로 임베딩하는 방법을 활용해 Visual Reasoning을 가능케 하였다.
하지만, 현재 대부분의 모델들은 주로 정적인 이미지나 개별적인 Video Frame에 최적화되어 있어, 움직임의 연속성을 이해해야 하는 Sequence 기반의 동적 상황에서의 효과가 한정적이다. 또한, 비디오 Task에서는 개인정보 보호에 대한 문제가 민감하기 때문에 연구자들은 Motion 데이터를 그 대안으로 탐색하고 있다.
따라서 최근 등장하는 멀티모달 Framework들은 Visual 데이터와 Motion 데이터를 결합하여, 두 모달리티의 장점을 잘 활용하는 방식으로 연구가 진행되고 있다.
2.2. Human Motion Understanding
Human Motion Understanding 분야는 전통적으로 관절 Keypoint Sequence 형태로 Skeletal 데이터를 사용하여 사용자 개인정보를 보호하면서 움직임을 포착하고자 하였다. 초기 모델인 2s-AGCN이나 Transformer 기반의 MotionCLIP 등은 Motion 데이터를 Language Token 형태로 매핑하는 방식을 통해 움직임의 구조적인 측면을 효과적으로 포착할 수 있었다.
하지만, 이러한 방법들은 움직임만을 고려하기 때문에, 상황적인 맥락을 고려하는 데에 한계가 존재한다. 때문에 최근 Framework들은 Motion 데이터와 Visual 데이터를 통합하는 방식을 도입하여, 다양한 동적 환경에서도 일반화 능력을 갖추게 되었고 Contextual Cues가 필요한 분야에서 좋은 성능을 내고 있다.
이 때 Skeletal 데이터는 개인 식별의 위험 없이 Motion을 분석하는데 있어 큰 도움을 준다.
3. Methods

LLaMo Framework는 Video, Motion, Text를 효과적으로 처리하고 통합하기 위한 3가지 주요 모듈로 구성되어 있다.
- 멀티모달 Feature Extraction 모듈: Video/Motion Input을 독립적으로 인코딩하여 처리하고 Video로부터 유용한 Representation을 추출해 Motion Feature를 강화
- Cross Talker 모듈: 강화된 Motion Feature를 Text 지침에 따라 집계하고, Text와 같은 의미 공간에 정렬시켜 LLM이 사용할 수 있도록 변환
- Behavior Generation 모듈: LLM 모델이 정렬된 Motion Feature와 Text Representation을 사용하여, 상황에 맞는 인간 행동에 대한 설명을 Text로써 생성한다.
3.1. Enhanced motion Feature Extraction Module
이 모듈에는 Motion Estimator, Motion Encoder, Video Encoder, Feature Enhancer 4가지 구성요소로 이루어져 있다.
Motion Estimator
- Motion 데이터가 없는 경우, Video Frame으로부터 Motion 정보를 추정
Motion Encoder
- Motion 데이터를 Encoding
- Motion Frame $M$ → Motion Feature $F_M$
Video Encoder
- Video 데이터를 Encoding
- Video Frame $V$ → Video Feature $F_V$
Feature Enhancer
- 각 모달리티의 Feature에 대해 Self-Attention을 수행하고(→ $F_V'$, $F_M'$), 이후 Motion Feature $F_M$를 Query로 사용한 Cross-Attention을 통해 Video Representation의 Semantic을 추출
- 이후 Video의 Semantic Representation와 Motion Representation을 Residual이 포함된 FFN 형태로 결합하여 강화된 Motion Representation $\tilde{F}_M$을 생성.
3.2. Cross Talker Module
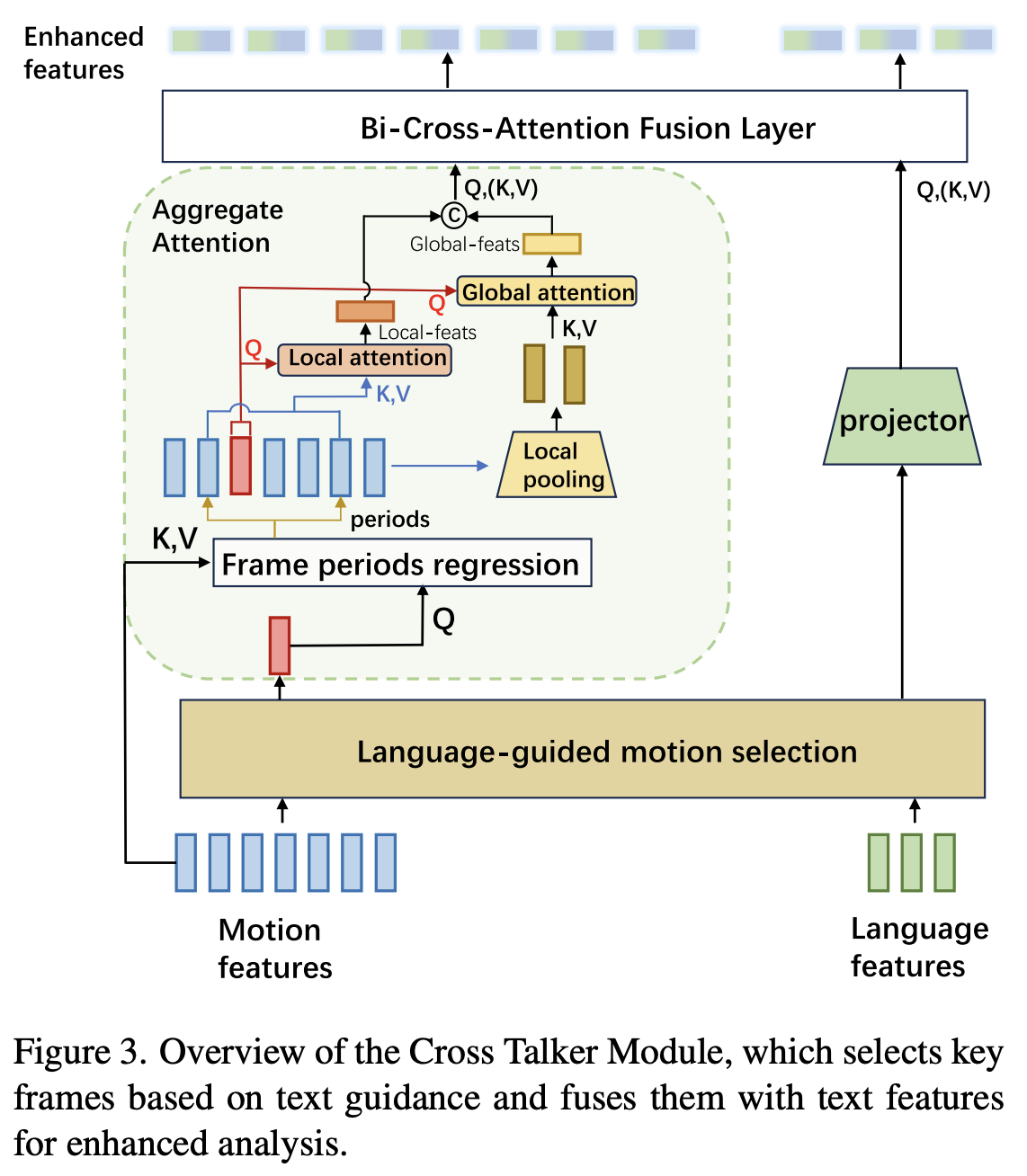
LLM 모델에 모든 Motion Frame을 입력할 경우, 계산량이 매우 커지고 성능이 저하된다. 특히 Sequence 길이가 길수록 자원 소모나 학습 품질의 문제가 발생하기 때문에, 본 논문에서는 Context에 따라 의미 있는 Motion Frame만을 선택해 사용하는 Cross Talker 모듈을 고안하였다.
Language-Guided Frame Selection
- Text Embedding $F_T$와 강화된 Motion Feature $\tilde{F_M}$를 Cross-Attention하여 각 Text Token과 Motion Frame간의 연관성을 나타내는 행렬 A를 계산.
$$A = Softmax(\frac{F_TW_Q(\tilde{F_M}W_K)^\top}{\sqrt{d}})$$
- 이후 Max Pooling을 통해 각 Frame의 중요도 점수 $s_j$를 얻고, 점수가 높은 상위 $K$개의 Frame을 Viewpoint Frame으로 선택
- 이를 통해 Sequence 길이가 $T$ → $K$로 줄어, 계산량이 $O((L_T+T)^2)$ → $O((L_T+K)^2)$로 크게 줄어든다.
Adaptive Contextual Feature Aggregation
- 위에서 구한 Viewpoint Frame마다 Local Window와 Global Segment를 활용해 Local & Global Context를 잡고자 하였다.
- 각각의 Viewpoint Frame을 Query로, 선택되지 않은 Motion Feature를 Key와 Value로 두고 Cross-Attention을 진행하였다.
선택되지 않은 Frame을 학습에까지 활용하여 전체 Global Context를 잡고자 한걸까?
Local Window
$$W_k = {j | |j-k| \leq r_k \times T}$$
- $r_k$: Adaptive receptive field size
Local Attention
$$F_{local}(k) = \tilde{F}_M(k) + Attention(\tilde{F}_M(k), \tilde{F}_M(W_k), \tilde{F}_M(W_k))$$
→ fine-grained detail을 잡아내기 위해 사용
여기에 Global Context를 결합하기 위해 $N$개의 Sequence에 대해 $\tilde{F}_M$을 Average Pooling하여 얻은 $F^{seg}_M$를 사용해 Global Attention을 계산한다.
Global Attention
$$F_{global}(k) = F_{local}(k) + Attention(F_{local}(k), F_M^{seg}, F_M^{seq})$$
Bidirectional Cross-Modal Fusion
Cross-Attention을 양방향으로 수행하여 Motion → Text, Text → Motion 업데이트를 모두 수행한다. 이후 FFN을 통해 Motion과 Text Representation을 결합하여 최종 입력 $F_{fusion}$을 구성한다.
본 논문에서는 이러한 방식을 통해 복잡한 인간 행동에 대해 상황 맥락적인 이해가 가능하다고 말한다.
3.3. Behavior Generation Module
Behavior Generation Module은 앞서 얻은 $F_{fusion}$을 바탕으로 인간 행동에 대한 텍스트 설명 $Y$를 생성한다. 이 모듈에서는 LLM $h(\cdot)$을 이용하며, 의미적으로 일관되고 상황에 부합하는 출력 시퀀스로 변환한다.
$$Y = h(F_{fusion}) = {y_1, y_2, ... , y_L}$$
여기서 $t$번째 생성된 토큰 $y$의 생성 확률은 아래와 같이 정의된다.
$$p(y_t|y_{1:t-1}, F_{fusion}) = Softmax(W_oh_t)$$
- $h_t$: 언어 모델 내부의 hidden state
- $W_o$: 출력 Projection Matrix
이러한 Autoregressive한 생성 방식 덕분에 LLaMo는 Motion과 Text 모달리티의 세밀한 정보를 반영하여, 정교하고 일관된 행동 설명을 생성할 수 있다(매 시점마다 Fusion Feature와 이전 토큰을 기반으로 새로운 토큰을 생성해 하나의 Narrative를 생성).
3.4. Training Objective
LLaMo 학습에는 Pretrained 언어 모델을 Fine-tuning하는 방법을 사용하였다. 학습 과정에서는 Motion Encoder와 Video Encoder는 Frozen시키고, 언어 모델이 멀티모달 입력과 잘 정렬되는데에 집중한다. 이 때 입력된 비디오, 모션, 텍스트 특징에 대해 맥락적으로 일치하는 설명을 생성하기 위해 정답 토큰의 Negative log-likelihood를 낮추는 것이 목표이다.
즉, 비디오와 모션 데이터에 담긴 인간 행동의 세밀한 측면까지 충실히 포착할 수 있게 학습시키려 하였다.
4. Experiments
4.1. Implementation Details
Training Datasets
※ Video + Motion Dataset
- MoVid
- Swing: 새롭게 구축한 커스텀 데이터 셋(야구/골프 스윙 비디오 모션 캡처 데이터 + 전문가의 Q&A 설명 포함
※ Motion Dataset
- HumanML3D
- KIT-ML
- Mo-RepCount
Evaluation Datasets
- MoVidBench: 비디오와 모션에 대한 이해 능력 평가용
- Swing: 전문 스포츠 분석 능력 평가
- BABEL-QA : 모션 기반 질문응답 능력 평가용
- Mo-RepCount: 반복 동작 세부 정보를 얼마나 잘 포착하는지 평가
Evaluation Metrics
MoVidBench
- 신체 부위 인식 (Body-part awareness)
- 시퀀스 처리 능력 (Sequential reasoning)
- 방향성 분석 (Direction analysis)
- 추론 능력 (Reasoning ability)
- 환각 발생률 (Hallucination)
Swing
: GPT-4를 통한 주관적 평가 방식 사용(0점~5점 척도로 스코어링)
- 합리성 (Reasonableness)
- 일관성 (Coherence)
- 적절성 (Pertinence)
- 적응성 (Adaptability)
나머지 데이터에 대한 정보는 논문 참고
4.2. Results


Evaluation on Motion Understanding in MoVid-Bench
- MotionGPT는 복잡한 모션 데이터에 대한 추론력이 낮고, Hallucination 발생 빈도도 높음
- MotionLLM은 시퀀스 이해 측면에서 개선이 있지만, 여전히 모션 데이터를 언어로 변환하기 때문에 성능 저하 발생
- LLaMo는 거의 모든 항목에서 최고 정확도를 기록함
Evaluation on Video Understanding in MoVid-Bench
- Table 1을 보면, MotionLLM이 일부 신체 부위 인식에서 LLaMo보다 앞섰지만, LLaMo는 추론 능력, 총점에서 더 뛰어나다.
Evaluation on BABEL-QA

복잡한 모션 기반 질의응답 성능을 평가하는 데이터셋인 BABEL-QA을 가지고 한 평가에서도 LLaMo는 좋은 성능을 보였다.
Professional Sports Analysis

Swing 데이터셋은 전문가 코치가 작성한 답변을 Ground Truth로 삼아, 야구/골프 스윙에 대한 전문 분석 성능을 평가한다.
21% 정도의 Accuracy를 기록하였는데, 아직 운동 피드백 분석에 적극적으로 도입하기는 부족한 성능이라고 생각된다.
Evaluation on Mo-RepCount

Mo-RepCount 데이터 셋을 활용한 실험에서도 LLaMo가 좋은 성능을 보였다.
5. Conclusion
본 논문에서는 Motion 데이터를 LLM에 직접 통합하여 멀티모달 이해 능력을 향상시킨 LLaMo 모델을 제안한다. LLaMo는 텍스트, 비디오, 모션 데이터를 하나의 통합 구조 안에서 결합한 아키텍처로 설계되었으며, 그 결과 세밀한 모션 디테일을 포착할 수 있었으며, 전문 스포츠 분석과 같이 복잡한 인간 행동을 정확하게 해석할 수 있었다.
세 줄 요약
1. 모션 데이터를 언어로 변환하지 않고 원형 그대로 처리하여 LLM에 통합한 멀티모달 프레임워크 LLaMo를 제안함
2. Cross Talker와 Motion Enhancer를 통해 텍스트 맥락에 맞춰 중요한 모션 프레임을 선별하여 정밀한 행동 해석이 가능함
3. MoVidBench, BABEL-QA, Swing 등 다양한 모션관련 벤치마크에서 기존 모델 대비 높은 정확도를 보이며 멀티모달 행동 분석의 새로운 기준을 제시

'논문 paper 리뷰' 카테고리의 다른 글
| [Paper Review] Video-LLaVA 논문 이해하기 (0) | 2025.04.25 |
|---|---|
| [Paper Review] MotionLLM 논문 이해하기 (0) | 2025.04.18 |
| [Paper Review] MotionGPT 논문 이해하기 (0) | 2025.04.17 |




댓글