『Video-LLaVA: Learning United Visual Representation by Alignment Before Projection. EMNLP. 2024.』
이번에 소개할 논문은 Video-LLaVA 논문이다. 논문에서는 기존 다양한 Video-Image-Text를 같이 다루던 모델들이 Video-Text 만을 다루는 모델보다 성능이 낮다는 점을 지적하며, Image, Video의 Representation을 LLM에 넣기 전에 먼저 합치는 방법(Alignment)을 통해 LLM 모델이 비전 정보와 Text 정보를 잘 학습할 수 있도록 설계한 Video-LLaVA를 제안한다.
내가 연구하고자 하는 Motion에 대해서는 빠져있지만 Video 자체를 Input으로 받아 좋은 성능을 내고 있는 모델이기에(+Github 코드 공개) 자세히 그 방법론을 살펴보고자 한다.
Github
https://github.com/PKU-YuanGroup/Video-LLaVA
GitHub - PKU-YuanGroup/Video-LLaVA: 【EMNLP 2024🔥】Video-LLaVA: Learning United Visual Representation by Alignment Before P
【EMNLP 2024🔥】Video-LLaVA: Learning United Visual Representation by Alignment Before Projection - PKU-YuanGroup/Video-LLaVA
github.com
0. Abstract
Large Vision-Language Model(LVLM)은 다양한 Task에서 성능을 향상시켜왔다. 하지만 대부분의 기존 방법론들은 Image와 Video를 각각 다른 Feature Space에 인코딩한 후 LLM에 입력으로 넣기 때문에, 통합된 Tokenizing이 부족하여 LLM이 멀티모달의 상호작용을 잘 학습하기가 어렵다.
따라서 본 논문에서는 Visual Representation을 Language Feature Space로 통합하여 기존의 LLM을 통합된 LVLM으로 발전시키고자 하였다. 그 결과 Video-LLaVA 모델은 다양한 영상 데이터 셋 처리에 있어 좋은 성능을 보일 수 있었다.
1. Introduction
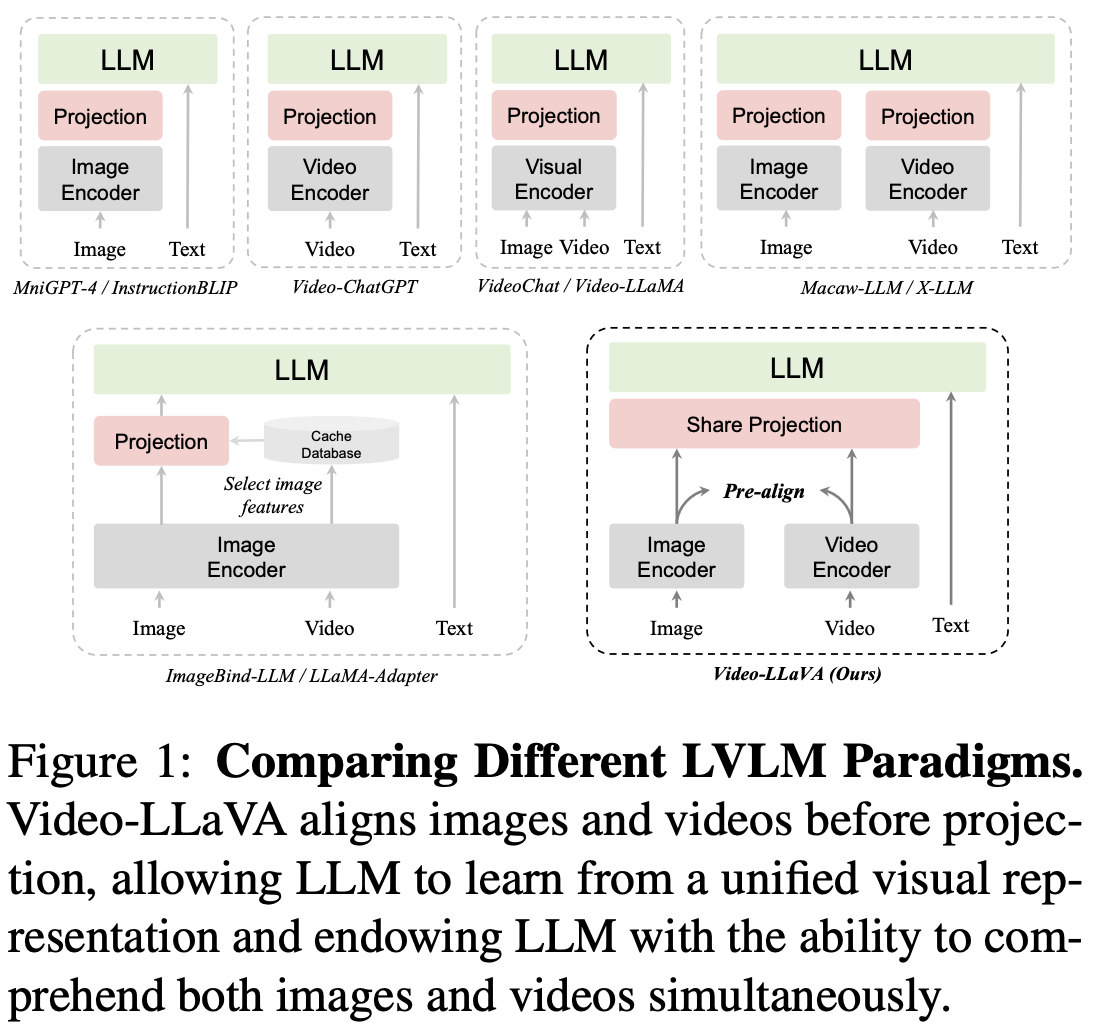
최근 LLM을 활용해 Image와 Text를 동시에 처리하고자 하는 연구들의 대다수는 Image를 Text Token 처럼 매핑하여 LLM에 입력으로 사용하고자 한다. 이 때 Image 대신 Video 정보를 결합하고자 하는 경우 단순 Image를 처리하는 것보다 더욱 어려운 Task가 되며, Figure 1을 참고하면 최근 Image, Video와 Text에 대해 어떻게 하면 정보를 잘 결합할 수 있을지에 대한 연구가 많이 이루어지는 것을 확인할 수 있다.
하지만, 아직까지 Video와 Image를 같이 입력으로 받는 모델들이 단일 Image 혹은 단일 Video modal에 대해서만 Input으로 받는 모델에 비해 성능이 떨어진다. 본 논문에서는 이를 Vision 정보에 대한 Projection을 진행하기 이전에 필요한 Alignment의 부재 때문이라고 말한다. Image와 Video Feature가 각각의 Space에 존재한다면 LLM 모델이 두 Feature 사이의 상호작용에 대해 잘 이해하지 못한다는 것이 본 논문의 주장이다.
따라서 본 논문에서는 Video-LLaVA라는 Image와 Video를 동시에 처리할 수 있는 강력한 LVLM 베이스라인을 제안하며, 그 특징은 다음과 같다.
- Image와 Video Representation을 하나의 통합된 Visual Representation으로 정렬
- 공유된 Projection Layer를 통해 이 통합된 특징을 LLM이 사용할 수 있도록 매핑
- 모델은 Image와 Video 데이터를 동시에 학습하며 단 1 Epoch 만으로도 뛰어난 성능을 달성
그 결과 앞서 지적한 단일 모달리티 전용 모델보다 뛰어난 성능을 보일 수 있었다.
정리해보면 결국 기존 LLM을 활용하여 이미지, 비디오, 텍스트를 이해하려고 했던 모델들이 이미지와 비디오에 대한 정보를 합치지 않은 상태로 LLM에 넣었기 때문에 성능이 그리 뛰어나지 않았다고 말하며, 본인들은 '두 정보를 먼저 합치고 모델에 넣었더니 성능이 올랐더라'고 말하고 있다.
2. Related Work
2.1. Large Language Models
최신 LLM 모델 간략 소개
2.2. Large Vision-Language Models
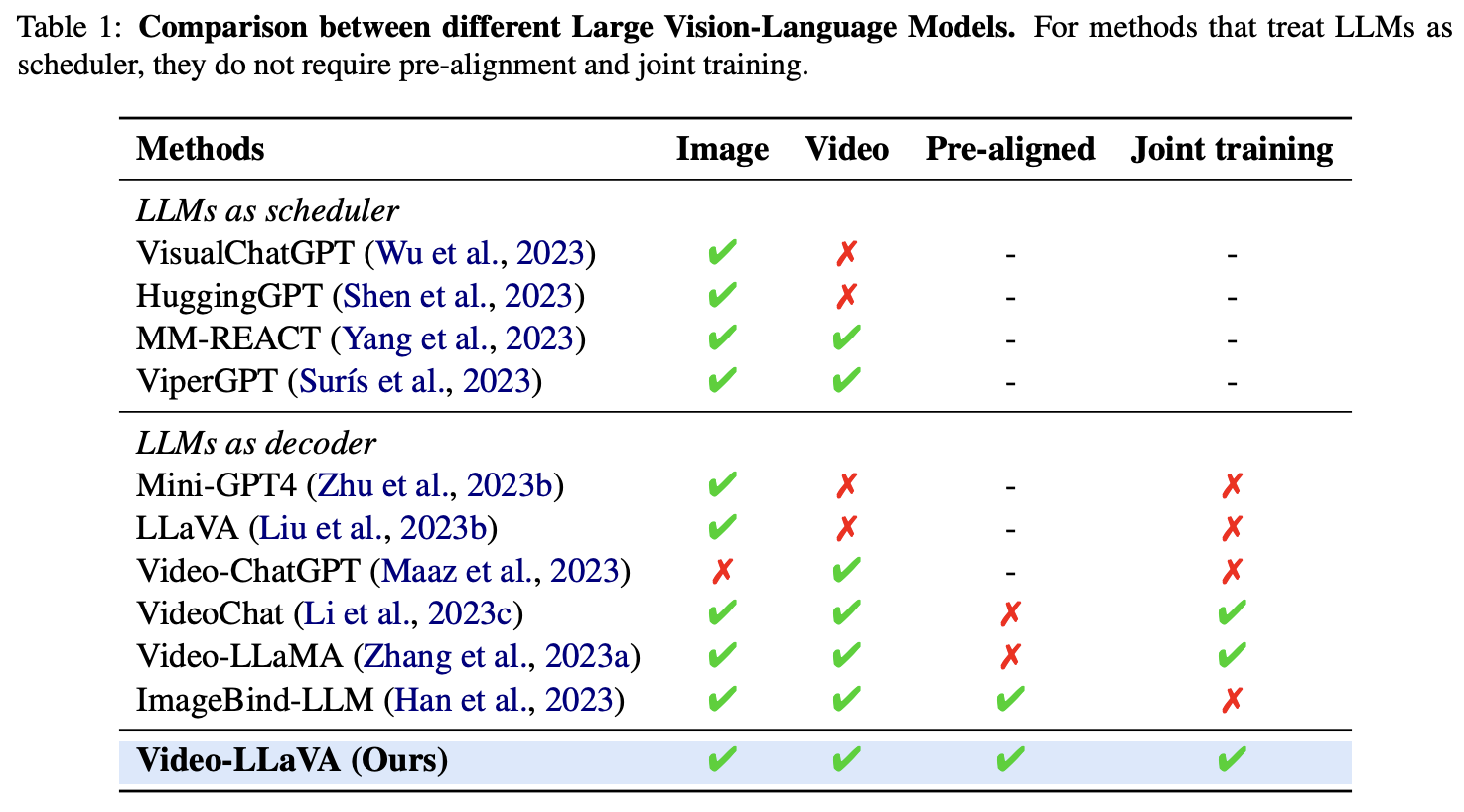
LLM을 멀티모달 처리로 확장할 때, 특히 Image와 Video를 함께 다루기 위한 접근 방식은 크게 두 가지로 나눌 수 있다(Table 1).
1) LLMs as scheduler
LLM이 작업 Scheduler처럼 활용되어 상황에 따라 다른 Visual Model을 조립하여 사용한다. 이 경우 End-to-End 학습이 필요하지 않고, 모달리티별 Pre-alignment나 Joint Training이 필요 없다는 장점을 가진다. 대신 모달 간의 깊은 Interaction은 어렵다.
2) LLMs as decoder
본 논문과 같이 LLM을 직접 이미지나 영상 정보를 이해하고 추론하는 중심 엔진으로 보는 접근 방식이다. Table 1에서 볼 수 있듯이 다양한 모델들이 기존에 존재하며(디테일한 정보는 논문을 참고) Video-LLaVA는 기존 모델들의 장점을 차용하여 다양한 모달리티를 공통된 이미지 공간으로 정렬(ex. LLaMA-Adapter, ImageBind-LLM)하고, Joint Training(ex. VideoChat, Video-LLaMA)을 통해 LLM이 더욱 향상된 멀티모달 추론을 할 수 있도록 돕는다.
3. Video-LLaVA
3.1. Model Structure

Framework Overview
Figure 2에 나타나 있는 것과 같이, Video-LLaVA는 다음의 구성요소로 이루어져 있다.
- Visual Encoder $f_V$: LanguageBind를 사용해 원본 Image 또는 Video에서 Feature 추출
- LLM $f_L$: Vicuna와 같은 모델로, Text와 Vision 정보를 종합하여 Response 생성
- Visual Projection Layer $f_P$: Visual Signal을 LLM이 이해할 수 있도록 Language Space에 맞게 변환
- Word Embedding Layer $f_T$: Text 입력을 처리하기 위한 Embedding Layer
모델의 전체 흐름은 다음과 같다.
- LanguageBind Encoder가 Image/Video에서 Feature 추출
- 추출된 Feature는 LanguageBind 내부에서 Textual Feature Space로 매핑되며 통합된 Visual Representation 생성
- 해당 Representation을 Shared Projection Layer에 통과시킴
- Projection된 Representation과 Word Embedding을 통과한 Text 입력을 같이 LLM에 입력함
- LLM은 입력을 기반으로 텍스트 기반의 Response를 생성
United Visual Representation
본 연구의 핵심 목표는 LLM이 하나의 통합된 Visual Representation에서 학습을 진행할 수 있도록 Image와 Video를 동일한 Shared Feature Space에 매핑하는 것이다.
예를 들어 "달리는 개"라는 개념은 (1) 언어로도 표현될 수 있고 (2) 한 장의 이미지로도 표현될 수 있으며 (3) 짧은 영상으로도 표현될 수 있다. 이처럼 같은 의미를 서로 다른 방식(Modality)으로 전달할 수 있다면, 이를 Common Feature Space에 압축할 수 있으며, 모델은 다양한 방식의 정보를 결합하여 활용할 수 있는 것이다.
이를 위해 Video-LLaVA에서는 LanguageBind Encoder를 사용하여, Image와 Video를 Textual Feature Space에 정렬한다.
Alignment Before Projection
LanguageBind는 OpenCLIP에서 시작된 모델로 OpenCLIP 모델은 Image와 Text를 동일한 Feature Space에 정렬하는 구조를 가지고 있다. LanguageBind 모델은 여기에 VIDAL-10M이라는 Video-Text 페어 데이터 셋을 사용하여 영상 또한 Text와 정렬될 수 있도록 학습을 진행하였다. 그 결과 Image와 Video가 모두 공통된 Language Feature Space에 정렬되어 통합된 Visual Representation을 생성할 수 있게 되었다.
어떤식으로 Image와 Video를 Textural Feature Space에 정렬하는지는 LanguageBind 논문을 참고하자.
3.2. Training Pipeline
Video-LLaVA의 Response 생성 과정은 GPT와 같은 LLM의 방식과 유사하다. 입력으로는 Textual Input $X_T$와 Visual Signal(Image/Video) $X_V$가 주어지고, 이들은 아래의 Equation에 따라 Token Sequence로 Encoding된다.
$$Z_T = f_T(X_T), \quad Z_V = f_P(f_V(X_V))$$
우선 입력에 대한 Encoding 과정부터 풀어서 설명하면, Text 입력의 경우 Text Embedding을 거쳐 $Z_T$ 텐서로 변환되고, Visual 입력의 경우 Feature를 추출하는 Encoder와 Language Space에 맞게 정렬하는 Projection Layer를 거쳐 $Z_V$ 텐서로 변환된다.
$$p(X_A|X_V, X_T) = \prod_{i=1}^{L}p_{\theta}(X_A^{[i]}|Z_V, Z_T^{[1:i-1]})$$
- $X_A$: 생성되는 Output Sequence
- $L$: 생성될 답변의 길이
- $\theta$: 학습 가능한 파라미터
Response 생성의 경우, 시각 정보 $Z_V$와 이전 토큰들 $Z_T^{[1:i-1]}$을 기반으로 다음 토큰 $X_A[i]$를 예측한다(MLE). 이 때 한 Batch에는 Image와 Video 샘플이 혼합되어 있어 모델이 두가지 Modality를 동시에 학습한다(Joint Training).
Understanding Training
이 단계에서는 모델이 기본적인 Visual Signal에 대한 해석 능력을 갖추도록 학습한다. 학습 데이터로는 Image/Video - Text 페어로 구성된 대규모 데이터 셋을 사용하며, 이 때 각 샘플은 하나의 대화 쌍(질문,응답)으로 구성된다$(X_q, X_a)$.
이 때 이전 단어들을 바탕으로 다음 단어를 예측하도록 하는 Auto-regressive loss를 사용하며, 학습시 Visual Understanding 능력 외의 파라미터는 Freeze한다.
Instruction Tuning
이 단계에서는 모델이 복잡한 Instruction을 이해하고 이에 맞는 Response를 생성하는 능력을 학습한다. 이 때 단순한 이미지 설명을 넘어 논리적 추론이나 상황 이해가 포함된 Task를 다루며, 여러 Round를 가지는 대화로 입력을 구성한다.
특히 2번째 Round 이후부터는 이전 질문과 응답을 이어붙여 입력으로 사용해 모델이 대화의 흐름을 파악하고 문맥을 이해할 수 있도록 설계하였다.

논문에 명확하게 나와있지는 않지만, 흐름상으로 이해해보자면 우선 Understanding Training 과정에서는 Visual Signal을 이해하기 위한 능력을 학습한다고 나와있으므로 나머지 Parameter는 Freeze한 채 Share Projection만을 학습하는 것 같고, Instruction Tuning 과정에서는 Share Projection + LLM 모델 두가지를 모두 학습하는 것으로 보인다.
4. Experiments
4.1. Experimental Setup
Data Details
Video-LLaVA는 앞서 소개한 2단계의 학습에 대해 서로 다른 데이터 셋을 사용한다.
1) Understanding Pretraining
[Image-Text]: 555,800쌍의 LAION-CC-SBU Image-Text 페어. 각 이미지에는 BLIP 캡션이 붙어있다.
[Video-Text]: WebVid 기반 데이터 셋, Valley에서 제공된 하위셋. 전체 703K 중 702K만 사용.
2) Instruction Tuning
[Image Instruction]: LLaVA 1.5에서 수집된 665,000쌍
[Video Instruction]: Video-ChatGPT의 100,000쌍
Model Setting
- LLM: Vicuna-7B-v1.5
- Visual Encoder: LanguageBind 기반
- Text Tokenizer: LLaMA with 32,000 class
- Shared Projection Layer: 2개의 FC Layer, GeLU 활성화함수

Training Details
- 모든 이미지는 224x224 크기로 resize&crop
- 각 영상에서 8 Frame을 균일하게 샘플링하고 각 Frame은 이미지와 동일하게 전처리
- 각 Batch에는 이미지와 영상이 랜덤하게 혼합
- Understanding Pretraining: 1 epoch, batch size 256
- Instruction Tuning: 1 epoch, batch size 128
- 자세한건 위 Table 7 참고
4.2. Quantitative Evaluation
Zero-shot Video Understanding

Video-LLaVA는 총 4개의 대표적인 Video QA 벤치마크에서 성능을 테스트 하였다. 평가 파이프라인은 Video-ChatGPT와 동일한 방식을 따랐다고 한다. Table 2에서 볼 수 있듯이 Video-LLaVA는 기존 모델들 대비 더 좋은 성능을 나타냈어, 이에 복잡한 영상 기반 질문에 대해 정확하고 문맥에 맞는 응답을 생성하는 것을 확인할 수 있었다.
Zero-shot Image Question-answering
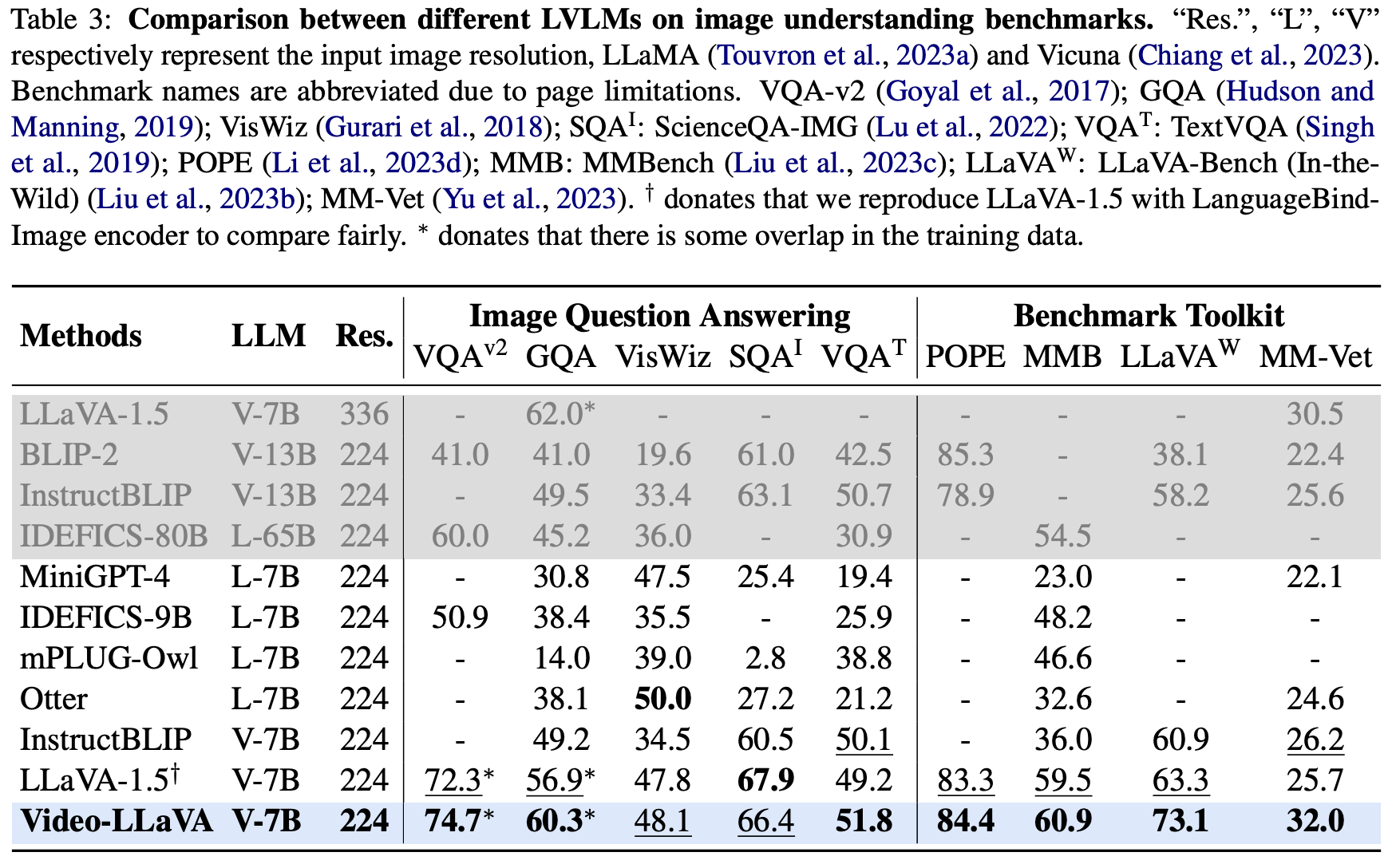
Image Understanding에 대해서도 최신 SOTA 모델인 InstructBLIP보다 우수한 성능을 보였다. 기존 LLaVA-1.5의 Image Encoder를 LanguageBind Encoder로 교체하였을 때의 성능또한 확인하여 Video-LLaVA의 우수한 성능이 단순히 더 강력한 Encoder를 사용하였기 때문이 아니라는 것을 실험적으로 입증하였다.
→ 통합된 Visual Representation을 LLM이 학습해 더 좋은 Response를 생성
Figure 3에 나타난 다른 Image Benchmark Toolkit에 대해서도 뛰어난 성능을 보였고, 이를 통해 Video-LLaVA가 이미지에 대해 자연어로 질문을 받았을 때 정확하고 문맥을 반영한 Response를 잘 생성한다는 것을 알 수 있다.
Object Hallucination Evaluation
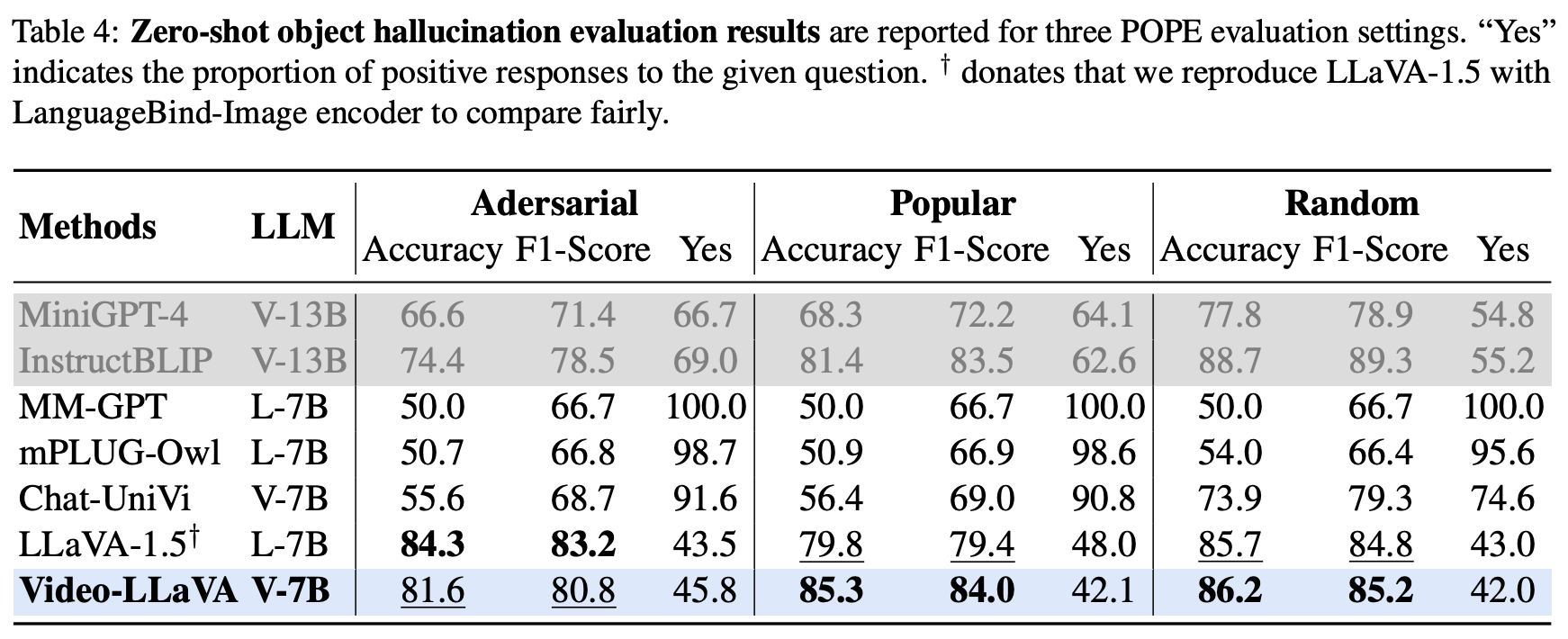
Table 4는 Video-LLaVA가 Zero-shot 조건에서 객체 환각 발생 여부에 대한 평가를 수행한 결과를 나타낸다. 평가방식은 POPE의 평가 기준을 활용하였다(Random: 임의 객체, Popular: 자주 등장하는 객체, Adversarial: 도전적인 객체).
그 결과 환각 억제 성능 또한 비교 모델 대비 우수한 성능을 보였으며 이는 통합된 Visual Representation과 Textual Description 생성이 잘 연결되어 있다고말하고 있다.
요약하자면 Video Understanding, Image Understanding, Visual Instruction Tuning, Object Halluciation에 대해 좋은 성능을 보였다.
4.3. Ablation Results
논문을 보면 소제목 구성에 오류가 존재한다. Alignment Before Projection / Joint Training 2가지로 구성되어 있는 것 같음
Alignment Before Projection
이번 Ablation 실험에서는 Visual Representation이 통합되지 않을 경우 LLM의 성능이 얼마나 떨어지는지를 검증한다. Separate Visual Representation의 Video Encoder로는 그대로 LanguageBind를 사용하였고, Image Encoder로는 MAE와 CLIP을 사용하였다.
1) For Video Understanding
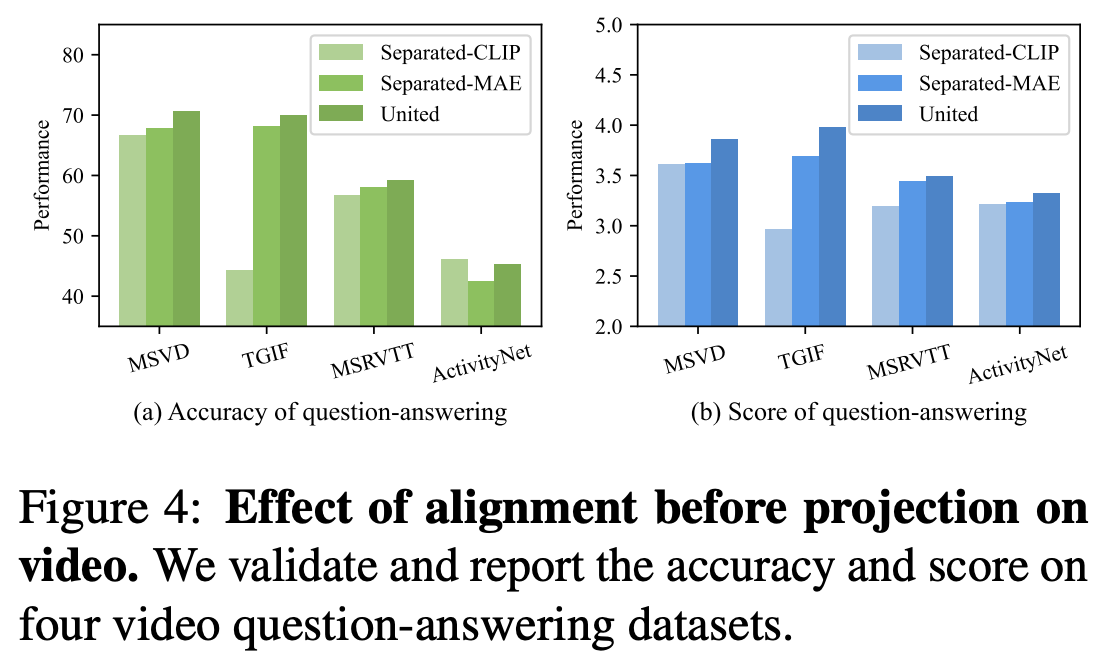
통합된 Visual Representation을 사용하였을 때, 모든 영상 관련 Benchmark에서 유의미하게 성능이 향상되었다.
2) For Image Understanding
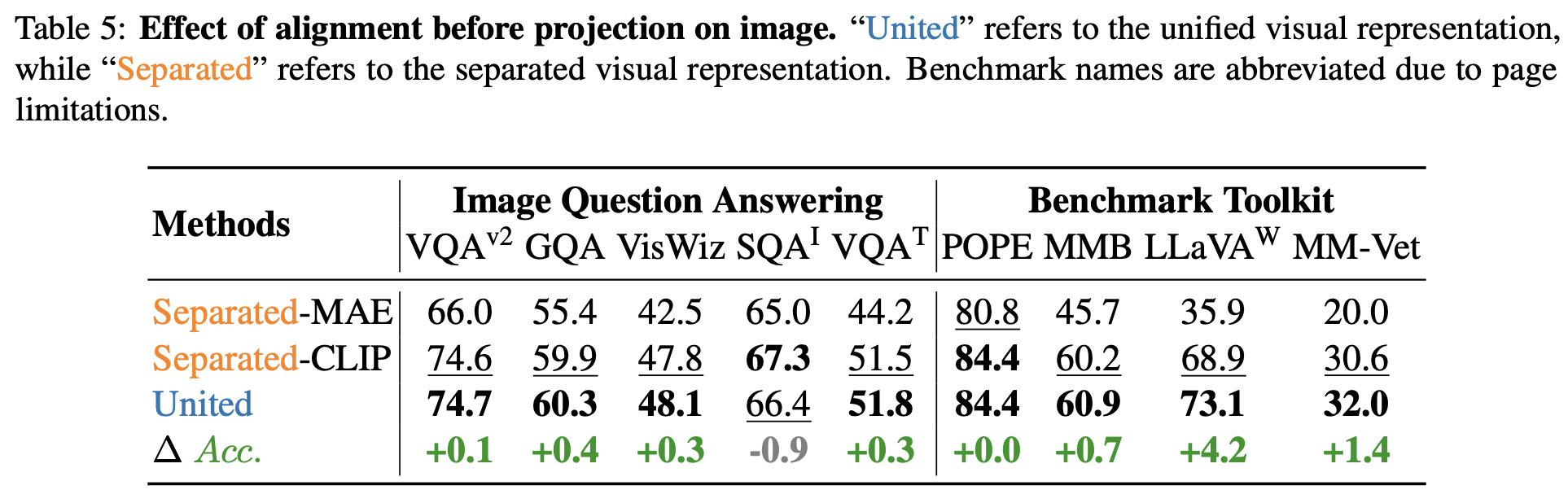
Image QA Benchmark와 Toolkit에서 모두 통합된 Visual Representation을 사용하였을 때의 성능이 높음
Joint Training
본 실험에서는 Image와 Video를 함께 학습했을 때 실제로 서로 상호보완적인 역할을 수행하는지 검증
1) For Video Understanding

Video-LLaVA*는 영상 데이터만으로 학습된 버전을 나타낸다. 영상과 이미지를 같이 학습하였을 때 성능이 더 좋은 것을 확인할 수 있다.
2) For Image Understanding

동일한 비교를 위해 LLaVA-1.5의 Image Encoder를 LanguageBind로 교체한 버전을 실험에 사용하였다. 그 결과 이미지만을 학습한 경우보다 SQA-IMG의 경우를 제외하고는 Video를 같이 학습한 경우가 Image Understanding에서도 좋은 성능을 낸 것을 확인할 수 있다.
결국 Ablation Study를 통해 Video,Image를 동시에 학습한 것과 두 모달간의 Alignment를 진행한 것이 실제 Video, Image Understanding 성능에 긍정적인 영향을 끼쳤다는 것을 확인할 수 있다.
5. Limitation and Future Directions
Limitation
- Long Video Understanding에 약함: Video-LLaVA는 영상 속 8개 Frame만을 균일 샘플링하여 사용했기 때문에 긴 영상의 세부 정보가 손실
- 학습 비용이 크다: 8개의 A100-80G GPU를 3~4일간 학습하였다.
Future Directions
- 더 효율적인 Shared Projection 방식 연구
- 다른 Visual Modality 확장(Depth, IR)
- 시간 정보 처리 능력 개선
6. Conclusion
본 논문에서는 Video-LLaVA라는 간단하면서도 강력한 Large Vision-Language Model 베이스라인을 소개하였다. Video와 Image 정보를 LanguageBind Encoder를 활용해 Textual Feature Space로 정렬하고, 통합된 Visual Representation을 통해 LLM으로 하여금 멀티모달 상호작용을 학습시켰다. 그 결과 Video, Image 두 모달에서 모두 성능이 향상되었으며 기존에 존재하는 각 모달 전용 모델보다도 더 강력한 성능을 나타냈다.
Video와 Image 정보를 같이 학습시키는 것이 Video Understanding, Image Understanding Task에서 모두 효과적인 성능 향상을 이루어낸다는 것을 증명해낸 논문이다. 코드도 전부 공개되어 있으며 텍스트를 활용한 멀티모달이 가능하기 때문에 모델을 조금 개량해서 사용하기에 충분히 활용성있는 모델이라고 생각한다. 최근에 관심있게 보고있는 분야이기에 조금씩 더 알아보고자 한다.
세 줄 요약
1. Video와 Image 정보를 통합하여 LLM 모델이 진정한 멀티모달 Understanding 능력을 갖추도록 설계한 Video-LLaVA 모델을 제안함
2. LanguageBind Encoder를 사용해 Video와 Image Feature를 통합하였으며, 2단계의 학습을 통해 Projection과 LLM 모델을 학습함
3. 실험 결과 Image와 Video를 같이 학습한 것과 두 모달간의 Alignment를 진행한 것이 실제 Understanding 성능에 유효한 영향을 미치는 것을 확인함(+ 코드 공개)

'논문 paper 리뷰' 카테고리의 다른 글
| [Paper Review] LLaMo 논문 이해하기 (0) | 2025.05.03 |
|---|---|
| [Paper Review] MotionLLM 논문 이해하기 (0) | 2025.04.18 |
| [Paper Review] MotionGPT 논문 이해하기 (0) | 2025.04.17 |




댓글