『MotionGPT: Human Motion as a Foreign Language. NeurIPS. 2023.』
앞으로는 내가 진행하고 싶은 Human Pose Estimation 관련 멀티모달 연구를 준비하기 위한 참고 문헌들을 많이 읽어보려 한다. 이번 논문 리뷰는 그 첫걸음으로써, 어떻게 하면 딥러닝 모델이 사람의 동작을 텍스트와 이미지 정보를 통틀어 잘 이해할 수 있는지를 다루고 있는 MotionGPT 논문을 정리해 보려 한다.
VLM 관련 연구들이 많이 이루어지고 있는 현재, 내가 하고자 하는 방향과 관련된 흥미로운 연구들이 계속해서 등장하고 있다.
Github
https://github.com/OpenMotionLab/MotionGPT?tab=readme-ov-file
GitHub - OpenMotionLab/MotionGPT: [NeurIPS 2023] MotionGPT: Human Motion as a Foreign Language, a unified motion-language genera
[NeurIPS 2023] MotionGPT: Human Motion as a Foreign Language, a unified motion-language generation model using LLMs - OpenMotionLab/MotionGPT
github.com
0. Abstract
LLM 모델은 계속해서 발전하고 있지만, 아직 언어와 Motion같이 다른 멀티모달 데이터를 통합하는 연구는 도전적으로 남아있다. 본 연구에서는 인간의 움직임이 언어와 유사한 Semantic을 가진다고 보고, 언어 데이터와 대규모의 모션 모델을 결합한다면 모션 관련 Task의 성능을 향상시킬 수 있는 Motion-Language Pretraining이 가능할 것이라고 말한다.
Motion-Language Pretraining을 수행하기 위해 양자화 기법을 활용하여 사람의 Motion을 Token 형태로 변경하고, 텍스트, Motion 정보를 통합한 언어 모델링을 수행하였다. 또한 Motion-Language Pretraining 과정 이후, Prompt Learning 방법론을 활용하여 QA Task에 대한 Fine-Tuning을 진행하였다.
그렇다면 Motion-Language Pretraining을 진행한 모델을 가지고 와 사용한다면, 특정 Motion에 대응되는 언어정보를 잘 파악하고 있다고 봐도 될까?
그렇다면, 내가 원하는 Motion과 Language 정보를 담은 데이터를 가지고 해당 모델을 학습시켰을 때, 해당 데이터에 잘 맞는 성능 좋은 모델이 생성될 수 있다고 예상할 수 있다.
MotionGPT 모델이 SOTA 성능을 보이는 Task 명은 다음과 같다.
- Text-driven Motion Generation, Motion Captioning, Motion Prediction, and Motion in-between
1. Introduction

LLM 모델의 발전과 함께 Language, Image, Mesh 등과 같이 멀티 모달 데이터와 모델링을 통합하는 연구가 많이 이루어지고 있다.
Prompt만으로 다양한 Motion Task를 지원할 수 있다면 게임, 로보틱스 등 다양한 분야에서 활용할 수 있다는 점 때문에 Human Motion과 Language를 아우르는 범용적인 Pretrain 모델이 필요하지만, 아직 Human Motion과 Language를 결합한 범용적인 Pretrain 모델은 존재하지 않는다.
최근 공개된 Text-to-motion 모델에는 MDM, MLD, MotionCLIP, TM2T 등이 있지만, 이 방식들은 Motion과 Language를 별도의 모달리티로 간주하기 때문에 쌍이 맞는 Motion-Text 데이터가 필요하다는 단점이 있다. 게다가 주로 Task-specific supervision을 사용하기 때문에 새로운 Task나 데이터에 일반화하기가 어렵다.
Q: Task-specific Supervision을 사용하게 되면 왜 일반화하기가 어려운가?
Task라는 것이 소분류로 다양하게 그 종류가 나뉘는 점에 주목해야 한다. Motion 관련 Task라고 하더라도 Motion Generation, Motion Captioning, Motion Prediction 등 다양한 Task가 존재하는데, Supervision을 사용하게 될 경우 이 이 Task에 대해 데이터를 각각 구축해야 하며, 한가지 Task에 대해 해당 데이터로 모델을 학습한다 한들 다른 Task에 대한 정보를 알지 못한다.
→ 학습 과정에서 언어와 모션 간의 일반적인 관계를 배우기보다는, “이런 문장 ➝ 이런 모션”이라는 대응만 외우게 된다.
따라서 본 논문에서는 다양한 Task에 일반화할 수 있으며, Motion-Language간의 상관관계를 잘 학습할 수 있는 Pre-trained 모델을 구축하는 것에 초점을 맞춘다. 이를 위해 주목해야 하는 부분은 두 가지이다.
- Language와 Motion간의 관계를 효과적으로 모델링 하는 것
- 새로운 Task에도 일반화가 가능한 Multi-task Framework를 구축하는 것
인간의 Motion이 Body Language로 해석되기도 하기 때문에 Semantic 정보를 지닌다는 점을 강조하며, 본 논문에서는 BEiT-3의 Vision-Language Pretraining 전략을 따라 인간의 Motion을 "외국어"로 간주하는 방식을 활용한다.
본 논문에서 제안하는 MotionGPT는 모델이 인간과 유사한 동작을 이해하고 생성할 수 있도록, VQ-VAE를 학습시켜 Motion Vocabulary를 구성한다. 이 Motion Vocabulary의 역할은 원시 Motion 데이터가 들어왔을 때, Motion Token Sequence로 변환하는 것이다. 이 Token들은 Pretrained LLM을 활용해 Pre-train되고, Motion 및 Instruction 데이터 셋으로 Fine-tuning하여 두 모달리티의 상관관계를 학습한다.

2. Related Work
Human Motion Synthesis
Human Motion Synthesis Task는 Text, Action, Incomplete motion 등 다양한 멀티모달 입력을 바탕으로 다양하고 사실적인 Human Motion을 생성하는 Task이다. 특히 Text-to-motion Task의 경우 가장 사용자 친화적이고 직관적이기 때문에 가장 주목받는 Motion Generation Task 중 하나이다.
언어를 사용해서 Motion을 생성하는 것을 User-friendly & Convenient language input 이라고 말하고 있다(장점). 추후 근거 문장으로 활용하기 좋을 것 같다.
Motion Generation 모델 예시
- MDM: Diffusion-based Generative model을 제안하며, 여러 Motion Task에 대해 개별적으로 학습
- MLD: Latent Diffusion Model을 확장하여 다양한 Conditional Input을 바탕으로 Motion을 생성
- T2M-GPT: VQ-VAE와 GPT기반의 생성 Framework를 고안하여 Motion Generation에 적용
이외에도 일부만 주어진 Motion에 기반하여 전체 Motion을 완성하는 Motion Completion Task도 존재한다. 하지만 이와 같이 Human Motion Task 안에도 다양한 Task가 존재하기에 본 논문에서는 하나의 단일 모델로 여러 Human Motion Task를 수행할 수 있는 모델을 만들고자 하였다.
그 방법으로는 Human Motion을 하나의 외국어로 간주하고, Pretrain된 언어 모델의 강력한 Text 생성 및 Zero-shot transfer 능력을 활용하는 통합적인 접근법을 제안한다.
Human Motion Captioning
Human Motion을 자연어로 설명하는 Task를 해결하기 위해 지난 방법론들은 통계모델, Recurrent Neural Network, 또는 Neural Translation Network를 사용하였지만 이들은 Text와 Motion간의 양방향 변환에만 초점을 맞추고 있어, 하나의 통합 Framework 내에서 다양한 Task를 수행하기에 한계가 있다.
Language Models and Multi-Modal
최근 LLM 모델이 발전하고 있으나 아직 Human Motion을 다룰 수 있는 Multi-modal Language model의 발전이 더디다는 내용
Motion Language Pre-training
기존 Text-to-motion 방법론들은 대부분 Caption을 입력으로 받아 Motion을 생성한다. 하지만 대부분의 이러한 방식들은 사용자 원하는 Instruction을 반영하여 유연하게 Motion을 생성하지 못한다. 주어진 입력에 대해 정해진 출력만을 생성하기에 실제 Motion Task에 본격적으로 적용되지 못하였고, 이에 본 논문에서는 자연어 모델과 인간의 Motion Task를 효과적으로 통합할 수 있는 MotionGPT 모델을 제안한다.
3. Method

본 논문에서는 대규모 언어 데이터와 사전학습된 언어 모델을 도입하기 위해 MotionGPT라는 Unified Motion-language Framework를 제안한다. Figure 2에서 볼 수 있듯이 Raw Motion Data를 Discrete Motion Token으로 변환하는 Motion Tokenizer와 사전학습된 언어 모델을 활용해 텍스트 설명과 함께 Motion Token의 의미를 학습하는 Motion-aware Language Model로 구성된다. 이 때 학습에 있어서는 Motion Tokenizer, Motion-language pre-training, Instruction tuning 3단계의 학습 절차를 따랐다.
처음에 등장하는 Motion Tokenizer는 Motion Encoder $\mathcal{E}$와 Motion Decoder $\mathcal{D}$로 구성되며, $M$개의 Frame으로 구성된 Motion Sequence $m^{1:M}={x^i}^M_{i=1}$를 L개의 Motion Token $z^{1:L}={z^i}^L_{i=1}, L=M/l$으로 인코딩한다. 이후 디코딩 과정을 통해 $z^{1:L}$을 Motion $\hat{m}^{1:M}$을 생성하며, 이 때 식은 $\mathcal{D}(z^{1:L})$ = \mathcal{D}(\mathcal{E}(m^{1:M}))$으로 나타난다. ($l$은 Motion Length에서의 Temporal Downsampling Rate)
이후 길이가 $N$인 문장 $w_{1:N}={w_i}^N_{i=1}$가 주어질 때, MotionGPT는 이에 대한 응답을 길이가 $L$인 Token Sequence $\hat{x}_{1:L}={\hat{x}_i}^L_{i=1}$를 생성하며, 이에 대한 형태는 다음과 같이 2가지로 나타날 수 있다.
- Motion Token $\hat{x}^{1:L}_m$ → Human Motion $\hat{m}^{1:M}$ 생성
- Text Token $\hat{x}^{1:L}_t$ → Motion Description $\hat{w}^{1:L}$ 생성
MotionGPT는 Human Motion Task에 대해 여러 Task를 한번에 다루기 위해 Output이 Motion과 Text, 2가지 형태로 출력될 수 있도록 설계하였구나!
3.1. Motion Tokenizer
Motion을 Discrete Token으로 표현하기 위해, 본 논문에서는 VQ-VAE 아키텍처를 기반으로하는 3D Human Motion Tokenizer $\mathcal{V}$를 Pretrain하였다.
Tokenizer는 Encoder $\mathcal{E}$, Decoder $mathcal{D}$로 구성되어 있다. Encoder는 시간축을 따라 1D Convolution을 적용하여 주어진 Motion Sequence로부터 Latent Vector $\hat{z}^{1:L} = \mathcal{E}(m^{1:M})$를 생성하며, 이후 Discrete Quantization을 통해 Token $z^{1:L}$로 변환한다.
학습 가능한 Codebook $Z = {z^i}^K_{i=1}$는 총 K개의 Latent Embedding Vector로 이루어져 있다. Quantization $Q(\dot)$는 각 행의 vector $\hat{z}^i$를 가장 가까운 Codebook Vector $z_k$로 대체하고, 이후 Decoder는 Quantization된 Vector Sequence $z^{1:L}$을 Raw Motion Sequence $\hat{m}^{1:M}$으로 복원한다.
Loss Function
3가지의 Loss Function으로 구성된다.
$$\mathcal{L}_V = \mathcal{L}_r + \mathcal{L}_e + \mathcal{L}_c$$
- $\mathcal{L}_r$: Reconstruction Loss
- $\mathcal{L}_e$: Embedding Loss
- $\mathcal{L}_c$: Commitment Loss
Loss의 구성은 VQ-VAE 모델과 유사한 것으로 보인다. 디테일한 내용은 VQ-VAE 논문을 참고하자.
여기에 더해, 생성된 Motion의 품질 향상을 위하여 L1 Smooth Loss와 Velocity Regularization을 Reconstruction Loss에 추가하고, EMA나 Codebook Reset 기술을 통해 Codebook 사용률을 개선하였다.
Q: VQ-VAE 모델 구조를 사용해서 얻는 장점?
Motion을 언어처럼 Discrete할 수 있다. 이를 통해 언어와 Motion의 Representation을 잘 통합할 수 있는 것!
결국 이 모델은 Motion 정보를 언어 Token과 비슷한 형태로 변경해서 LLM 모델에 같이 Input으로 집어넣고, LLM 모델이 Sequence에 담겨있는 Motion 정보를 잘 이해하기를 기대하는 것!!
3.2. Motion-aware Language Model
Motion Tokenizer를 통해 Motion Token Sequence $z^{1:L}$을 생성하였다면, 이제 언어 모델과 유사한 Vocabulary Embedding 공간에서의 표현이 가능해진다. 이러한 Unified Vocabulary를 활용함으로써 Motion과 Language를 동시에, 통합적으로 학습할 수 있다.
Motion Token $z^{1:L}$를 인덱스로 쪼개면 $s^{1:L} = {s_i}^L_{i=1}$로 표현할 수 있다. 기존 모델과 달리 MotionGPT는 Text와 Motion을 하나의 모델 안에서 통합적으로 모델링하는 것이 목표이기에, 다음의 Vocabulary를 합쳐 사용한다.
$$V_t = {v^i_t}^{K_t}_{i=1}$$
$$V_m = {v^i_m}^{K_m}_{i=1}$$
$$V = {V_t, V_m}$$
이러한 통합된 Vocabulary 기반에서는 Input Word와 Output Word가 모두 자연어나 Human Motion, 또는 그 조합으로 이루질 수 있어 MotionGPT는 다양한 Motion 관련 Output을 유연하게 만들어낼 수 있다.
조건부 생성 Task를 위해서는 T5 모델 구조를 기반으로 한 Transformer 모델을 사용한다. Input Sequence를 입력하면 Encoder를 통과하고, Decoder는 이전 시점까지 생성된 토큰과 Input Sequence를 바탕으로 다음에 올 Token의 확률 분포를 예측한다. 학습과정에서는 이 때 Log-likelihood를 최대화하는 것이 목표이다.
Inference 과정에서는 모델이 예측한 확률분포 $p_{\theta}(\hat{x}_t^i | \hat{x}_t^{<i}, x_s)$로부터 </s>와 같은 종료 토큰이 나올때까지 하나씩 Token을 반복적으로 샘플링한다. 이러한 Autoregressive Generation을 통해 MotionGPT는 입력 조건에 따라 단계적으로 자연어나 Motion, 또는 혼합 형태의 Sequence를 출력할 수 있다.
Figure 2의 T5 모델 도식에 나타나있는 Kencdec, Vencdec는 앞선 Language Encoder를 통과한 결과를 Key와 Value 형태로 변환했다고 이해하면 될 것 같다. Input Sequence가 Query의 역할을 수행할 것으로 예상. (확인 필요)
3.3. Training Strategy
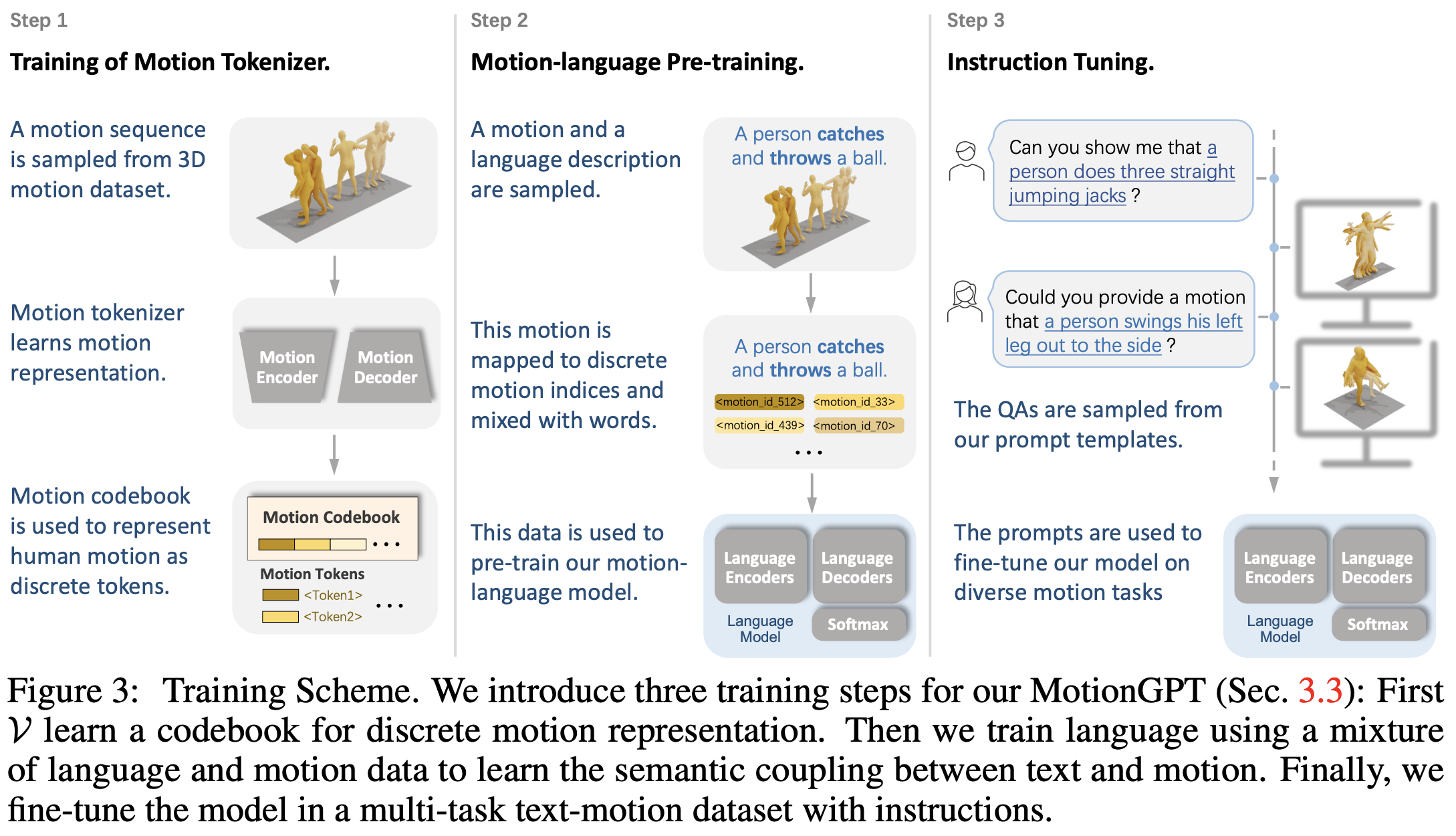
T5 모델은 본래 언어 데이터만을 대상으로 학습되어 왔기 때문에, 본 논문의 방법론을 통해 Motion과 Language간의 연결(Bridge)을 구축하고, 모델이 Human Motion의 개념을 이해할 수 있게 확장된다. Figure 3에서 볼 수 있듯이 MotionGPT의 학습 전략은 총 3단계로 구성된다.
1) Motion Tokenizer 학습
첫번째 단계는 Motion Tokenizer를 학습하는 것이다. 이 과정을 통해 Human Motion Sequence $\hat{x}^{1:L}$을 Discrete Motion Token Sequence로 표현할 수 있게 되어, Text 정보와 매끄러운 통합이 가능해진다.
한 번 학습이 이루어지면, 이후 단계부터 Motion Tokenizer는 학습되지 않는다.
2) Motion-Language Pre-training
T5 모델이 기본적으로 Instruction 기반의 자연어 데이터 셋으로 학습되기 때문에, MotionGPT에서는 언어와 Motion 데이터를 혼합하여 Unsupervised + Supervised 방식을 모두 활용한 Pretraining을 수행한다.
Unsupervised Learning (Masked Span Prediction)
- 입력 Sequence Token의 일정 비율(15%)을 특수한 Sentinel Token으로 무작위 교체
- 출력 Sequence는 교체된 Span을 추출해 구성하며, 같은 Sentinel Token으로 경계를 표시
- Sequence 안에는 Text 뿐만 아니라 Motion 정보도 들어있기 때문에 모델이 다양한 Task에 일반화될 수 있음
여기서 말하는 span은 입력 시퀀스에서 연속적으로 삭제(mask)된 토큰들의 구간을 의미한다. 단일 Token이 아니라 연속된 구간을 가려 문맥적인 구조나 의미 흐름을 더 잘 학습할 수 있도록 사용한다.
Supervised Learning (Motion-language Translation)
- Text-Motion Pair 데이터 셋을 활용
- 입력: Human Motion Sequence / Text Description
- 출력: 입력에 상응하는 Text / Human Motion
- Motion과 Text 간의 의미적인 관계를 학습
3) Instruction Tuning
- Text-Motion 데이터를 Instruction으로 정제하여 Multi-task 학습용 데이터 셋을 구성
- HumanML3D, KIT 등의 데이터 셋을 사용하고, 15개의 핵심 Motion Task를 정의(ex. Motion Generation with text, Motion Captioning, Motion Prediction 등)
- 각 Task마다 수십개의 Instruction Template을 생성
- 덕분에 Unseen Task나 새로운 Prompt에 대한 대응 능력 개선
(예시)
- Motion Generation: “Can you generate a motion sequence that depicts ‘a person emulates the motions of a waltz dance’?”
- Motion Captioning: “Provide an accurate caption describing the motion of <motion_tokens>”
4. Experiments
본 논문에서는 Text-to-Motion, Motion-to-Text, Motion Prediction, Motion in-between Task에 대한 평가를 진행하였다.
4.1. Experimental Setup
데이터 셋으로는 Text-to-Motion 데이터 셋에 초점을 맞추어, 텍스트 설명과 Motion Sequence를 가지고 있는 KIT, HumanML3D 데이터 셋을 사용하였다.
평가 Metric
1) Motion Quality
- FID(Frechet Inception Distance): 생성된 모션과 실제 모션간의 특징 분포 거리를 측정
- ADE(Average Displacement Error), FDE(Final Displacement Error): 모션 예측/보완 Task에서 예측 정확도를 평가
2) Generation Diversity
- DIV(Diversity): 다양한 Motion간 특징 분산으로 다양성을 측정
- MM(Multi-Modality): 동일한 텍스트 설명에 대한 모션 생성의 다양성을 평가
3) Text Matching
- R Precision: 텍스트와 모션의 Retrieval Accuracy 측정
- MM Dist(Multi-modal Distance): 텍스트와 모션 간 Distance 측정
4) Linguistic Quality
- BLEU, ROUGE, CIDEr, BERTScore 지표 사용
구체적인 Implementation Detail은 논문을 참고
4.2. Comparisons on Motion-relevant Tasks
Comparisions on Multiple Tasks

MotionGPT는 Human Motion을 외국어(논문에는 Foreign Language로 표현되어 있는데 그냥 Language로 이해해도 되지않을가?)처럼 간주하는 통합 프레임워크를 제시함으로써 다양한 Motion Task를 하나의 모델로 수행할 수 있도록 구성하였다.
본 논문에서는 220M 규모로 Pretrain된 Flan-T5-Base 모델을 Backbone으로 사용하여 이를 기반으로 Pre-training, Instruction Tuning을 진행하였다.
Table 2를 통해 본 논문이 해겨라고자 하는 핵심 Task들에 대한 실험 결과를 확인할 수 있다. MotionGPT는 기존 모델들과 달리 다양한 Motion Task를 수행할 수 있을뿐 아니라 그 성능 또한 훌륭하다는 점에 메리트를 가진다.
Comparisons on Text-to-Motion

Text-to-Motion Task는 주어진 텍스트에 따라 Human Motion Sequence를 생성하는 Task이다. Table 3을 통해 좋은 실험 성능을 낸 것을 확인할 수 있다.
Comparisons on Motion-to-Text

Motion-to-Text Task는 주어진 Human Motion에 대한 Description을 생성하는 Task이다. Table 4의 결과는 MotionGPT가 주어진 Motion을 잘 설명하고 있음을 나타낸다.
Comparison of Motion Prediction and In-between

Motion Prediction과 Motion In-between은 묶어서 Motion Completion Task로 평가할 수 있다. AMASS 데이터 셋으로 평가를 진행하였으며, Table 5를 통해 생성 품질이 좋은 것을 확인할 수 있다.
4.3. Ablation Studies

본 논문에서 Ablation Study를 진행한 부분은 모델 사이즈와 Instruction Tuning의 효과이다. 모델의 크기는 60M, 220M, 770M 모델을 기준으로 실험을 진행하였으며 기본 사이즈인 220M에 비해 크기가 작아질 때 성능이 확연히 떨어진반면 770M 모델이 거의 성능향상이 없었기에 220M 모델을 선택하였다. 본 논문에서는 이를 현재 사용 가능한 Motion 데이터 셋의 양이 적기 때문이라고 해석하였다.
Instruction Tuning의 경우 Motion Completion, Text-to-Motion Task에서는 성능을 향상시켰지만 Pure Text Generation Task에서는 성능을 다소 하락시키는 경향을 보였다. 이 또한 논문에서는 Motion과 Pair를 이루는 텍스트 설명 데이터 셋의 양이 적기 때문이라고 해석한다.
5. Discussion
MotionGPT는 언어 모델을 활용한 Human Motion Generation에서의 최초의 시도이지만, 관절 기반의 신체 Motion만을 대상으로 한다는 점(얼굴, 손, 동물 포함 X), 여러명이나 특정 객체 또는 환경과의 상호작용을 지원하지 않는다는 한계점을 가진다.
여기까지 다양한 Motion Task를 하나의 모델로 해결하고자 한 MotionGPT 모델에 대해 살펴보았다. 내 연구 주제와 관련하여 집중할만한 파트는 Motion-to-Text라고 생각하는데, 해당 Task에서도 좋은 성능을 낸 모델이기에 방법론에 주목해볼 필요가 있을 것 같다.
좀더 Motion-to-Text 파트에 집중해서 방법론 개선을 통해 성능을 끌어올린다면 실제로 사용할만한 성능이 나오지 않을까? 하는 기대를 가지고 있다.
세 줄 요약
1. Human Motion Task 안에도 다양하게 존재하는 세부 Task들을 하나의 모델로 해결할 수 있는 MotionGPT 모델을 제안함
2. VQ-VAE 모델 구조를 차용해 Human Motion을 Discrete Token으로 변경하여, Text와 같이 LLM의 Input으로 같이 사용되게끔 모델을 설계함
3. 3단계의 학습 방법으로 이루어져 있으며, 다양한 Human Motion Task에서 좋은 성능을 낼 수 있었다.

'논문 paper 리뷰' 카테고리의 다른 글
| [Paper Review] MotionLLM 논문 이해하기 (0) | 2025.04.18 |
|---|---|
| [Paper Review] InstructDiffusion 논문 이해하기 (1) | 2025.04.01 |
| [Paper Review] LLaVA 논문 이해하기 (0) | 2025.03.26 |




댓글