『Visual Instruction Tuning. NeurIPS. 2023.』
새로운 연구 주제를 잡기 위해 최신 방법론들을 두루두루 공부하는 중이다. 그 중 가장 내가 연구하고 싶은 멀티모달, 특히 VLM과 관련된 논문들을 읽어보려 한다. 그 중 처음으로 정리하게 된 논문은 LLaVA으로 2년만에 6천건이 넘는 인용수를 기록하고 있는, 최근 핫한 모델을 알아보려 한다.
"Vision Encoder + LLM"
한국인 교수님이 집필에 참여하신 점부터 컴팩트한 제목까지, 매력이 가득한 LLaVA 논문을 이해해보자 ☺️
https://github.com/haotian-liu/LLaVA
GitHub - haotian-liu/LLaVA: [NeurIPS'23 Oral] Visual Instruction Tuning (LLaVA) built towards GPT-4V level capabilities and beyo
[NeurIPS'23 Oral] Visual Instruction Tuning (LLaVA) built towards GPT-4V level capabilities and beyond. - haotian-liu/LLaVA
github.com
0. Abstract
LLM Task에서 주로 사용하는 Instruction Tuning을 진행하면, 일반적으로 새로운 작업에 대한 Zero-shot 능력이 향상된다. 하지만 이러한 연구는 아직 멀티모달 분야에서 많이 연구되지 않았고, 따라서 본 논문에서는 멀티모달 기반의 Instruction Tuning이 가능한 데이터와 함께 이 데이터를 가지고 학습한 LLaVA(Large Language and Vision Assistant) 모델을 제안한다. 이 모델은 Vision Encoder + LLM을 연결한 End-to-End 멀티모달 모델로 일반적인 시각 및 언어 이해 작업을 수행할 수 있다.
또한 본 논문에서는 Visual Instruction Following Task를 평가할 수 있는 2가지 평가용 벤치마크를 새롭게 구축하였으며, LLaVA 모델은 GPT-4 대비 상대적으로 높은 성능을 보였다.
※ LLM에서 주로 이루어지는 Instruction Tuning 예시
{
"instruction": "Summarize the following paragraph.",
"input": "Artificial Intelligence is transforming industries by enabling new forms of automation...",
"output": "AI enables automation across industries."
}
※ LLaVA에서 실행하고자 하는 Instruction Tuning 예시
{
"instruction": "What is shown in this image?",
"image": "<image_path_or_embedding>",
"output": "A cat is sitting on a wooden chair in a kitchen."
}
1. Introduction
지금까지 연구된 다양한 Vision Task들은 하나의 단일 Vision 모델이 특정 Task를 독립적으로 처리하며, Instruction은 암묵적으로 모델 설계에 반영되었다(예를 들면, 이 이미지 속에서 사람의 Bounding Box를 찾아라, Segmentation을 찾아라 등). 하지만 이 방법은 사용자의 지시에 대해 유연하게 반응하거나 상호작용하기 어렵다.
한편 LLM 모델에서는 언어가 General-purpose Assistant로써 다양한 작업의 지시를 명시적으로 표현할 수 있고, 지시한 작업을 모델이 수행할 수 있게 만들 수 있음을 보여주었다. 때문에 LLM Task에서는 LLaMA, Alpaca, Vicuna 등 다양한 모델들이 개발되었지만, 이들은 모두 Text-only 모델들이다.
따라서 본 논문에서는 이러한 Instruction Tuning의 개념을 Language-image 멀티모달 영역으로 확장하는 것을 시도하였다.
주요 Contribution
- ChatGPT/GPT-4를 활용하여 이미지-텍스트 쌍을 적절한 지시문 형식으로 재구성한 멀티모달 Instruction-following 데이터 셋 구축
- CLIP Vision Encoder + Vicuna LLM을 연결하고, 본 논문에서 구축한 데이터로 End-to-End 학습을 진행한 Large Multimodal(LMM) 모델을 개발
- 멀티모달 Instruction-following을 평가할 수 있는 벤치마크를 제안(LLaVA-Bench)
- 본 논문에서 구축한 데이터, 전체 코드, 학습한 모델 체크포인트를 오픈소스로 공개
2. Related Work
Multimodal Instruction-following Agents
컴퓨터 비전 분야에서 Instruction을 따르는 Agent를 구축하는 연구는 크게 2가지로 나눌 수 있다.
1) End-to-End 학습 기반 모델
- 사람의 자연어 지시를 이해하고 Visual 환경에서 일련의 행동을 수행해 목표를 달성
- ex. Image Editing: InstructPix2Pix와 같이 입력 이미지와 "무엇을 하라"는 텍스트가 주어졌을 때 해당 지시에 따라 이미지를 편집
2) LangChain/LLM 기반 다중 모델 조정 시스템
- 다양한 모델들을 LangChain 또는 LLM을 통해 조정하는 방식
- ex. Visual ChatGPT, X-GPT, VisProg 등
본 논문에서는 여러 Task에 대응 가능한 Language-Vision 기반 Multimodal 모델을 End-to-End 방식으로 학습하는 것에 집중(방법 1).
Instruction Tuning
NLP Task에서는 LLM이 사람의 자연어 지시를 따를 수 있도록 Instruction Tuning 기법이 연구되어왔다(ex. InstructGPT, ChatGPT). 따라서 이제 Vision Task에 Instruction Tuning이 적용되려 하는 것이 전혀 이상하지 않다!
Flamingo 모델은 멀티모달 Task에서 Zero-shot과 In-context Learning에서 강력한 성능을 보였으며, BLIP-2, FROMAGe 등 이미지-텍스트 쌍으로 학습된 주요 LMM 모델들이 존재한다. 하지만 이 모델들은 명시적으로 Vision-language instruct 데이터로 튜닝되지 않아 언어 전용 Task에 비해 성능이 부족한 경우가 많다.
따라서 본 논문에서는 이러한 성능 갭을 줄이기 위해 Vision Instruction Tuning의 효과를 체계적으로 분석하였다.
Vision Instruction Tuning ≠ Visual Prompt Tuning
Vision Instruction Tuning: 모델이 지시를 따르는 능력을 향상시키는 것
Visual Prompt Tuning: 모델 적용시의 파라미터 효율성을 높이는 것
3. GPT-assisted Visual Instruction Data Generation
최근 CC, LAION과 같은 Image-Text 멀티모달 데이터가 많이 공개되고 있지만, Multimodal Instruction-following 데이터 셋은 여전히 부족한 실정이다. 이는 사람이 수작업으로 데이터를 만드는 과정이 오래 걸리고 명확한 기준도 부족하기 때문인데, 본 논문에서는 최근 GPT 계열 모델들이 Text Annotation에서 큰 성과를 보인 것에서 착안하여 기존 Image-Text 데이터를 바탕으로 Multimodal Instruction-following 데이터를 생성하는 방법을 제안한다.
어떻게 보면 Multimodal Instruction-following 데이터 셋이 기존 VQA 데이터 셋과 비슷해보일 수 있다(내가 그렇게 생각했다). 하지만 그 디테일을 보면 다른점이 분명 존재한다.
Instruction-following 데이터를 학습한 모델은 당연히 VQA와 같은 문제도 해결할 수 있다.
VQA Multimodal Instruction Following 목표 이미지에 대한 정답을 맞히는 것 사용자의 지시를 이해하고 수행하는 Agent 질문 종류 대부분 명확한 정답이 존재하는 질문 질문, 요청, 요약 등 다양한 형태의 자연어 지시 정답 형태 대부분 짧은 단답형(ex. 숫자, 단어) 길고 유연한 응답(ex. 설명, 추론) 정답 유일성 명확한 정답이 존재 정답이 여러개일 수 있음 모델 기대 역량 시각적 사실 추출 + 질문 매칭 시각 이해 + 지시 해석 + 자연스러운 생성 예시 "고양이는 무슨 색이야?" → "하얀색" "이 이미지의 분위기를 설명해줘"
→ " 이 이미지는 차분하고 고요한 분위기야"
하나의 이미지 $X_v$와 이에 대응하는 캡션 $X_c$가 주어졌을 때, 해당 이미지를 설명하도록 도와주는 Question $X_q$를 생성하는 것은 자연스러운 접근이다. Instruction-followint Format을 어떤 식으로 구상할지 단순하게 생각해보면 다음과 같이 표현할 수 있을 것이다(이미지와 Question을 같이 줌).
Human: Xq Xv <STOP>
Assistant: Xc <STOP>하지만 이러한 방식은 만들기는 쉽더라도 Instruction과 Response 모두에서 깊이 있는 추론을 하기 어렵다는 단점을 가진다.

이에 본 논문에서는 Text만을 사용하는 GPT-4/ChatGPT를 Teacher 모델로 활용하였다. 이를 위해 2가지 Symbolic Representation을 사용하였는데, 첫번째는 다양한 시점에서 장면을 설명하는 텍스트를, 두번째로는 이미지 속의 객체의 위치(Bounding Box)와 개념을 표현하는 텍스트를 사용하였다.
본 논문에서는 COCO 이미지를 활용하여 다음의 3가지 유형의 Instruction-following 데이터를 생성하였다.
COCO 데이터 셋에 달려있는 Caption, Bounding Box 정보를 Prompt로 주고 GPT에 특정 Format으로 Output이 나오도록 Instruction을 주어 여러 Response Type 결과를 얻어냄
1. Conversation
- 이미지에 대해 사람이 질문하고 Assistant가 마치 이미지를 본 듯한 톤으로 대답
- 명확한 답이 있는 질문만 사용(VQA와 비슷)
- 질문 종류: 객체 종류, 수 세기, 행동 등
- 58,000장
2. Detailed Description
- 이미지를 풍부하게 설명하도록 유도하는 질문 리스트를 작성하게 함
- 각 이미지마다 질문을 하나씩 무작위로 뽑아 Detailed Description
- 23,000장
3. Complex Reasoning
- 단순한 이미지 설명이 아닌 논리적인 단계별로 추론이 필요한 질문
- 77,000장
LLaVA-Instruct 데이터 셋 예시
https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K
liuhaotian/LLaVA-Instruct-150K · Datasets at Hugging Face
[ { "from": "human", "value": "What aspects of a baseball game might require mental focus and strategy from players?\n<image>" }, { "from": "gpt", "value": "In a baseball game, there are multiple aspects that require mental focus and strategy from players.
huggingface.co
4. Visual Instruction Tuning
4.1. Architecture

본 논문의 목표는 LLM과 Vision 모델의 능력을 효과적으로 결합하는 것으로, Figure 1에 전체 네트워크 구조가 나타나있다. 사용한 Language Model은 Vicuna이며, 이 모델을 선택한 이유는 공개된 모델들 중 Instruction-following 성능이 가장 높기 때문이다(여기서 Vicuna 모델은 파라미터 $\phi$로 정의).
입력 이미지 $X_v$에 대한 Vision Encoder로는 Pretrain된 ViT-L/14 CLIP Vision Encoder를 사용하였고, 이미지로부터 시각적인 특징 $Z_v$를 추출한다.
시각적인 특징 $Z_v$를 추출했다면, 간단한 Linear Layer를 사용하여 $Z_v$를 Language Model의 Embedding 공간으로 변환하여 $H_v$로 매핑한다.
$$H_v = W\cdot Z_v, \quad with \quad Z_v = g(X_v)$$
이 때 학습 가능한 Projection matrix $W$를 사용하고, 함수 $g$는 Vision Encoder를 의미한다. 최종적으로 생성되는 $H_v$는 언어 모델이 이해할 수 있는 시각 토큰 시퀀스가 된다.
여기서 Vision Encoder를 통과해 나온 이미지 정보가 단순 Projection을 통해 시각 토큰으로 변환되기 때문에 매우 lightweight하며, 이에 데이터 중심 실험을 빠르게 반복할 수 있다는 장점이 있다.
물론 Flamingo의 Gated Cross-attention, BLIP-2의 Query Transformer와 같은 성능 좋은 Vision-language 연결 방식 또한 존재하지만, 이를 LLaVA에 적용하는 것은 추후 연구 과제로 남겨두었다.
한 줄 정리
LLaVA 모델은 CLIP으로 추출한 이미지 특징을 선형 변환을 통해 시각 토큰을 만들어 LLM(Vicuna)에 연결하는 방식으로, 간단하고 효율적인 구조를 가진다.
4.2. Training

우선 각 이미지 $X_v$에 대해 Multi-turn Conversation data($X_q^1, X_a^1, ... , X_q^T, X_a^T$)를 생성한다. 여기서 $T$는 전체 턴 수, $X_a$는 Assistant의 응답을 의미한다.
물어보고 응답하고, 물어보고 응답하고를 반복한 데이터
각 턴의 Instruction은 아래와 같이 정의된다.
$$X_{instruct}^t \left\{\begin{matrix} \text{Randomly choose} \ [X_q^1,X_v] \ \text{or} \ [X_v, X_q^1], \text{the first turn} \ t=1 \\ X_q^t, \qquad \text{the remaining turns} \ t>1 \end{matrix}\right.$$
Q: 굳이 왜 [질문, 이미지] or [이미지, 질문] 형태로 순서를 섞어 넣는걸까?
학습하는 모델이 LLM이라는 점에 집중할 필요가 있다. LLM은 아무래도 순차적인 구조로 앞쪽 정보에 더 집중하는 경향이 있다. 따라서 둘 중 하나의 형태로만 넣는다면 한 가지 정보의 영향력이 줄어들 수 있다. 때문에 순서를 랜덤하게 바꾸어 모델이 두 정보에 모두 고르게 Attention할 수 있도록 유도할 수 있다. 또한, 다른 패턴을 주어 모델로 하여금 입력의 구조 변화에 강건하게 만들어 순서에 과적합되지 않는 것을 방지한다.
물론 실제 활용에서 이미지가 먼저, 질문이 나중에 혹은 질문이 먼저, 이미지가 나중에 들어올 수 있으니 이를 모두 고려한 방식이라고 생각!
이를 바탕으로 LLM에 대해 기존의 Auto-regressive 방식을 유지하면서 예측 토큰에 대해 Instruction Tuning을 수행한다. 시퀀스의 길이가 $L$일 때, 정답 응답 $X_a$가 나올 확률은 다음과 같이 계산된다.
$$p(X_a|X_v, X_{instruct})=\prod_{i=1}^{L}p_{\theta}(x_i|X_v, X_{instruct,<i},X_{a,<i})$$
- $\theta$: 학습되는 파라미터(Projection Matrix $W$ or $W$ + 언어 모델 $\phi$)
- $X_{instruct,<i}$: 현재 예측 토큰 전까지의 지시문
- $X_{a,<i}$: 현재 예측 토큰 전까지의 정답 응답
- $x_i$: 현재 예측할 토큰
즉, 수식을 보면 LLM이 이전 Instruction + Response를 기반으로 다음 토큰을 생성하게끔 학습이 이루어지는 것을 알 수 있다(마치 RNN 모델처럼). 이 때 수식의 조건부 표현에 $X_v$를 포함시켜 모든 응답이 이미지에 기반하여 생성된다.
학습 절차는 총 2단계로 구성된다.
Stage 1. Pre-training for Feature Alignment
- CC3M 데이터 셋에서 필터링된 59.5만 개의 Image-Text 쌍
- Section 3에서 설명한 것처럼 GPT를 활용한 확장을 통해 Instruction-following 데이터 셋 형태로 변환
- LLM과 Vision Encoder의 가중치를 Freeze하고, 학습가능한 파라미터인 $\theta = W$만을 학습한다
→ LLM이 잘 이해할 수 있도록 Image Token을 생성하는 방법을 학습
Stage 2: Fine-tuning End-to-End
- 여기서도 Vision Encoder는 Freeze
- 대신 Projection Matrix $W$와 LLM의 $\phi$를 모두 학습($\theta = {W, \phi}$
사용한 시나리오 2가지
(1) Multimodal Chatbot
- Section 3에서 생성한 158K Instruction-following 데이터 셋으로 Fine-tuning을 진행
- 3가지 Response Type(Conversation: Multi-turn / Description & Reasoning: Single-turn)
- 학습 시 3가지 유형을 균등하게 샘플링
(2) Science QA
- ScienceQA 데이터 셋 활용(멀티모달 과학 질문 데이터 셋)
- Assistant는 자연어를 활용해 추론 과정을 설명하고 선택지 중 정답을 선택
- 전체를 Single-turn Conversation으로 구성하여 학습
- $X_{instruct}$: Question & Context
- $X_a$: Reasoning & Answer
5. Experiments
4.2 Section에서 설명한대로 본 논문에서는 멀티모달 챗봇과 ScienceQA 데이터 셋을 가지고 실험을 진행하였다. 8개의 A100 GPU를 사용하였으며 Vicuna의 하이퍼파라미터 설정을 따랐다.
Pretrain
4.2. Section Stage 1에서 소개된 것처럼 이미지 Feature를 LLM Embedding과 맞추는 작업을 선행하였다. 필터링된 CC-595K 이미지-텍스트 쌍 데이터를 사용하였고 1 Epoch과 LearningRate는 2x$10^{-3}$, BatchSize는 128로 진행하였다.
Fine-tuning
사용한 데이터는 본 논문에서 제안한 LLaVA-Instruct-158K 데이터 셋이며 3 Epoch, LearningRate 2x$10^{-5}$, BatchSize는 32로 진행하였다.
5.1. Multimodal Chatbot

본 연구에서는 LLaVA의 이미지 이해 및 대화 능력을 보여주기 위해 Chatbot 데모를 개발하였다. Table 3는 GPT-4 원본 논문에 수록된 예시들을 입력했을 때 GPT-4, BLIP-2, OpenFlamingo 모델이 어떤 응답을 하는지 나타낸 예시이다. LLaVA는 비교적 작은 규모의 멀티모달 Instruction 데이터로 학습되었음에도 GPT-4와 비슷한 성능을 보였다는 것이 핵심이며, 이 이미지는 LLaVA가 학습한 데이터에 있어 Out-of-Domain임에도 불구하고 LLaVA는 합리적인 응답을 생성하였다.
그에 반해 BLIP-2와 OpenFlamingo는 단순히 이미지를 설명하며 사용자의 Instruction을 따르지 못했다.
Quantitative Evaluation
본 연구에서는 모델의 Instruction-following 성능을 체계적으로 측정하기 위해 새로운 정량 평가 방식을 제안한다. GPT-4를 Judge로 활용하였으며, 이미지, 이미지에 대한 정답 설명, 질문 3가지 데이터를 우선 준비하였다.
LLaVA, BLIP-2, OpenFlamingo 모델에 대해 이미지와 질문이 Input으로 들어가면 적절한 응답을 생성하는 것을 목표로 하였고, GPT-4(Text only)가 질문 + 정답 설명(COCO Caption을 말하는듯)으로 생성한 응답을 정답으로 두었다.
평가는 Input으로 사용한 질문과 정답 설명, 각 모델의 응답을 GPT-4에 입력하여 GPT-4로 하여금 응답의 Helpfulness, Relevance, Accuracy, Level of Detail을 평가하고 이를 1~10의 점수와 함께 종합 평가 코멘트를 남기도록 하였다. 평가기준은 GPT-4(Text only)가 만든 응답을 이론적인 Upper Bound로 설정하고 다른 모델들의 점수는 이 기준 대비 상대적으로 평가하였다.
평가용 Prompt 예시
GPT를 사용해서 만들어본 Evaluation Template이다. 이렇게 평가를 진행하는 일이 LLM Task에서는 많고, LLaVA에서는 공개하지 않았지만 많은 LLM 논문에서는 Prompt를 공개하고 있다고...
솔직히 "평가 방법이 이게 말이 돼?" 라는 생각을 처음에 했지만, 기준이 일정하고 시간/비용이 적게 든다는 장점, 그리고 LLM이 정말 빠른 속도로 발전하고 있다는 것까지 생각하면 충분히 가능한 평가 방법이라고 여겨진다.
"""
You are a helpful and unbiased judge. Your task is to evaluate the quality of two assistant responses to a given user question and context.
[Context]
{Visual information in text form, i.e., image description}
[Question]
{The user's instruction or query}
[Response A]
{Model A's response}
[Response B]
{Model B's response}
Please compare the two responses in terms of:
- Helpfulness
- Relevance to the question
- Factual accuracy
- Level of detail
Then, give a score for each response from 1 to 10, and provide a short justification for your score.
Your output should be in the following format:
Response A Score: X
Response B Score: Y
Explanation: <your reasoning>
"""
LLaVA-Bench (COCO)

COCO-Val-2014 데이터에서 30개의 이미지를 무작위로 선택, 각 이미지에 대하여 3가지 유형의 질문을 생성하였다.
- Conversation
- Detailed Description
- Complex Reasoning
실험 결과(Table 4) Instruction Tuning을 진행하였을 때 성능이 50점 이상 향상되었고, 3가지 데이터 유형을 모두 포함하였을 때 가장 성능이 좋았던 것을 확인할 수 있다.
LLaVA-Bench (In-the-Wild)

보다 어려운 Task와 새로운 Domain에서의 일반화 능력을 평가하는 방식이다. 24개의 이미지에 대해 60개의 질문을 만들었으며, 특정 Meme이나 회화, 스케치 등을 포함해 수작업으로 작성된 고품질 설명과 적절한 질문이 작성되어 있다.
다른 모델의 성능과 비교한 결과(Table 5) 다른 모델들 대비 좋은 성능을 보였고, 특히 Complex Reasoing 질문에서는 GPT-4의 추론 성능과 비슷한 수준을 기록하였다.
Limitations
여긴 특이하게 Experiments에 Limitations 파트를 따로 두었다. 싫다는 것은 아니고 오히려 이 덕분에 논문이 더 잘 읽히게 되었다.

LLaVA-Bench (In-the-Wild) 데이터는 모델의 약점을 찾아내기 위해 어렵게 설계되었다. 따라서 Table 6에서 볼 수 있듯이 몇 가지 실패 사례들이 나타난 것을 확인할 수 있는데, 아직 일부 상식이나 고해상도 처리, 다국어 이해 등에서 한계가 존재한다고 본 논문에서는 판단하였다.
5.2. ScienceQA
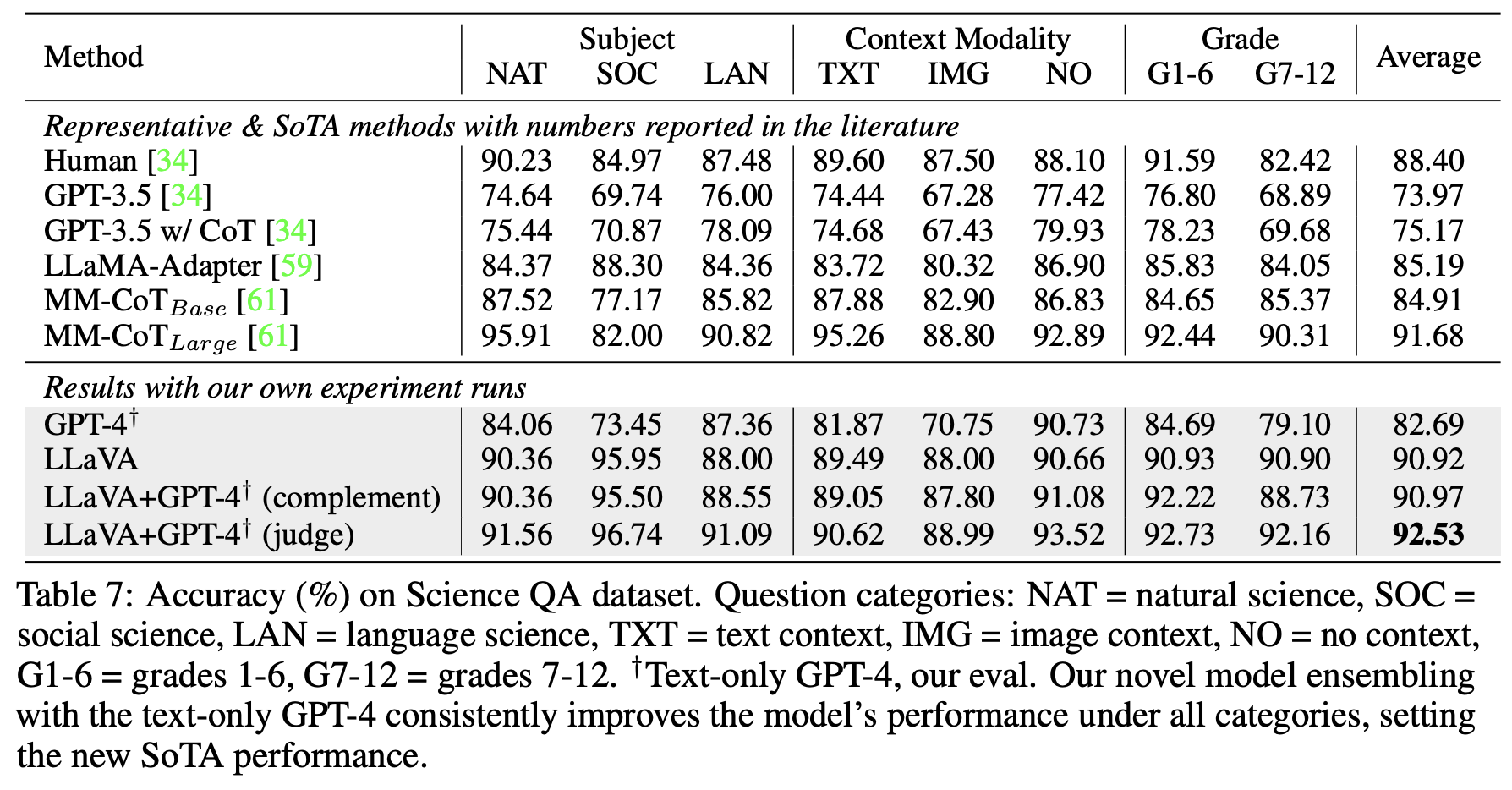
ScienceQA는 3개의 주요 과목에 대해 21,000개의 멀티모달 선택형 문제를 포함하는 벤치마크 데이터 셋이다. 평가 대상 모델로는 GPT 3.5, LLaMA-Adapter, Multimodal CoT(SOTA)를 사용했으며 그 결과는 Table 7에 나타나있다.
LLaVA 단일 모델로 테스트 했을 때에는 SOTA와 비슷한 90.92%의 정확도를 보였으며, GPT-4와 앙상블하였을 때는 더욱 좋은 성능을 내었다.
(GPT-4가 답을 하지 못할 때에는 LLaVA로 답을 수행(Complement), 둘이 다른 정답을 낼 경우 질문 + 두 모델의 응답을 다시 GPT-4에 입력하여 최종 정답 평가(Judge))
이건 온전히 GPT-4 모델의 성능이지 않나...? GPT-4와 MM-CoT를 앙상블 한 결과가 얼마인지를 모르기에 쉽게 좋은 방법이라 말하기 어려워 보인다.
Ablations

본 논문에서는 Visual Encdoer로 사용한 CLIP의 마지막 Layer Feature 대신 마지막 전 Layer를 사용하였는데, 이 때 성능이 0.96%p 차이가 났다. 그 이유는 마지막 Layer가 보다 Global 정보에 치우쳐 있고, 그 전단계는 Local Detail 파악에 유리하기 때문이다.
아무리 생각해도 %p가 맞는데 왜 %라고 기입이 되어있는건지 이해가 가지 않는다.
Chain-of-Thought의 순서에는 정답을 먼저 예측하든, 이유를 먼저 예측하든 크게 차이가 없어 최종 성능에 미치는 영향은 낮았다.
또한 Pretrain 과정 없이 바로 실험을 진행할 경우 5.11%p 만큼의 절대 성능이 감소하였고, 모델 크기에 따라서도 유의미한 성능 차이를 확인할 수 있었다.
ScienceQA Dataset
https://huggingface.co/datasets/derek-thomas/ScienceQA
6. Conclustion
본 논문에서는 Visual Instruction Tuning이 무엇인지 소개하고 그 효과를 보여주었다. Language-image 기반 Instruction-following 데이터를 생성하는 파이프라인을 제안하였으며, 이를 통해 Instruction을 이해하고 Visual Task를 수행할 수 있는 Multimodal 모델 LLaVA를 학습하였다. LLaVA 모델은 멀티모달 챗봇 데이터와 ScienceQA 데이터에 대해 모두 높은 성능을 보였으며, 멀티모달 Instruction-following을 평가할 수 있는 최초의 벤치마크까지 제안하였다.
본 논문에서는 이 논문을 시작으로 더 강력한 멀티모달 연구가 이루어지길 기대한다.
세 줄 요약
1. LLaVA는 GPT-4 기반 자동 생성 데이터로 학습된 멀티모달 Instruction-following 모델로, 이미지에 대한 Visual Instruction을 이해하고 수행할 수 있는 능력을 갖춤
2. 기존 LLM에서 이루어졌던 Instruction Tuning을 Vision 모델과 결합하였으며, CLIP Vision Encoder와 Vicuna LLM을 연결하여 모델이 이미지와 언어 간 정보를 효과적으로 통합하고 응답을 생성할 수 있도록 설계
3. Visual Instruction Tuning 모델을 평가할 수 있는 새로운 Benchmark를 제안하였으며, 멀티모달 챗봇과 ScienceQA 데이터에 대해 높은 성능을 보이며 새로운 SOTA를 기록함

'논문 paper 리뷰' 카테고리의 다른 글
| [Paper Review] InstructDiffusion 논문 이해하기 (1) | 2025.04.01 |
|---|---|
| [Paper Review] ViTAE 논문 이해하기 (0) | 2025.03.21 |
| [Paper Review] CMT 논문 이해하기 (0) | 2025.03.03 |




댓글