『ViTAE: Vision Transformer Advanced by Exploring Intrinsic Inductive Bias. NeurIPS. 2021.』
Vision Task에 Transformer 모델을 활용하는 방법을 공부하다 보면, 한 가지 궁금증이 생기게 된다.
본래 Transformer 모델은 NLP에서 온 Task이기에 공간 정보에 대해 자세히 학습하지 않는데, 그렇다면 CNN과 같은 Inductive Bias를 Transformer 모델에 주입할 경우 그 성능이 더 향상 될 수 있을까?
이번에 소개할 논문은 이러한 호기심을 해결하고자 연구를 진행한 논문으로, 어떻게 기존 ViT 모델에 CNN의 주요 특징을 반영하였는 지를 중심으로 논문을 이해해 보고자 한다.
이전에 논문 리뷰를 진행했던 CMT의 내용과 비교해가며 방법론을 파악해보면 좋을 것 같다.
https://rahites.tistory.com/373
[Paper Review] CMT 논문 이해하기
『CMT: Convolutional Neural Networks Meet Vision Transformers. CVPR. 2022.』이번에 소개할 논문은 Convolutional Neural Networks Meet Vision Transformers 이다. ViT의 등장 이후 기존의 CNN에 활용된 기술을 그대로 사장시키는
rahites.tistory.com
0. Abstract
Transformer 모델의 장점은 Long-range Dependency에 강하다는 것이다. 하지만 ViT는 1D sequence 형태를 띄기에 CNN과 달리 Intrinsic Inductive Bias가 약하다는 단점을 동시에 가진다. 따라서 본 논문에서는 CNN의 장점을 Transformer 모델에 적용한 ViTAE 모델을 제안한다. 이 모델은 몇 개의 Spatial Pyramid Reduction Module을 가지며 다수의 Convolution을 활용해 Multi-scale을 처리할 수 있도록 설계되었다.
1. Introduction
Transformer는 Self-attention을 사용하였기 때문에 Long-range Dependency에서 강한 면모를 보였다. 이를 Vision Task로 가져와 적용한 ViT 모델은 여러 Transformer Block을 사용해 이미지의 Global Dependency 정보를 잘 잡아 내었지만, 학습시간이 오래걸리고 많은 양의 학습 데이터가 필요하다는 단점을 가진다.
본 논문에서는 이러한 ViT의 단점이 2가지 문제에서 비롯된다고 말한다.
- Intrinsic Inductive Bias의 부족
- Various Scale을 다루기 어려움
역설적으로 ViT에게 필요한 위와 같은 능력들은, 기존 CNN이 이미 보유하고 있던 능력이다. CNN은 Locality와 Scale-invariance라는 Inductive Bias를 가지는데, Locality는 인근 pixel들의 관계를 분석함으로써, Scale-invariance는 여러 Layer를 가지는 계층적인 구조로써 이를 가능케 만들었다. 물론 CNN은 Long-range Dependency가 약하기 때문에, 본 논문에서는 Vision Transformer에 이러한 CNN의 장점을 녹이고 싶어 하였다.
최근 DeiT 논문에서 CNN의 지식을 Transformer 모델에 증류하여 성능을 개선하였지만, 이는 off-the-shelf CNN 모델이 필요하고 Training cost가 높다는 단점이 있다.
off-the-shelf
사전적 의미: 선반에 진열된 제품을 끄집어 내다
딥러닝적 의미: 사전 학습된 모델을 가져와 그대로 사용하다
따라서 본 논문에서는 DeiT와 다르게 ViT의 구조를 수정하여 Intrinsic Inductive Bias를 주입시키고자 한다. 본 논문에서 메인 비교 대상으로 잡은 모델은 T2T-ViT로, 이 모델은 Tokens-to-Token 변환 Layer를 활용해 Single-scale의 인근 Context 정보를 집계하고, 이미지를 토큰으로 구조화하는 방식을 사용한다.
본 논문에서 탐구한 방법
1. Scale-invariance Inductive Bias를 얻기 위해
- 각기 다른 Receptive Fields를 가진 Intra-layer Convolution을 활용하여 Token에 Multi-scale Context를 포함시킴
2. Locality를 얻기 위해
- Transformer는 Local 특징을 파악하기 어렵기 때문에 Convolution Layer와 Attention Layer를 순차적으로 쌓아올리는 구조로 구성
- 또한 직렬적인 구조는 Locality를 모델링 하는 동안 Global Context를 놓칠 수 있으므로, Locality와 Long-range Dependency를 병렬로 구성하고 Fusion하는 구조로 설계
위와 같은 방법론을 적용시켜 본 논문에서는 ViTAE(Vision Transformers Advanced by Exploring Intrinsic Inductive Bias)라는 새로운 Vision Transformer 구조를 제안한다.
ViTAE의 핵심 구조
1. Reduction Cell(RC)
- 입력 이미지를 다운샘플링하고 Multi-scale Context를 포함한 Token을 생성(Pyramid Reduction Module 사용)
- Atrous Convolution을 사용하여 다양한 Receptive Field를 포함
2. Normal Cell(NC)
- Locality와 Global Dependency를 동시에 모델링
- Attention 모듈과 Convolution Layer를 병렬로 구성하고 FFN을 뒤에 붙임
ViTAE는 위의 두가지 기본 Cell을 결합한 형태이며, 데이터 및 학습 효율성, 분류 정확도 및 Downstream Task에서 좋은 성능을 보였다.
주요 Contribution은 다음과 같다.
- Transformer 모델에 Scale-invariance, Locality 2가지 Intrinsic Inductive Bias를 적용시키는 방법을 제시
- 새로운 아키텍처인 ViTAE를 설계하였고 RC, NC의 결합으로 Multi-scale Context를 포함하고 Locality와 Long-rage Dependency를 동시에 학습할 수 있도록 구성
- 기존 ViT 모델 대비 성능이 우수함
2. Related Work
2.1. CNNs with intrinsic IB
CNN은 Locality와 Scale-invariance라는 Inductive Bias를 가진다. 우선 Locality의 경우 인접한 pixel들이 서로 강한 연관성을 가질 가능성이 높다는 개념을 바탕으로 하며, Scale-invariance의 경우 Multi-scale Feature를 학습하는 것을 의미한다. Multi-scale feature를 잘 잡아내기 위해서 전통적으로 사용되는 방법은 Image Pyramid 기법이다. 여기서는 여러 해상도의 Image Pyramid를 생성하고 각 해상도에서 Feature를 찾아내는데, 이 때 낮은 해상도에서는 큰 객체의 Feature를, 높은 해상도에서는 작은 객체의 Feature를 더 잘 포착해 낸다.
Multi-scale Feature를 잘 학습하는 또 다른 방법은 Single Layer 안에서 다양한 Receptive Field를 가진 다중 Convolution을 사용하는 것이다. 이는 Intra-layer Fusion이라고 부르며, 본 논문에서는 이러한 Intra-layer Fusion을 Reduction Cell에 도입해 다양한 Dilation Rate를 가진 Convolution을 통해 Multi-scale Context를 가질 수 있도록 설계하였다.
Inter-layer Fusion: 서로 다른 Layer 간의 Multi-scale Feature 결합(ex. HRNet)
Intra-layer Fusion: 단일 Layer 안에서 다양한 크기의 Convolution을 사용해 Multi-scale Feature 결합
2.2. Vision Transformers with learned IB
ViT는 Local Visual Structure를 모델링하는 본질적인 Inductive Bias가 부족하기 때문에 대규모 데이터를 학습에 사용하여야 한다는 문제점을 가진다. 따라서 ViT의 등장 이후 연구는 2가지 방향으로 발전 하였는데, 우선 첫번째는 Inductive Bias를 최소화 한 상태에서 대규모 데이터로 학습하는 방법, 두번째는 CNN이 가지고 있는 Inductive Bias를 Transformer 모델 학습에 활용하는 방법이다. 대표적인 예시로 DeiT의 CNN to Transformer Distillation을 활용한 방법이 있다.
하지만, 최근에는 Transformer 구조 자체에 CNN의 본질적인 Inductive Bias를 통합하려는 연구가 이루어지고 있다. 본 논문 또한 이와 같은 연구의 일종이며, Divide-and-Conquer 전략에 기반해 Locality + Global Dependency feature를 병렬 방식으로 모델링하는 새로운 구조를 제안한다.
기존 모델 중 가장 관련성이 높은 모델은 Conformer이며, 본 논문에서는 기존 Conformer 모델보다 ViTAE가 Intrinsic Inductive Bias를 포함하도록 설계하였다고 말하고 있다.
3. Methodology

3.1. Revisit Vision Transformer
이 파트에서는 ViT에 대한 간략한 리뷰를 진행한다. ViT 모델은 입력 이미지에 대해 Height, Width, Channel을 지정된 비율로 축소하여 Token으로 변환하고, 여기에 Class Token과 Position Embedding을 추가한 후 Transformer Layer로 전달한다. Transformer Layer는 MHSA(Multi-Head Self-Attention)과 FFN(Feed Forward Network) 블록으로 구성된다.
3.2. Overview Architecture of ViTAE
ViTAE의 핵심 목표는 CNN에 존재하는 Intrinsic Inductive Bias를 ViT에 적용하는 것이다. 이를 위해 ViTAE는 RC(Reduction Cell)과 NC(Normal Cell)을 사용하며, RC는 Token 안에 있는 Multi-scale Context 정보와 Local 정보를 효과적으로 임베딩하는 역할을, NC는 RC에서 출력된 Token을 Flat한 후 Class Token 연결, Position Encoding을 수행하여 Token의 길이는 유지한 채 지역적인 특성과 Long Range Dependency를 함께 모델링한다.
3.3. Reduction Cell
기존 ViT에서는 이미지를 Linear하게 Patch로 나눈 후 Flat하여 Token을 만들었다. 대신 ViTAE에서는 Multi-scale Context와 Local Information을 포함하는 RC를 사용한다. 때문에 CNN에서 가지는 Scale-invariance와 Locality IB를 ViTAE에 도입할 수 있다. RC는 Global Dependency 모델링, Local Context 추출, FFN으로 구성되어있다.
(1) Global Dependency Branch
- Pyramid Reduction Module(PRM)을 사용해 Multi-scale Context 정보를 추출
- 이후 구한 Feature map을 MHSA에 입력
(2) Parallel Convolutional Module(PCM)
- PCM 모듈을 활용해 Local Context 정보를 학습
ViTAE에서는 3개의 RC를 순차적으로 연결하였으며, 각 Cell에 들어가는 입력 이미지는 각각 1/4, 1/2, 1/2 만큼 작아진다.
3.4. Normal Cell
NC는 RC와 유사한 구조를 띄지만 NC에는 PRM이 생략되어 있다. 그 이유는 RC에서 이미 해상도가 많이 작아져(1/16) Multi-scale 정보를 위한 추가적인 다운샘플링이 불필요해졌기 때문이다.
NC의 수행과정은 다음과 같다.
(1) 마지막 RC에서 출력된 Feature에 Class Token을 연결
(2) Position Encoding을 더하여 입력 시퀀스 $t$를 생성
(3) $t$을 MHSA로 입력해 전역 정보를 학습
(4) 위와 동시에 $t$를 2D Feature Map 형태로 변환한 후 PCM에 입력
- 이 때 PCM은 공간정보를 가지지 않기 때문에 Class Token 사용 X
- 파라미터 수 감소를 위해 Group Convolution을 사용
(5) NHSA와 PCM의 출력을 Element-wise 합으로 Feature 정보를 융합
(6) 이후 FFN을 통과하여 NC의 출력을 생성
(7) 최종 분류 단계에서는 ViT와 유사하게 마지막 NC에서 생성된 Class Token에 Layer Normalization을 적용한 후 Classification Head에 입력하여 최종 예측 결과를 산출
3.5. Model Details

실험에 사용한 ViTAE 모델의 구성은 Table 1과 같다. 구체적인 내용은 논문을 참고.
4. Experiments
4.1. Implementation Details
- ImageNet 데이터 셋을 활용하여 평가
- 자세한 사항은 논문 참고
4.2. Comparison with the state-of-the-art
- Parameter 수가 유사한 CNN, Transformer 모델 성능과 비교
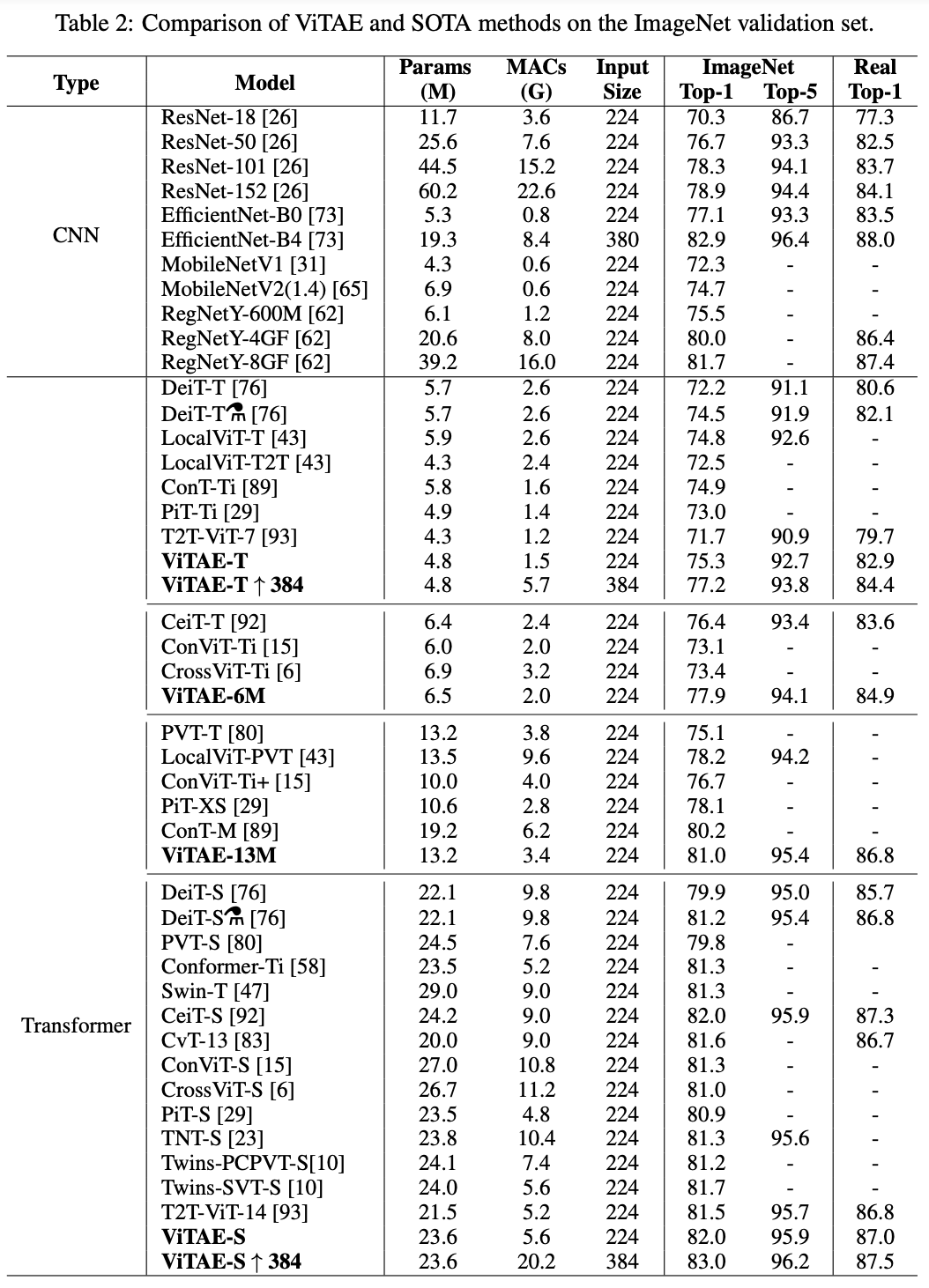
ViTAE-T: ResNet-18보다 더 적은 파라미터로 더 높은 정확도, 입력 해상도를 키울 경우 Resnet-50과 비슷한 성능
ViTAE-S: ResNet-101/152보다 파라미터 수는 절반이지만 정확도는 비슷. 입력 해상도를 키울경우 SOTA와 대등
뿐만 아니라 ViTAE는 ViT 계열의 모델보다 더 적은 파라미터로 더 나은 성능을 보여 Intrinsic Inductive Bias를 아키텍처 안에 도입하는 것이 효과적임을 입증하였다.
4.3. Ablation study

ViTAE 모델의 주요 구성 요소들이 실제 성능에 기여하는 지를 파악. 베이스는 T2T-ViT.
모든 NC 변형 모델이 T2T-ViT 모델보다 높은 성능을 보였으며, 특히 PCM+MHSA Fusion+BN 기법을 적용하였을 때의 성능이 가장 좋았다. RC에서 활용한 Dilation의 경우 너무 큰 Dilation을 사용하기 보다는 Layer의 싶이에 따라 Dilation rate를 점차 줄이는 전략을 활용하여 좋은 성능을 낼 수 있었다.
4.4. Data efficiency and training efficiency
Intrinsic Inductive Bias가 Data/Train Efficiency에 주는 효과를 검증.

데이터 양을 다르게 한 실험(ImageNet 데이터 20%/60%/100%)과 Epoch 수를 다르게 한 실험(100/200/300)을 수행하였고, 모든 실험 조건에서 T2T-ViT 모델보다 좋은 성능을 보였다.

또한 상대적으로 ImageNet보다 작은 Cifar 데이터 셋에서도 실험을 진행하였다. 더 적은 파라미터를 가지고, 기존 DeiT 모델보다 1/7에 가까운 Epoch 수로 더 나은 성능을 달성한 것을 확인할 수 있다.
4.5. Generalization on downstream tasks

뿐만 아니라 다른 Downstream Task에서도 좋은 성능을 보였다.
4.6. Visual inspection of ViTAE


ViTAE의 내부 매커니즘 확인을 위해 평균 Attention 거리와 Grad-CAM 시각화를 진행하였다. Figure 3를 통해 ViTAE가 더 얕은 Layer에서도 더 넓은 관계를 학습할 수 있다는 것을 알 수 있고, Grad-CAM 시각화를 통해 더 정확하게 객체에 Attention하는 것을 확인할 수 있다.
5. Limitation and discussion
한계: 계산 자원의 한계로 ViTAE 모델을 대규모로 확장하지 못함(ImageNet-21K와 같은 대규모 데이터 사용 X).
향후 연구 방향: Intrinsic Inductive Bias 외에도 Viewpoint invariance와 같은 편향들도 추가할 계획
6. Conclusion
본 논문에서는 Transformer Block을 재설계하여 Reduction Cell, Normal Cell을 제안하고 이를 통해 CNN에서 가지고 있던 Locality, Scale-invariance라는 Inductive Bias를 주입하였다. 그 결과 기존 모델 대비 파라미터 수가 적고 성능이 높은 ViTAE라는 아키텍처를 개발하였다.
세 줄 요약
1. CNN 모델이 가지는 Locality와 Scale-invariance라는 Intrinsic Inductive Bias를 Transformer 구조에 통합한 ViTAE 모델을 제안
2. Reduction Cell과 Normal Cell을 활용하여 전역적인 정보과 지역적인 정보를 효율적으로 학습하도록 설계
3. 기존 CNN, Transformer 기반 모델 대비 파라미터 수가 적고 적은 데이터와 짧은 학습시간만으로도 더 좋은 성능을 보임

'논문 paper 리뷰' 카테고리의 다른 글
| [Paper Review] LLaVA 논문 이해하기 (0) | 2025.03.26 |
|---|---|
| [Paper Review] CMT 논문 이해하기 (0) | 2025.03.03 |
| [Paper Review] Titans 논문 이해하기 (0) | 2025.02.26 |




댓글