『InstructDiffusion: A Generalist Modeling Interface for Vision Tasks. CVPR. 2024.』
이 논문의 목적은 "사람의 지시에 따라 모든 Vision Task를 수행할 수 있는 모델 개발"이다. 그렇기에 이 논문의 내용은 내가 최종적으로 추구하는 딥러닝 연구분야와 결이 같다.
"어떻게 하면 사람이 원하는 걸 모델이 정확히 이해하고, 사용자의 요구를 '알잘딱깔센'하게 수행하게 만들 수 있을까?"라는 질문에 대한 해답에 힌트가 되는 Multimodal 연구 중 하나라고 생각하며, 이번 논문을 읽으며 나에게도 내가 하고자 하는 연구의 방향성을 조금 더 좁힐 수 있는 계기가 되었다. 이번 논문 리뷰는 내가 가장 알고 싶은 Pose(본 논문에서는 Keypoint Detection) 위주로 읽어보려 한다.
인간의 Instruction을 이해하는 Multimodal 모델이 완벽히 완성되기 전에, 나도 얼른 관련 기술들을 습득해서 뒤처지지 않고자 한다.
Github
https://github.com/cientgu/InstructDiffusion
GitHub - cientgu/InstructDiffusion: PyTorch implementation of InstructDiffusion, a unifying and generic framework for aligning c
PyTorch implementation of InstructDiffusion, a unifying and generic framework for aligning computer vision tasks with human instructions. - cientgu/InstructDiffusion
github.com
0. Abstract
본 논문에서는 컴퓨터 비전 Task를 인간의 Instruction에 맞게 수행하는 통합적이고 범용적인 Framework인 InstuctDiffusion을 제안한다. 기존 Vision Task들은 각 Task마다 필요한 Prior knowledge나 Output space가 달라 이를 미리 정의해야 했지만, 본 논문은 Diffusion Process를 기반으로 유연하고 상호작용이 가능한 Pixel Space를 출력 공간으로 사용함으로써, 다양한 Vision Task를 하나의 모델만으로 처리할 수 있도록 설계되었다.
Segmentation, Keypoint Detection뿐만 아니라 Generative Task도 처리할 수 있으며, 이전에 본 적 없는 Task에 대해서도 잘 작동하는 모습을 보인다.
1. Introduction

최근 몇 년간 NLP 분야에서는 다양한 NLP Task를 하나의 일관된 Framework로 통합하는데 성공하였다. 하지만, NLP에 비해 CV(Computer Vision)에서의 Task 통합은 더욱 어려운 과제이다. 본 논문에서는 그 이유를 크게 3가지로 들고있다.
1) Diversity of Tasks and Outputs
첫 번째 이유는 다른 Task마다 각기 다른 Output 형태이다. 모든 Output이 Text로 나오는 NLP와는 다르게 CV Task에서는 Coordinates(Pose Estimation), Binary Mask(Segmentation), Images(Generation), and Category(Classification) 등 각기 다른 출력 형식을 가진다. 때문에 이처럼 다양한 Output 형태를 하나의 통일된 형태(Representation)로 표현하기가 어렵다.
2) Different Methodologies and Techniques
또 다른 이유는 방법론인데, Vision Task에서는 주로 문제에 따라 완전히 다른 알고리즘과 모델을 필요로 한다. 예를들어 Image Generation Task에서는 GAN이나 DDPM과 같은 방법론을 많이 사용하지만, Object Detection이나 Image Classification과 같은 Image Understanding Task에서는 위와 같은 방법론을 잘 사용하지 않는다. 이는 NLP에서 Transformer 계열의 모델을 주로 사용하는 것과 대비되는 현상이다.
3) Continuous Input and Output
마지막 이유는 CV Task에서 주로 Continuous한 데이터(Coordinate, Image 등)를 Input과 Output에 사용한다는 점이다. 이러한 Continuous Nature를 통합된 방식으로 다루는 것이 어렵고, 물론 VQ-VAE와 같은 기법으로 데이터를 이산화할 수 있지만 이 과정에서 발생하는 Quantization Error로 인해 결국은 정확도가 떨어진다는 문제가 발생한다. 이 또한 NLP Task에서 주로 Input/Output을 Text Token으로 이산화하는 점과 대비된다.
본 논문에서는 DDPM의 장점을 활용해 위와 같이 CV에서 여러 Task를 통합하기 어려운 문제를 해결하고자 하였다. 즉, 모든 CV Task를 Image Generation(Instructional Image Editing) Task로 간주하여 처리한 것이다.
- Image Segmentation → 해당 객체의 픽셀을 특정 색으로 바꾸는 것으로
- Keypoint Detection → 특정 위치에 불투명한 색 원을 배치하는 것으로
- Classification → Object의 Class에 따라 색을 다르게 지정하는 것으로
본 연구의 방법론은 이전 연구에서 Vision Task를 Image Inpainting 문제로 접근했던 것보다 직관적이고 인간의 의도를 정확하게 반영한다. 또한 DDPM은 입출력이 모두 연속적이므로 이산화 과정이 불필요해, Quantization Error 문제 또한 피할 수 있다.
본 논문에서는 Output Format을 3가지로 구성하였다.
- RGB 3채널 이미지
- Binary Mask
- Keypoint
이 3가지 형식을 사용하면 대부분의 Vision Task를 수행할 수 있다고 주장하며, DDPM의 출력이 기본적으로 RGB 이미지이기 때문에(생성 Task에서 사용하다보니) Mask와 Keypoint 정보를 3채널 이미지로 인코딩하는 Unified Representation 방법을 같이 제안한다. 평가 단계에서는 이들을 Post-processing 모듈을 통해 일반적인 형태로 변환하여 진행한다.
학습 단계에서는 하나의 모델에 다양한 작업을 공통으로 학습하였으며, Image Editing을 위한 새로운 데이터 셋 또한 수집하였다. 실험 결과 InstructDiffusion 모델은 각각의 Task에서 우수한 성능을 보였으며, Task별로 개별 모델을 학습하는 것보다 일반화 능력이 향상되는 것을 확인할 수 있었다.
심지어는 학습에 사용되지 않은 Image Detection이나 Classification Task까지도 잘 수행하는 것을 확인하였으며, 이를 통해 Vision 기반의 AGI를 향한 연구의 기반을 마련하였다.
2. Related Work
여러가지 Task를 통합하는 연구가 최근 많이 이루어지고 있으며, 본 논문에서는 이러한 최근의 연구 흐름을 간단히 소개한다.
Vision language Foundation Models
웹 상에 대규모로 존재하는 이미지-텍스트 쌍 덕분에 최근 Vision-Language 연구가 활발하게 진행되고 있다. CLIP과 ALIGN의 경우 Contrastive Loss를 통해 이미지와 텍스트를 공통 Embedding 공간으로 정렬하는 방식을 사용하였고, Image-Text-Label의 관계를 모델링 한 UniCL, 더 넓은 Task와 멀티모달을 지원하는 Florence, INTERN과 같은 모델이 등장하였다.
하지만, 이런 Contrastive 기반 방법은 언어를 생성하는 능력이 부족해 Captioning이나 VQA와 같은 Open-ended Task에 한계를 가진다. 따라서 PaLM, LLaMA와 같은 LLM 모델을 사용하여 Visual 정보를 언어 모델에 통합하려는 시도가 존재한다.
- BEIT-3: Masking 기반 데이터 모델링으로 여러 Task에 대한 Pretraining을 통합(Pretrain할 때 Task마다 다른 방식으로 학습시키지 말고 하나의 모듈로 학습하자)
- CoCA/BLIP: Contrastive Learning과 Generative Learning을 통합
- Flamingo: Visual data와 Text를 자유롭게 섞은 입력을 받아 Open-ended 방식으로 텍스트를 생성
- LLaVA: 이미지-텍스트 쌍을 Instruction 기반의 학습 형식으로 변환하여 Instruction Tuning 학습을 진행
- GLIP v2/Kosmos v2: Grounding 능력(언어와 실제 시각 정보를 정확하게 연결짓는 능력)을 강화하기 위해 Alignment 학습을 진행
본 논문이 제안하는 방법은 LLaVA와는 다르다. LLaVA가 자연스럽게 Instruction 기반으로 표현 가능한 VQA와 같은 Open-ended Task를 대상으로 한다면, 본 논문에서는 Segmentation이나 Keypoint Detection처럼 표현이 모호하고 명확한 형식이 부족한 작업들을 Instruction 기반으로 통합하고자 한다. → 본 논문에서는 이것이 더 어려운 Task라고 말한다.
Vision Generalist Models
다른 분야와 마찬가지로 Vision 분야에서도 당연히도 한 번 학습시킨 모델이 다양한 Task를 매끄럽게 처리하는 것이 이상적이다. 따라서 이러한 범용 모델 연구가 많이 이루어져 왔고, 여기서 발생하는 어려움은 Task별 Output 구조의 다양성과 복잡성이다.
현재 Output을 통합하는 방식으로는 Language-like generation과 Image-resembling generation 방식이 존재한다. 지금까지 대다수의 연구는 전자의 방식을 따라 이미지 정보를 NLP 모델에 넣기 위한 연구를 진행하였다(ex. Pix2Seq v2, Unified IO). 그러나 이를 위해서는 이산화 과정(토큰화)이 필요하며 이는 정보 손실을 야기하기 때문에, 이를 피하기 위해 이미지 자체를 Interface로 사용(입력과 출력을 이미지 자체로 사용)하는 Painter나 PromptDiffusion 같은 모델이 등장하였다.
본 논문에서는 Image-resembling generation 방식을 따랐다. 여기에 기존의 In-context 방식대신 Explicit Instruction을 활용하여 Task의 의도와의 Alignment 정확도를 높이고, Sementic한 이미지 편집 작업까지 통합할 수 있도록 설계하였다.
3. Method
본 논문에서는 다양한 Vision Task를 처리할 수 있도록 설계된 InstructDiffusion을 제안한다. 이 모델은 DDPM(Denoising Diffusion Probabilistic Model)을 활용하여 모든 CV Task를 Image Manipulation 과정으로 간주하고 유연하고 상호작용이 가능한 Pixel Space를 Output 형식으로 사용한다.
기존 멀티모달 모델들이 자연어를 출력 형태로 가지는 것과 달리 본 논문에서는 RGB 3채널 이미지, Binary Mask, Keypoint 3가지 출력 형식을 가져 Segmentation, Keypoint Detection, Image Synthesis 등 다양한 Vision Task를 수행할 수 있도록 설계하였다.
3.1. Unified Instructional for Vision Tasks
모든 Task를 수행할 수 있는 모델링 Interface를 본 논문에서는 Instructional Image Editing이라고 이름 지었다. 학습 데이터 셋을 $x_i$라고 할 때, 각 데이터 $x_i$는 ($c_i, s_i, t_i$)의 형태로 표현된다.
- $c_i$: Control Instruction
- $s_i$: Source Image
- $t_i$: Target Image
이 구조 속에서 모델은 입력 이미지 $s_i$와 지시어 $c_i$가 주어졌을 때, 그에 맞는 출력 이미지 $t_i$가 생성되도록 학습을 진행한다. 이러한 Semantic Image Editing과 비슷한 이전 연구로는 InstructPix2Pix가 있다.
본 논문에서는 기존 Pix2Seq이나 UnifiedIO와 같이 Task명을 자연어 지시어를 사용하는 것이 아닌, 모델이 지시어를 그 자체로 이해하고 실행할 수 있도록 구체적이고 직관적인 지시어를 설계하였다.
Keypoint Detection
Keypoint Detection의 목적은 이미지 속에서 특정 객체의 구성 요소를 정확히 찾는 것이다. 기존에는 각 Keypoint에 2D Gaussian Heatmap을 덧씌우는 Heatmap Regression 방식이 주로 사용되었지만, 본 논문에서는 "남자의 왼쪽 어깨를 빨간색으로 동그랗게 칠해주세요"와 같은 직관적이고 상세한 지시어를 제공함으로써 출력 이미지에 Keypoint 검출 결과를 시각화해준다.
→ 그렇다고 하니 왼쪽 남자의 오른쪽 무릎과 같은 말을 했을 때 얼마나 정확도가 잘 나오는지 평가해 볼 필요가 있다.
Segmentation
Keypoint Detection과 마찬가지로 "오른쪽에 있는 개에 파란색 반투명 Mask를 적용시켜주세요."와 같은 지시어를 넣으면 출력 이미지 속 해당 개한테만 파란 반투명 Mask가 적용된다. 불투명이 아닌 반투명 Mask로 설정하였기 때문에 사람이 직관적으로 모델의 성능을 평가할 수 있다.
Image Enhancement and Image Editing
본질적으로 위 작업들은 출력 이미지를 생성하기 때문에 수행할 Task를 명확히 나타내는 지시어를 구성해야 한다.
- "이미지를 더 선명하게 만들어주세요" → Image Deblurring
- "이미지에 있는 워터마크를 제거해 주세요" → Watermark Removal
- "여자의 손에 사과를 추가해주세요" → Image Editing
위 예시 지시어와 같이 각 Task 당 10개의 기본 지시어를 수작업으로 작성하고 GPT-4를 사용해 이를 다양하게 변형/확장하여 Instruction을 구축하였다. 학습 과정에서는 이들 중 하나를 무작위로 선택하여 사용하였고, 이와 같은 다양하고 직관적인 Instruction 기반 학습을 통해 Multitask 통합 능력을 향상시킬 수 있었다.
3.2. Training Data Construction
본 논문에서는 최대한의 성능을 내기 위해 대규모로 데이터를 확장시키기보다, 다양한 Task들이 Image-resembling generation 방식 하에서 서로에게 도움이 되는지를 검증하는데 초점을 맞추었다. 따라서 공개된 데이터 셋들을 활용해 Instruction Template에 따른 Ground Truth를 구축하였으며, Semantic Segmentation에는 COCO-Stuff, Keypoint Detection에는 COCO, MPII, CrowdPose(오타발견), AIC 데이터 셋을 사용하였다.
기존 Image Editing 데이터 셋에는 InstructPix2Pix(IP2P), GIER, GQA, MagicBrush와 같은 데이터 셋들이 존재하지만, 이 데이터들은 품질 편차가 크고 Instruction이 Global 스타일을 변경하는데에 초점을 맞추고 있다. 이에 본 논문에서는 159,000개의 Image Editing Pair로 이루어진 새로운 데이터 셋 Image Editing in the Wild(IEIW)를 제안한다. IEIW는 다양한 Semantic 객체와 세부 정보를 포함하고 있고 다음의 3가지 방식으로 구성되어 있다.
1) Object Removal
가장 흔한 Image Editing 방식인 객체 제거 방식이다. PhraseCut 데이터 셋을 활용하여 Instruction 기반 객체 제거 데이터를 구성하였으며, PhraseCut 데이터에는 Referring Phrase와 이에 해당하는 이미지 영역이 존재하는데, 이 영역을 Mask로 설정하고 LAMA 모델을 활용해 inpainting하여 객체 제거 이미지를 생성하였다.
이 때 입력 이미지와 출력 이미지 순서를 바꾸고 Instruction을 반전시켜 객체를 추가하는 데이터 또한 생성하였다.
(ex. "나무 위에 있는 파란 새를 지워줘" → "나무 위에 파란 새를 추가해줘")
2) Object Replacement
다음은 특정 객체를 다른 객체로 교체하는 데이터이다. Semantic 영역에 대한 Annotation과 이미지를 제공하는 SA-1B, OpenImages 데이터를 활용하였으며 구체적인 이미지 생성 방식은 다음과 같다.
- Semantic 영역 기반으로 다양한 이미지 Patch로 구성된 Gallary Database를 생성
- 임의의 이미지에서 하나의 Semantic 영역을 선택하고 Query Patch로 사용
- 해당 Query와 유사한 영역을 갤러리에서 검색하여 Reference Image를 획득
- PaintByExample을 사용해 교체된 Target Image 생성
위와 같이 생성한 이미지에 대해서는 BLIP2 모델을 사용해 입력/출력 이미지 각각에 대해 캡션을 생성하였다.
3) Web Crawl
실제 사용자의 요구에 더욱 잘 맞추기 위해 "Photoshop Request"라는 키워드로 구글에 이미지를 검색해 총 23,000개 이상의 데이터 Triplet을 수집하였다.
위와 같이 수집한 데이터는 학습 데이터의 품질을 보장하기 위해 LAION-Aesthetics-Predictor 모델을 사용해 미적 점수를 계산하였고, GIQA 점수를 측정하여 출력 이미지의 품질이 지나치게 낮거나 입력-출력 간 품질 격차가 심한 데이터들은 제거하였다.
3.3. Unified Framework
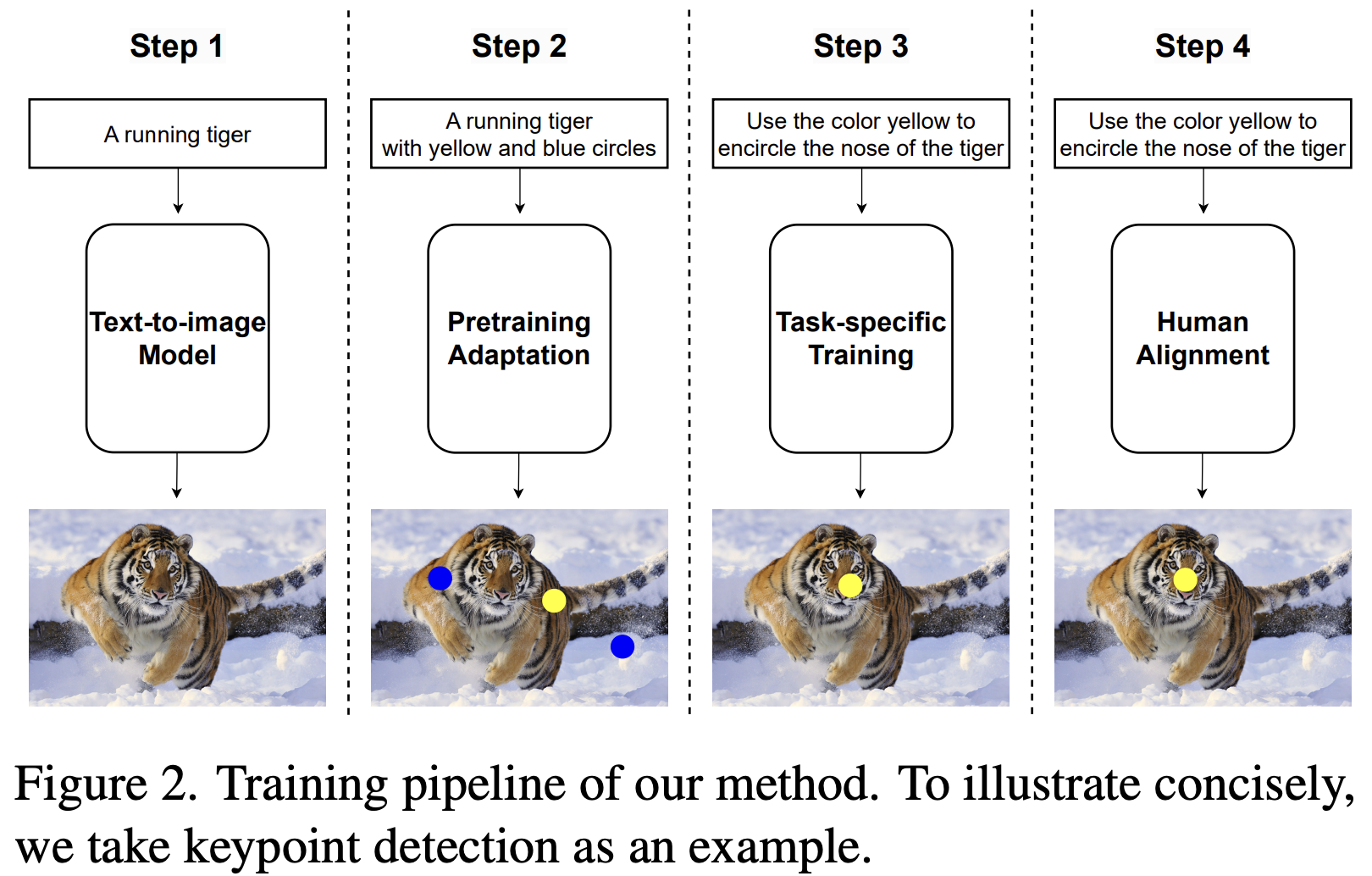
앞서 데이터를 어떻게 구축하였는지 설명하였다면, 이 섹션에서는 Framework를 어떻게 구성하였는지에 대해 서술한다. Introduction에 서술하였듯이 본 논문의 Framework는 Diffusion 기반이며, Figure 2에서 볼 수 있듯이 전체 학습 과정은 3단계로 구성된다.
1. Pretraining Adaptation
본 논문에서 사용한 Base 모델은 Stable Diffusion v1.5이다. 본래 Stable Diffusion 모델은 Text를 입력하면 Image를 출력하는 구조이지만, 본 논문에서는 경우에 따라 Segmentation Mask나 Keypoint 표시가 포함된 이미지가 생성되기를 원한다.
이를 위해 기존 Segmentation, Keypoint Detection 데이터 셋을 활용하여 Mask가 포함된 이미지나 특정 표시가 있는 이미지를 생성하여 Diffusion Output Distribution을 조정하였다. 그리고는 본래 존재하는 이미지 캡션에 접미사로 "여기저기 색깔 패치가 조금 있는 이미지", "빨간 원으로 둘러싸인 이미지"와 같은 텍스트를 추가해 Diffusion 모델을 Fine-tuning하였다.
2. Task-specific Training
다음 단계로는 Diffusion 모델이 다양한 Task별 Instruction을 이해하고 수행할 수 있도록 Fine-tuning을 진행하는 것이다. 이 부분에서는 InstructPix2Pix의 접근 방식을 따랐으며, 입력 이미지를 Noise 입력과 함께 Channel 차원에서 합쳐서 모델에 주입하였다.
모든 Task에 대한 데이터를 통합하여 학습을 진행하였지만, Task별 데이터 양이 서로 다르기 때문에 데이터 셋마다 Sampling 가중치를 수동으로 설정하여 그 균형을 유지하였다. Loss Function은 다음과 같다.
$$\mathcal{L} = \mathbb{E}_{(s_i, c_i, t_i)\sim \mathcal{P}(x),\epsilon \sim \mathcal{N}(0,1),t}\left [ \left\| \epsilon - \epsilon_{\theta}(z_t, t, s_i, t_i)\right\|^2_2 \right ]$$
각 샘플 ($s_i, c_i, t_i$)에 대해 우선 출력 이미지 $t_i$를 인코딩하여 Latent $z$를 만들고 Diffusion Noise를 추가하여 $z_t$를 획득한다. 즉, 일반적인 Diffusion 모델처럼 모델이 노이즈를 잘 제거하고 타겟 이미지로 복원하는 능력을 학습하도록 설계되었다.
3. Instruction Tuning
Editing 품질을 향상시키기 위해 LLM의 Instruction Tuning 기법에서 아이디어를 차용하였다. 수행 절차는 다음과 같다.
- 벤치마크용 입력 이미지에 대해 Classifier-Free Guidance 가 다른 20개의 결과를 생성한다.
- 사람 평가자가 만들어진 결과중 가장 좋은 품질의 결과를 0~2개 선택한다.
- 선택된 쌍을 Instruction Tuning 데이터 셋으로 구성한다(1000개 이미지)
- 이 데이터 셋으로 모델을 10 Epoch 동안 추가로 Fine-Tuning한다.
이를 통해 모델이 사람의 의도에 맞는 Image Editing을 수행할 수 있도록 만든다.
4. Experiments
4.1. Settings
InstructDiffusion 모델은 {Instruction, Source Image, Target Image}로 구성된 샘플을 기반으로 학습되며, Keypoint Detection, Semantic Segmentaion, Referring Segmentation, Image Enhancement(Denoising, Deblurring, Watermark Removal), Image Editing과 같은 다양한 Vision Task를 대상으로 한다.
Keypoint Detection
Keypoint Detection 파트에서는 COCO, CrowdPose, MPII, AIC 4가지 데이터를 사용하였다.
| 데이터 셋 | 이미지 수 | Keypoint 수 |
| COCO | 149K | 17개 |
| CrowdPose | 35K | 14개 |
| MPII | 22K | 16개 |
| AIC | 378K | 14개 |
학습 시 각 이미지 당 1~5개 Keypoint를 무작위로 선택하였고, 각 Keypoint에 무작위 색상을 할당하였다. 이 때 Instruction은 해당 Keypoint에 대해 정해진 색상으로 칠해달라는 Template으로 구성된다. 출력 이미지는 해당 Keypoint에 정해진 색상으로 칠해진 작은 원을 그리며 생성된다.
여기까지만 보면 단순 Pose Estimation 성능이 아닌 색깔을 나타내는 단어를 이해하는 정도도 평가할 수도 있는 것으로 보임
Segmentation
Semantic Segmentation에는 COCO-Stuff 데이터를, Referring Segmenation에는 gRefCOCO와 RefCOCO 데이터 셋을 사용하였다. Instruction은 LLM의 도움을 받아 만든 Prompt Template을 기반으로 구성하였다.
예시: "Place a {color} mask on {object}"
학습 과정에서 color는 무작위 색상으로, object는 정해진 카테고리 명으로 대체하였으며, 출력되는 이미지는 해당 object에 투명도 0.5만큼의 Mask를 씌운 이미지로 생성하였다.
Referring Segmenation이란?
특정 영역을 설명하는 자연어 텍스트가 주어졌을 때 이미지에서 해당 영역을 찾는 Instance Segmentation
Image Enhancement
Deblurring, Denoising, Watermark Removal 3가지 Task를 수행하였다. 디테일은 논문을 참고
Image Editing
InstructPix2Pix, MagicBrush, GIER, GQA inpainting, VGPhraseCut, 생성한 내부 데이터 셋, 웹 크롤링으로 구축한 데이터(Section 3.2. 참고)를 사용하였다.
최종적으로 각 Task 별 사용한 데이터 수는 다음과 같다. 각 Task 별로 사용한 데이터 수가 다르기 때문에 Sampling Weight를 별도로 설정.

구체적인 Implementation Detail은 논문을 참고.
4.2. Keypoint Detection

본 논문에서는 Keypoint Detection 성능 평가를 위해 Close-set 평가(COCO)와 Open-set 평가(HumanArt, AP-10K)를 진행하였다.
HumanArt 데이터 셋은 사람을 그린 만화, 실루엣, 벽화 등 인공적인 이미지로 구성되어 모델 학습에 사용한 COCO 데이터 셋과는 다른 Distribution을 가진다.
또한 AP-10K 데이터 셋은 동물 Keypoint 데이터 셋으로 사람 Keypoint 데이터만으로 학습했음에도 동물에 대한 Keypoint Detection이 가능한지 평가를 진행
→ 일반화 성능 평가
모델이 최종적으로 생성하는 원이 그려진 결과만 가지고는 좌표 정확도를 평가하기 어렵기 때문에 모델 출력 이미지에 Lightweight U-Net을 후처리 모듈로 사용하여 다채널 Heatmap을 생성하였다. 그리고 이 Heatmap에서 좌표를 뽑아 정확한 Keypoint 위치를 추출하였다.
"원으로 칠해진 이미지 → U-Net을 통한 좌표 추출"은 어떻게 가능한가? (내 생각)
1. InstructDiffusion의 출력 이미지는 256x256 크기의 RGB 채널을 가진 이미지 (256x256x3)
2. 위 이미지를 입력으로 넣는 Lightweight U-Net 모델을 별도로 학습 (Image → Heatmap)
→ 그렇게 되면 결국 이 Lightweight U-Net 모델의 OKS 성능에 따라 최종적인 예측 성능도 좌우되지 않나? Keypoint Detection만 수행할 거면 이 과정은 매우 불필요해 보임
Q: 본 논문의 저자는 U-Net이 성능에 미치는 영향이 왜 미미하다고 말하는 것일까?
- 간단한 매핑과정이라는 말이 이해되지 않음..
- 입력은 특정 색 원이 칠해진 이미지(이후 모든 실험에서 GT BBox를 사용한다 하여 사람 이미지가 들어갔을 수 있음) → 출력은 선택된 Keypoint 중심 위치를 2D Gaussian으로 변환한 GT 히트맵 (17채널이며 선택되지 않은 Keypoint는 0으로 칠함)
- 이 과정에서 Lightweight U-Net이 아니라 ViTPose를 사용해 학습하였다면 OKS 성능이 더 좋아질 것 같은데 큰 차이가 나지 않으려나... 물론 저기 뒤에 성능평가하겠다고 ViTPose를 넣는것도 이상하긴 하다. U-Net이면 Simplebaseline 형태이려나..?
https://github.com/cientgu/InstructDiffusion/issues/9
평가 Metric으로는 일반적으로 Pose Estimation Task에서 사용하는 OKS(Object Keypoint Similarity) 기반의 AP(Average Precision)을 사용하였고, 모든 실험에 대해서는 GT Bounding Box를 사용하였다(Top-down). 특히 AP-10K 실험에서는 COCO에서 정의된 관절과 겹치는 Keypoint에 대해서면 OKS를 계산하여 기존 방법들과의 공정한 비교를 가능하게 하였다.
AP-10K 중 COCO와 겹치는 Keypoint만 평가에 사용했다?
AP-10K에는 동물에 특화된 Keypoint가 많기 때문에 COCO에 존재하는 Keypoint만 평가에 사용했다는 의미. AP-10K의 모든 Keypoint를 평가에 포함하면, COCO 데이터 셋으로 학습한 모델은 해당 Keypoint를 학습하지 않았기 때문에 성능이 과소평가될 수 있기 때문.
(ex. "left_front_leg" ↔ "left_shoulder" / "snout" ↔ "nose")
Keypoint Detection 성능은 Table 2에 나타나있다. 기존 Generalist Model들보다는 높은 성능을 보인 것을 확인할 수 있고, 기존 Keypoint-specific 방법들보다는 낮은 Localization 성능을 보였지만, AP-10K와 같이 완전히 처음 보는 동물 Keypoint Dataset에 대해서는 더 뛰어난 성능을 보였다.

Figure 3에서 볼 수 있듯이 학습에 사용하지 않은 객체에 대해서도 정확히 탐지를 이루어냈고(a, b, c), d와 같이 Referring Keypoint Detection Task에서도 효과적으로 모델이 작동하는 것을 확인할 수 있다(논문에서는 Versatile하다고 표현).
4.3. Segmentation
이 Section에서는 특히 Open-Vocabulary 상황에서의 모델 성능을 평가하는데 집중하였다(아무래도 Keypoint는 Open Vocabulary가 어려우니까 Segmentation에서 주목한 듯). 즉, 학습에 사용하지 않은 클래스가 포함된 이미지에 대해 얼마나 잘 일반화할 수 있는지를 분석한 것!
테스트에 사용한 데이터 셋 디테일은 논문을 참고.
Keypoint Detection과 마찬가지로 Segmentation 결과도 이미지로 출력되기 때문에 후처리용 Lightweight U-Net을 사용하여 각 객체에 대한 Binary Mask를 추출하였다. 평가지표로는 Referring Segmentation에서는 cIoU(누적 IoU)를, Semantic Segmentation에서는 클래스별 cIoU의 평균을 계산한 mcIoU를 사용하였다.
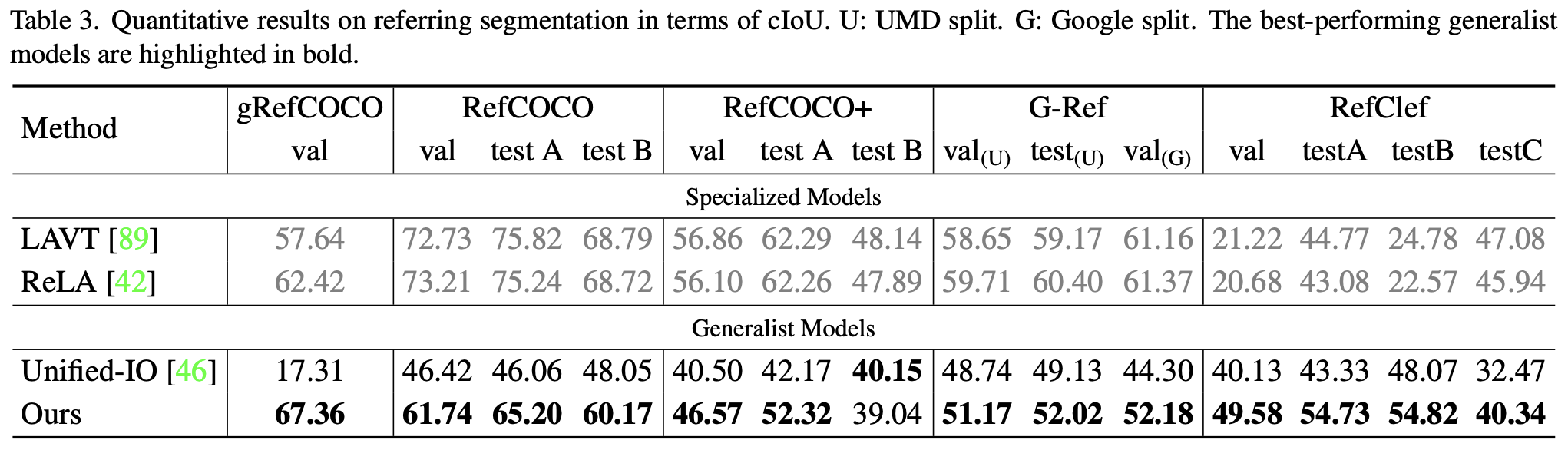
Table 3은 Referring Segmentation 실험에 대한 결과가 나타나 있다. Unified-IO 모델은 지금까지 유일하게 존재하는 Referring Segmentation을 지원하는 Generalist 모델이며, 대부분의 데이터 셋에서 InstructDiffusion 모델이 Unified-IO의 성능을 월등히 능가하였다.

Table 4에는 Semantic Segmentation 실험 결과가 나타나 있다. Painter 모델을 제외하고는 모두 COCO-Stuff 데이터로만 학습이 되었고, Closed-set 평가(COCO-Stuff)에서뿐만 아니라 Open-set 평가(학습에 사용되지 않은 다른 데이터)에서 InstructDiffusion이 우수한 성능을 보였다. ADE-150K 데이터에서 Painter 모델이 가장 좋은 성능을 보인 것은 Painter 모델이 해당 데이터 셋에서 별도로 학습되었기 때문이라고 말하고 있다.
또한 Painter나 PromptDiffusion 모델은 예시 이미지를 사용해 모델에 색상-Semantic 매핑을 학습시키기 때문에 새로운 클래스가 등장하였을 때 색상 지정이 잘 되지 않는 반면, InstructDiffusion은 텍스트 지시어를 사용하기 때문에 Open-set에서도 훨씬 더 정확한 Mask를 생성할 수 있다고 주장한다.

Figure 4를 통해 Referring Segmentation의 다양한 예시를 확인할 수 있다.
4.4. Image Enhancement

본 논문에서는 Low-level Vision Task에 대한 작업 성능을 평가하기 위해 널리 사용되는 벤치마크 데이터 셋을 사용하였다.
- Deblurring Task - GoPro 데이터 셋 (1280x720)
- Denoising Task - SIDD 데이터 셋 (256x256)
- Watermark Removal - CLWD 데이터 셋 (256x256)
평가지표로는 PSNR(Peak Signal-to-Noise Ratio)를 사용하였으며, 실험 결과는 다음과 같다(Table 5)
- Editing에 Specialize된 모델은 Image Enhancement Task로 일반화할 때 성능이 떨어지는 경향이 있다.
- 기존 Generalist 모델인 Painter는 Denoising에서는 뛰어난 성능을 보이지만 다른 Image Editing Task와의 자연스러운 통합이 어렵다.
- 본 논문이 제안하는 모델은 VAE 구조의 한계에 의해 제약을 받는다(Latent Bottleneck).
Table 5의 괄호 안에 쓰여진 값은 Upper Bound로, Ground Truth 이미지 자체를 VAE에 넣고 다시 출력하여 계산한 PSNR 값을 의미한다. 본 논문에서는 이 값을 InstructionDiffusion 모델이 낼 수 있는 이론적인 상한선으로 본다.

Figure 5를 보면 여러 Task에 대해 모델 수행이 잘 이루어진 것을 확인할 수 있다.
4.5. Image Editing

본 논문에서는 Image Editing 품질을 명확히 평가하기 위해, 총 1000개의 샘플 벤치마크를 별도로 구축하였다. 각 샘플은 다음의 요소로 구성된다.
- Source Image
- BLIP2를 사용해 생성한 Source Image Caption
- Editing Instruction
- Edited Image에 대한 Target Caption (GPT-3.5-turbo)
각 샘플에 대해 Replacement, Removal, Addition 3가지 Editing 시나리오 중 하나로 분류하였으며, CLIP Similarity와 Aesthetic Predictor's Score로 평가를 진행하였다.
실험 결과 기존 Generalist 모델 중 실제로 Image Editing이 가능한 모델이 없었으며, Editing 전용 모델(InstructPix2Pix, MagicBrush)과 비교하였을 때 더 높은 성능을 보였다(Figure 6).

Figure 7은 InstructDiffusion 모델의 성능을 보여준다.
4.6. The Benefit of Highly Detailed Instruction
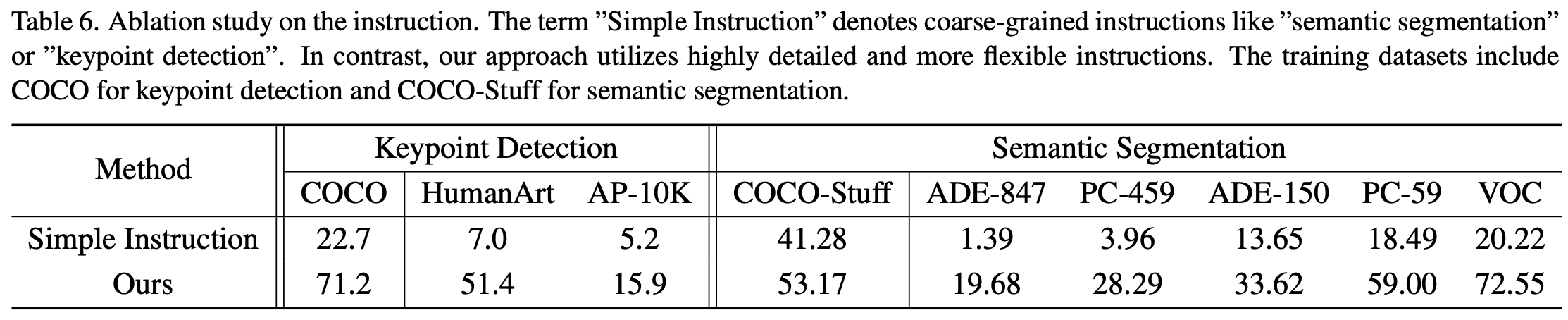
소제목 그대로 디테일한 지시어를 사용하였을 때 성능이 얼마나 좋아지는지를 실험한다. 기존 모델들은 자연어 Instruction을 단순히 Task Indicator로 취급하지만, InstructDiffusion에서는 훨씬 더 구체적이고 풍부한 설명을 포함한 Instruction를 사용한다. 이를 확인하기 위해 Instruction을 "Semantic Segmentation", "Keypoint Detection"과 같이 단순한 형태로 만들어 실험하였다.
그 결과 Table 6에서 볼 수 있듯이 단순한 Instruction을 사용할 경우 성능이 극단적으로 낮아지는 것을 확인할 수 있다.
→ 정교한 Instruction은 모델에게 더 높은 유연성과 적응력을 부여하며, 특히 오픈 도메인 상황에서 강력한 일반화 능력을 제공한다.
4.7. The Benefit of Multi-task Training

Segmentation Task 전용으로 모델을 학습시켜셨을 때 대비 Segmentation + Keypoint + Editing Task를 통합하여 학습하였을 때 오픈 셋 데이터에 더 뛰어난 성능을 보였다.

Figure 9에서 볼 수 있듯이 이러한 Multi-Task 학습은 Image Editing 성능에도 도움을 준다.
4.8. The Benefit of Human Alignment

1000개의 샘플로 구성된 Human Alignment 데이터 셋을 활용하는 것이 성능 개선에 영향을 주었다는 것을 보여준다.
4.9. Generalization Capability to Unseen Tasks

또한 모델이 학습에 사용하지 않은 Task에 대해서도 어느정도의 성능을 보인다는 것을 보여준다(Detection, Classification, Face Alignment).
5. Discussion and conclusion
본 논문에서는 InstructDiffusion이라는 인간의 Instruction에 맞춰 다양한 CV Task를 Alignment할 수 있는 새로운 Framework를 제안하였다. 모든 CV Task를 Image Generation 문제로 접근하여 3채널 RGB, Binary Mask, Keypoint 3가지 출력 형태만으로 해당 Task들을 모두 해결하였다.
물론 개별 Task에서도 우수한 성능을 보였으며, 여러 Task를 통합하여 모델의 일반화 성능을 보이고, AGI 특성을 나타낸다고 말하고 있다. 앞으로의 추가 연구로는 더 다양한 CV Task를 포괄할 수 있도록 방법론을 탐색하려 하며, Self-supervised Learning이나 Unsupervised Learning 방법론을 적용하여 대규모 비라벨링 데이터를 활용하고자 한다.
이번에 리뷰한 논문은 내가 준비하려 하는 논문 주제와 비슷한 방향성을 가지는 InstructDiffusion 논문이다. 이미지를 생성한다는 접근으로 여러 CV Task를 해결하려는 부분이 흥미로웠으며 NLP Task와 달리 통합된 Framework가 아직 나오지 않고 있는 CV Task에서 모델 통합을 진행하려 할 때 귀감이 될 수 있는 논문이라고 생각한다.
하지만 아쉬운 점으로는 모든 Task를 Diffusion 기반의 이미지 생성 Task로 접근하여 이미지 생성 성능이 높아지지 않는 한, 각 Task에 대한 성능 또한 기존 Specialized Model의 단일 Task 성능을 이기기 어려울 것이라는 점이다. 또한, 모델의 구성이 거의 3-stage의 구성을 띄어 모델 학습에도 어려움을 가진다. 때문에 논문과 오픈된 코드만 보았을 때 Segmentation Task에 대해서는 어떻게 실험이 된 것인지, Keypoint Detection Task에 대해서는 어떻게 실험이 된 것인지 자세히 알기가 어려운 상황이다(Evaluation 코드 공개가 안되어있음).
그럼에도 논문 속 예시로 나와있는 Implementation 성능은 좋아 보이며, 실험과 그에 따른 분석을 정말 다양하게 진행한 것으로 보아 추후 나의 연구에서 이론적인 배경을 참고하기 좋을 것 같다는 생각이 든다.
세 줄 요약
1. InstructDiffusion은 다양한 Computer Vision Task들을 인간의 자연어 Instruction에 기반한 이미지 생성 문제로 통합한 범용 프레임워크임
2. 다양한 CV Task를 다루기 위해 출력 공간을 3채널 RGB 이미지, 마스크, 키포인트로 통일하였고, 정교한 지시어와 멀티태스크 학습을 통해 강력한 일반화 능력을 확보함
3. 학습되지 않은 작업까지 수행 가능한 AGI적 특성을 일부 보여주며, 향후 비전 기반 범용 AI 모델 연구에 중요한 기여를 할 것으로 예상됨

'논문 paper 리뷰' 카테고리의 다른 글
| [Paper Review] MotionGPT 논문 이해하기 (0) | 2025.04.17 |
|---|---|
| [Paper Review] LLaVA 논문 이해하기 (0) | 2025.03.26 |
| [Paper Review] ViTAE 논문 이해하기 (0) | 2025.03.21 |




댓글