『MotionLLM: Understanding Human Behaviors from Human Motions and Videos. Arxiv. 2024.』
저번에 리뷰를 진행한 MotionGPT 논문에 이어 이번에 소개할 논문은 MotionLLM 논문이다. 기존에 존재하는 여러 Motion Task 관련 어떻게 실험을 진행하였는지 살펴보고, 본 논문에서 제안하고 있는 MoVid Dataset에 대해 알아보고자 한다.
중요한 핵심적인 내용 위주로 알아보자.
Github
https://github.com/IDEA-Research/MotionLLM
GitHub - IDEA-Research/MotionLLM: [Arxiv-2024] MotionLLM: Understanding Human Behaviors from Human Motions and Videos
[Arxiv-2024] MotionLLM: Understanding Human Behaviors from Human Motions and Videos - IDEA-Research/MotionLLM
github.com
0. Abstract

본 연구는 Multi-modality에 기반한 Human Motion을 이해하는 것을 목표로, Video와 Motion Sequence(SMPL형태)를 통합적으로 모델링하고자 한다. 이에 MotionLLM이라는 Framework를 제안하며, 인간의 Motion을 이해하고, Caption을 생성하며 추론할 수 있도록 설계하였다.
또한 다양한 Video, Motion, Caption, Instruction을 가지는 MoVid라는 대규모 데이터 셋을 수집하였고, 평가용으로 MoVid-Bench라는 Benchmark도 새롭게 설계하였다.
실험을 통해 MotionLLM이 Caption생성, 시공간 이해, 추론 능력 등에서 우수한 성능을 가지는 것을 입증하였다.
1. Introduction
Human Motion은 다음의 2가지 방식으로 표현될 수 있다.
- Motion 데이터(SMPL같은 3D Human Parametric Model이나 Skeleton 기반의 Sequence)
- 영상 데이터
Motion 데이터는 외형에 영향을 받지 않고, 정보 중복이 적으며 Privacy 측면에서 유리하지만, 고품질의 데이터를 얻기 위해서는 고가의 모션 캡처 장비가 필요하다는 단점이 있다. 또한 Motion만으로는 주변 환경과의 상호작용 정보를 얻기 어렵다는 점도 단점으로 꼽힌다.
반대로 일반 비디오의 경우 풍부한 환경 정보를 담고 있지만, 계산 비용이 높고, 사생활 침해 및 불필요한 정보가 담겨있다는 단점을 가진다. (ex. 골프를 치는 동작과 바닥을 쓰는 동작은 유사한 모션이지만 영상 속 장면에 따라 완전히 다른 행동으로 인식될 수 있다.)
본 논문에서는 이와같은 이유로 Motion의 간결함과 비디오의 맥락을 모두 결합한 통합 모델링이 중요하다고 말한다. 기존 연구들은 보통 Motion만, 또는 비디오만을 입력으로 사용했다는 점을 지적하며 그 원인이 기존에 존재하는 Video-Motion-Text + Instruction Tuning 데이터가 부족하다는 점과 Motion과 비디오를 통합하여 처리할 수 있는 통일된 프레임워크가 없기 때문이라고 주장한다.
MotionGPT와 다른점은 Video 정보까지 같이 통합하려 시도했다는 점이다.
위에서 제시한 문제를 해결하기 위해 본 논문에서는 3가지 접근을 시도하였다.
1) MoVid 데이터셋 구축
- 다양한 Video, Motion, Caption, QA 포함
- Motion 데이터는 AMASS, Motion-X 등 기존 대규모 데이터 셋에서 가져옴
- Caption과 QA는 GPT-4, GPT-4V로 자동 생성(27만개 이상의 Motion QA, 2만 개 이상의 Video Caption)
- 다양한 공간적/시간적 질문, Context 기반 질문, Inference 기반 질문을 포함
2) MotionLLM 모델 제안
- Motion과 Video를 동시에 처리
- Stage 1: 학습가능한 Translator를 통해 Visual Input을 Language Representation Space로 변환
- Stage 2: LLM과 V-L Translator를 Instruction Tuning하여 두 모달리티의 지식을 공유
3) Movid-Bench 벤치마크 설계
- Sequential Dynamics, Body-part Semantics, Direction Awareness, Reasoning Ability, Robustness against Hallucination을 평가하는 QA 데이터 셋
- 모든 정답은 사람이 직접 주석하고 검수
그 결과 MotionLLM은 기존 SOTA 모델인 MotionGPT와 Video-LLaVA에 비해 Motion and Video Understanding에서 향상된 성능을 보였다.
본 논문에서는 MotionLLM의 실제 응용 분야로 피트니스 코치나 시각장애인 보조 등에 활용이 가능할 것으로 보고있다.
2. Related Work
2.1. LLM-based Video Understanding
- 기존 멀티모달 LLM 모델이 이미지나 비디오를 alignment한 후 이를 Language Feature Space에 투영하는 것으로 설계되었다는 내용
2.2. Human Motion Understanding
- LLM을 활용한 Pose, Motion 이해 방법론이 등장하였지만, 단순한 설명 생성에 그쳐 시공간적인 이해나 추론 능력이 부족하다는 점을 지적
- 본 논문이 제안하는 MotionLLM은 Motion과 비디오를 Language Feature Space에 투영하는 것으로 심층적이고 통합적인 이해를 가능하게 만들었다는 점을 강조.
3. Methodology
3.1. Preliminaries and Notations
MotionLLM은 Visual Prompt $P=M \vee V$를 입력으로 받으며 여기서 $P$는 Motion 데이터 $M$ 또는 비디오 데이터 $V$ 중 하나를 의미한다. 출력은 Text Sequence $z={z_1, z_2, ... , z_L}$ \in {0,1}^{Lx|S|}$ 이며, 여기서 $S$는 Vocabulary Set을 의미한다.
Motion $M$은 $F$개의 Frame으로 이루어진 Pose Sequence를, 비디오 데이터 $V$는 $T$개의 Key-frame으로 이루어진 Image Sequence를 의미한다.
이러한 Text Generation 문제는 다음과 같이 Auto-regressive한 식으로 정의된다. $\mathcal{F}$는 MotionLLM을 의미하며, 학습에는 Cross Entropy Loss Function을 사용한다.
$$z = \mathcal{F}(z_{\mathcal{l}} | P, z_{<\mathcal{l}})$$
3.2. MotionLLM: Understanding Human Motions and Videos

Figure 2(a)에서 볼 수 있듯이 MotionLLM은 우선 Motion 또는 비디오 형태의 입력 P를 받아들이고, 이 입력 값은 먼저 Vision Encoder를 통해 처리된다. 이후 Vision-Language Translator를 통해 Language Feature Space로 변환된다(이 때 입력은 한번에 하나의 비디오나 Motion).
MotionLLM의 학습 과정은 Figure 2(b)에서 볼 수 있듯이 2단계로 나뉜다.
Stage 1) Modality Translation
(어떻게하면 비디오와 모션 정보를 Language Space로 잘 투영할 수 있게 Translator를 학습시킬 수 있을까?)
이 단계의 목적은 시각적인 정보를 Language Space로 투영하는 것이다. 따라서 Motion Encoder와 Video Encoder, LLM 본체를 모두 Freeze 시키고 오직 2개의 V-L Translator만 학습시킨다. 여기서는 주로 Motion Captioning이나 Video Captioning 데이터를 사용한다.
이 파트를 차용해서 시각적인 정보를 꼭 Language Space로 투영하는 것이 아닌, 시각적인 정보와 언어 정보가 잘 Fusion 될 수 있도록 설계하여 서브 모듈을 만들 수 있을 것 같다(비전 정보를 압축해 정보가 손실되는 것을 방지하기 위해).
Stage 2) Motion-Video Unified Instruction Tuning
(어떻게하면 모델이 다양한 Human Instruction에 응답할 수 있도록 학습할 수 있을까?)
여기서도 Motion Encoder와 Video Encoder는 고정한채, V-L Translator와 LLM 본체를 학습시킨다. LLM의 경우 LoRA를 이용해 효율적으로 Fine-Tuning(PEFT 방식)하고, 이렇게 하면 LLM의 본래 지식은 유지한채로 두 모달리티의 정보를 공유할 수 있다.

MotionLLM과 기존 모델과의 비교
- LLaVA: 이미지를 입력으로 받는 단일 모달 LLM
- Video-LLaVA: 이미지와 비디오를 입력으로 받아 하나의 V-L Translator를 공유해서 사용
- MotionLLM: Motion과 비디오에 각각 다른 V-L Translator를 사용
3.3. MoVid: Human Motion and Video Understanding Dataset
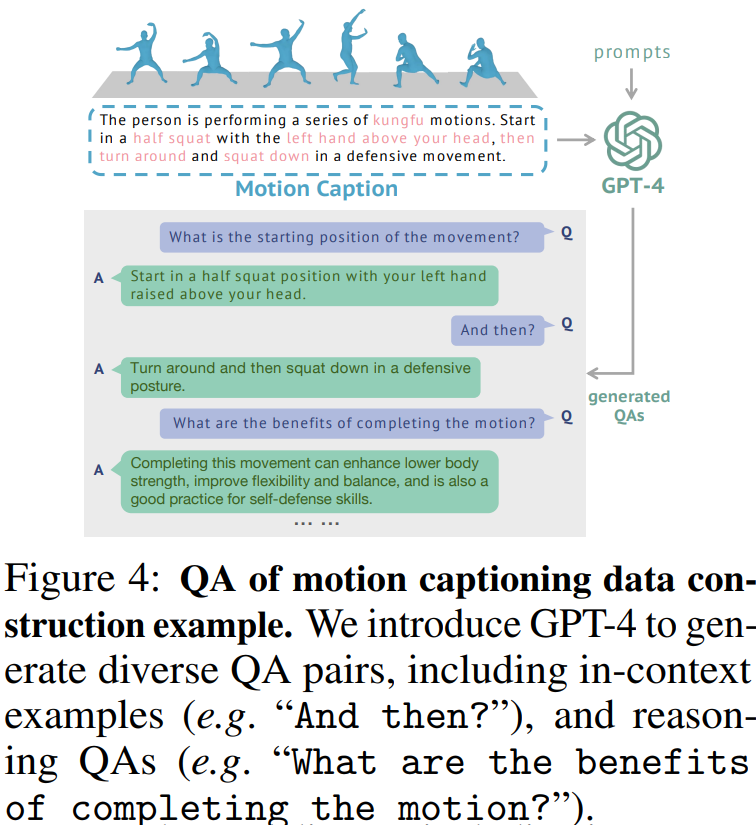
본 논문에서 구축한 MoVid 데이터 셋은 Motion과 비디오 파트 각각에 대한 Caption과 QA 형태의 Text Annotation을 포함한다.
Motion-text dataset construction
- HumanML3D(H3D), Motion-X 모션 데이터를 기반으로 존재하는 Caption을 GPT-4를 통해 QA 형태로 증강
- H3DQA는 272,000개, Motion-XQA는 200,000개 이상의 QA 쌍을 생성하였으며, 여기에는 시공간적인 질문, 문맥기반 질문, Reasoning 기반 질문을 포함
- MotionXQA는 훨씬 복잡하고 다양한 유형의 QA가 존재하며, 이러한 QA 데이터 셋은 Instruction Tuning에 활용
[예시]

Video-text dataset construction

비디오-텍스트 데이터 셋은 아직 제한적이기에 본 연구에서는 인간 중심의 영상 Annotation에 중점을 두었다. 특히 Motion-X 데이터 셋은 다양한 Motion-Video Pair를 제공하지만, 텍스트 Annoatation이 충분히 정교하지 못하다. 이에 본 논문에서는 Figure 5에서처럼 GPT-4V를 활용해 Motion-X의 영상 Caption을 다시 생성하였다.
이 때, 전체 비디오에서 15배로 다운샘플링해 Key-frame들을 추출하고, 해당 frame을 GPT-4V에 정교하게 설계된 Prompt와 함께 입력하여 정확하고 자세한 Caption을 생성하였다.
또한 Motion-X 데이터는 비디오와 Motion을 한 쌍으로 제공하기 때문에 동일한 주석을 Motion에도 반영할 수 있었으며, 그 결과 24,000개의 비디오-Motion 쌍에 대해 동일한 Caption을 가지는 데이터 셋을 구축할 수 있었다. 이렇게 구축한 Caption 데이터는 Figure 11과 같이 GPT-4를 이용하여 QA Instruction Dataset으로 확장하기도 하였다.
Dataset Statistics (아래 Table 1)
- H3DQA(Motion 기반): GPT-4를 이용한 QA 쌍 272,000개
- Motion-X(비디오 기반): GPT-4V를 이용한 신규 Caption: 24,000개
- Motion-XQA(비디오 기반): GPT-4를 이용한 QA 쌍: 200,000개
3.4. MoVid-Bench: Motions and Videos Understanding Benchmark

본 논문에서는 보다 정교하게 Human Behavior를 파악할 수 있는 새로운 벤치마크 MoVid-Bench를 설계하였다. 이 벤치마크에서는 Motion과 비디오에 대한 Human Behavior를 평가하며, Table 2에 나타나 있듯이 기존 VLLM 벤치마크를 참고해 구성되었으며 총 1350개의 QA 데이터 쌍을 포함한다.
평가 항목으로는 다음의 5가지에 대해 이루어진다(영어 단어로는 Introduction에 기재).
- 신체부위 인식(Body.): 개별 신체 부위의 움직임을 정확히 파악하는 능력
- 순차분석 능력(Seq.): 동작 순서를 올바르게 이해하고 서술하는 능력
- 방향 인식(Dir.): 움직임의 방향성 이해
- 추론 능력(Rea.): 동작의 의미나 목적을 유추하는 고차원적인 추론 능력
- 환각 저항성(Hall.): 현실에 없는 정보를 생성하지 않는 능력
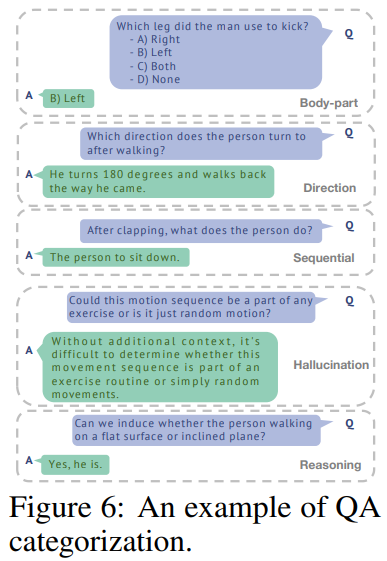
Figure 6를 통해 위 5가지 항목이 실제 QA에 어떤 식으로 적용되는지 확인할 수 있다.
4. Experiments
4.1. Experimental Setting

Training Dataset
- Motion 데이터 학습: H3D, Motion-X Caption 데이터 사용. Instruction Tuning에는 직접 구축한H3DQA, Motion-XQA + BABEL-QA 2000개 사용
- 비디오 데이터 학습: Stage 1에는 Valley, Stage 2에는 Motion-XQA + Video-ChatGPT 데이터 사용
Evaluation Dataset
- Motion 기반 Task: MoVid-Bench 평가, BABEL-QA 테스트 세트(기존 연구와의 비교)
- 비디오 기반 Task: MVBench(zero-shot 평가), ActivityNet-QA(zero-shot 평가), MoVid-Bench(세부 항목 평가)
MoVid-Bench 세부항목
Action Localization, Action Prediction, Action Sequence, Egocentric Navigation, Fine-grained Action, Fine-grained Pose, Unexpected Action
Evaluation Metrics
- MoVid-Bench: 기존 연구 프로토콜을 따라 GPT-3.5-turbo를 이용한 평가를 수행. 모델 응답과 정답 간 유사도를 기반으로 정확도 계산, 0~5점 점수 부여
- BABEL-QA: 원 방법론과 동일하게 정답 예측 Accuracy로 평가
- MVBench: 객관식 질문에 대해 가장 적절한 답을 고르는 방식(Prompt 활용)
- ActivityNet-QA & MoVid-Bench: GPT-3.5-turbo 평가 방식 사용
Implementation Details
- 전체 Framework: lit-gpt Framework
- Motion Encoding: VQ-VAE
- Video Encoding: LanguageBind
- LLM: Vicuna-7B
- Motion V-L Translator: 1-layer Linear layer
- Video V-L Translator: 2-layer MLP(Video가 Motion보다 복잡하기 때문에)
- Video는 8 Frame 이미지로 구성하고 모션은 전체 Sequence 입력
자세한 Details는 논문을 참고.
4.2. Quantitative Results
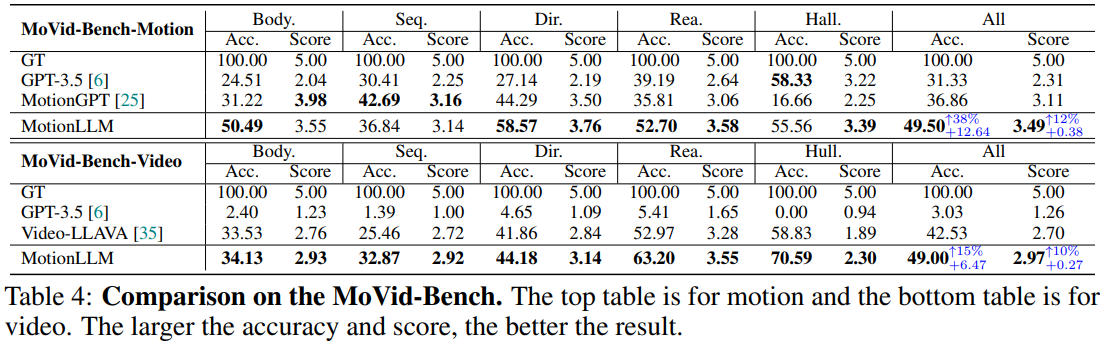
Motion Understanding에 대해 5개 측면에 대한 평가 결과가 Table 4에 기록되어 있다. 기존 모델 대비 MotionLLM의 성능이 좋은 것을 확인할 수 있다.
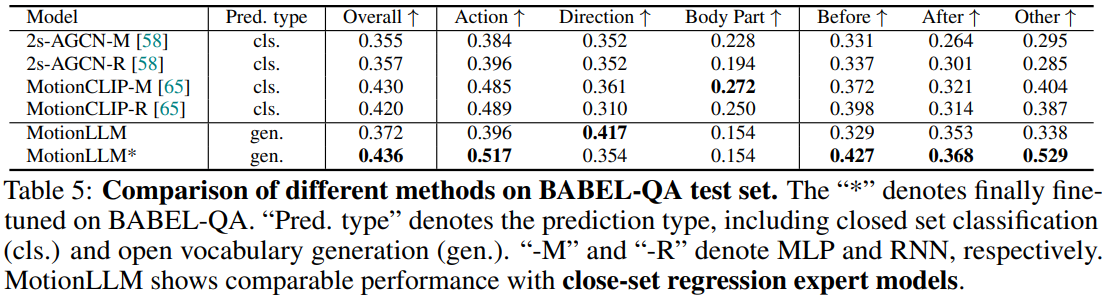
BABEL-QA 데이터 셋을 가지고 진행한 평가는 시공간 인식 능력을 평가하기 위함이며, 2s-AGCN과 MotionCLIP 모델과의 성능을 비교하였다. MotionLLM*은 BABEL-QA 데이터에 특화되어 Tuning된 버전이며, 특화되지 않더라도 기존 모델들과 비슷한 성능을 낸 것을 확인하였다.
2s-AGCN과 MotionCLIP은 Closed Vocabulary 안에서만 정답을 선택할 수 있기 때문에 Open형인 Motion-LLM의 이러한 성능은 주목할만 하다.

Video Understanding 파트에서도 MotionLLM은 좋은 성능을 보였다. 기존 SOTA인 Video-LLaVA 모델 대비 모든 항목에서 성능이 높았으며, 특히 Sequenctiality(동작 순서), Reasoning, Hallucination 항목에서 좋은 성능을 내었다.
비디오 당 8 Frame만을 처리했음에도 기존 LLM보다 우수한 정확도를 보였다는 장점 또한 가진다.

Table 7에서는 긴 비디오를 기반으로 Human Behavior를 평가한 결과이다. MotionLLM은 이 데이터 셋으로 학습된적이 없더라도 기존 모델 대비 좋은 성능을 보였다.
4.3. Qualitative Results
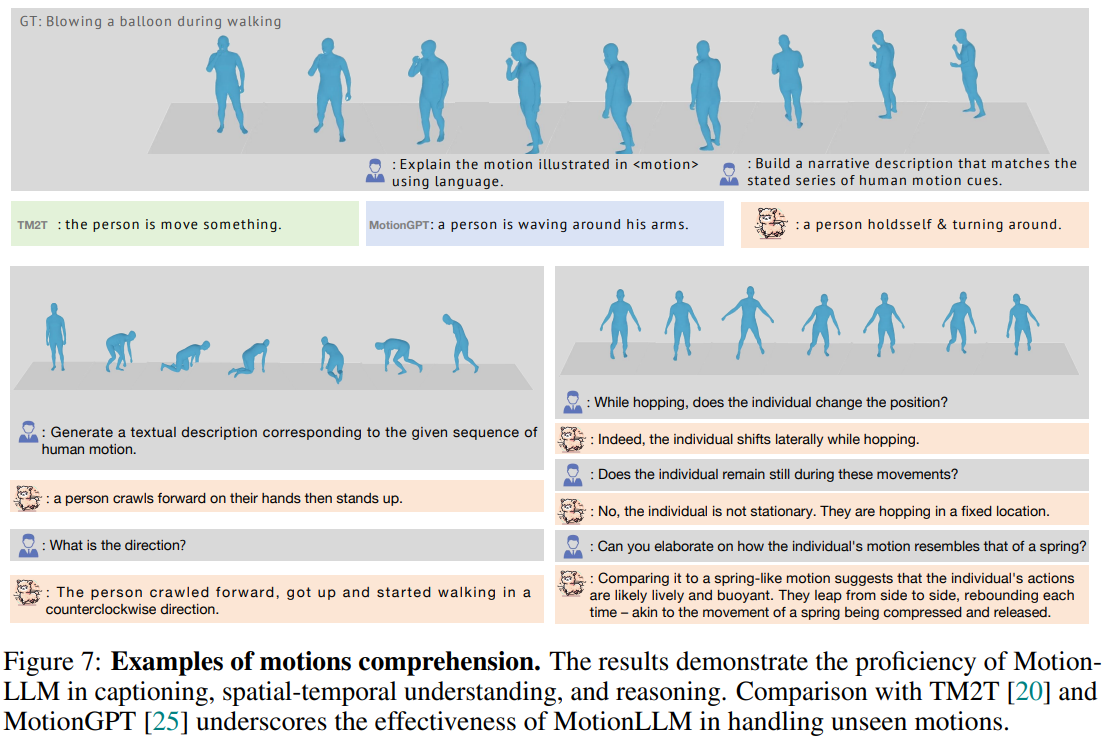
Figure 7에서 볼 수 있듯이 MotionLLM은 다양한 in-the-wild 환경에서도 뛰어난 일반화 능력을 보여준다(Motion 데이터 자동 주석 생성기로 사용이 가능할수도). 공간적인 인식 능력 또한 뛰어난 것으로 보인다.

Video 기반의 예시들을 살펴보더라도 기존 VideoChat이나 Video-LLaVA를 실행하였을 때의 결과보다 본 논문이 제시하는 MotionLLM 모델이 일관된 문맥 이해력과 시간 흐름 인식 능력이 좋은 것을 확인할 수 있다.
4.4. Ablation Study

Ablation Study는 MoVid-Bench로 평가를 진행하였으며, 그 결과는 Table 8에서 확인할 수 있다. 윗 줄은 Video 데이터를 Motion Understanding에서 같이 사용한 결과를, 아랫 줄은 Motion 데이터를 Video Under Standing에서 같이 사용한 결과를 나타낸다.
결론적으로 두가지 데이터가 같이 사용되고(결합되고) Pair 데이터 셋을 사용할 때 그 결과가 가장 좋았던 것을 확인할 수 있다.
5. Conclusion and Discussion
본 논문에서는 MotionLLM이라는 Human Behavior Understanding을 위해 Motion과 Video, Language 간의 간극을 연결할 수 있도록 설계된 Framework를 제안한다. 또한 모델이 해당 Representation을 더 잘 이해할 수 있도록 Motion 및 Video, Caption, Instruction 데이터를 대규모로 포함하는 MoVid 데이터 셋과 MoVid-Bench를 구축하였다.
한계점으로는 Video Encoder의 Capacity가 제한적이라는 점이 있으며, 추후 응용분야로는 피트니스 코치, 시각장애인 보조 도우미 등의 Assistant 기능을 수행할 수 있다.
핵심적인 부분 위주로 논문을 정리해 보았다. 방법론 자체가 엄청나게 획기적이라기보다는 이 모듈 저 모듈을 잘 결합하고, 데이터 셋과 모델 학습 및 평가방법을 구축하는데 정말 공을 많이 들인 논문이라고 생각된다. 내가 이번 연구를 진행하는 데 있어 많이 참고를 하게될 논문이라고 생각되기에 실험에 사용한 데이터와 코드를 더 자세히 살펴보고자 한다.
세 줄 요약
1. Human Behavior를 통합적으로 이해하기 위해 Motion과 Video를 동시에 처리하는 통합 LLM Framework인 MotionLLM을 제안함
2. Motion, Video, Caption, Instruction 정보를 담은 대규모 멀티모달 데이터 셋인 MoVid와 평가용 벤치마크 MoVid-Bench를 구축하여 모델의 시공간 인식과 Reasoning 능력을 강화하고자 함
3. 실험 결과 MotionLLM은 기존 모델 대비 세밀한 동작 이해와 행동 추론에 있어 우수한 성능을 보임

'논문 paper 리뷰' 카테고리의 다른 글
| [Paper Review] Video-LLaVA 논문 이해하기 (0) | 2025.04.25 |
|---|---|
| [Paper Review] MotionGPT 논문 이해하기 (0) | 2025.04.17 |
| [Paper Review] InstructDiffusion 논문 이해하기 (1) | 2025.04.01 |




댓글