『 ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation. NeurIPS. 2022. 』
Convolution 기법 이후 Vision Task에서도 좋은 성능을 내고 있던 Transformer 모델이 Human Pose Estimation에서도 좋은 성능을 낼 수 있다는 것을 보여준 논문이다. 2024년 현재에도 SOTA를 기록할만큼 좋은 성능을 보이는 모델이며 2D Human Pose Estimation의 연구가 3D나 Mesh 쪽으로 많이 이동한 현 시점에서 2D Joint만큼은 가장 잘 예측하는 모델이라는 설명을 붙일 수 있을 것 같다. 따라서 이번에는 어떻게 이 모델이 Transformer의 장점을 Human Keypoint를 찾는데 사용하였는지 그 방법에 대해 알아보도록 하자.
Github
https://github.com/ViTAE-Transformer/ViTPose
GitHub - ViTAE-Transformer/ViTPose: The official repo for [NeurIPS'22] "ViTPose: Simple Vision Transformer Baselines for Human P
The official repo for [NeurIPS'22] "ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation" and [TPAMI'23] "ViTPose++: Vision Transformer for Generic Body Pos...
github.com
0. Abstract
Vision Transformer 모델이 등장한 이후 여러 Vision Task에서 좋은 성능을 보이고 있지만 아직 Pose Estimation Task에서는 그러지 못하였다. 따라서 본 논문에서는 Pose Estimation에 사용된 Vision Transformer 모델을 공개하며 이 모델은 아래와 같은 장점을 가진다.
- Simplicity (plain & non-hierarchical vision transformer 사용)
- Scalability (parameter 수를 100만 ~ 10억까지 조정)
- Flexibility (attention type, resolution, pretrain-finetuning strategy에 있어 flexible)
- Transferability (모델 간의 지식 전달)
이러한 장점들을 통해 SOTA를 이루어 낼 수 있었다.
1. Introduction
최근 Vision Transformer를 Pose Estimation에 적용하려는 시도가 존재했다. 하지만 이들은 대부분 CNN 모델을 Backbone으로 사용하고 Transformer를 그 이후에 사용하는 모델들로 디자인되었다.
예시
PRTR : Transformer의 Encoder와 Decoder를 통합하여 추정된 Keypoint를 Cascade 방식으로 점진적 개선
TokenPose, TransPose : CNN으로 Feature Map을 추출하고 Transformer Encoder로 이를 처리
HRFomer : High-Resolution Representation Representation을 도입하여 Multi-Resolution Parallel Transformer를 구축
하지만 이러한 방법들은 Feature Extractor로 CNN을 사용하거나 Transformer 구조를 신중하게 설계해야 한다는 단점이 있다. 본 논문은 이러한 단점 극복을 위해 Plain Vision Transformer 모델을 사용해 Pose Estimation 성능을 높이려 하였다.
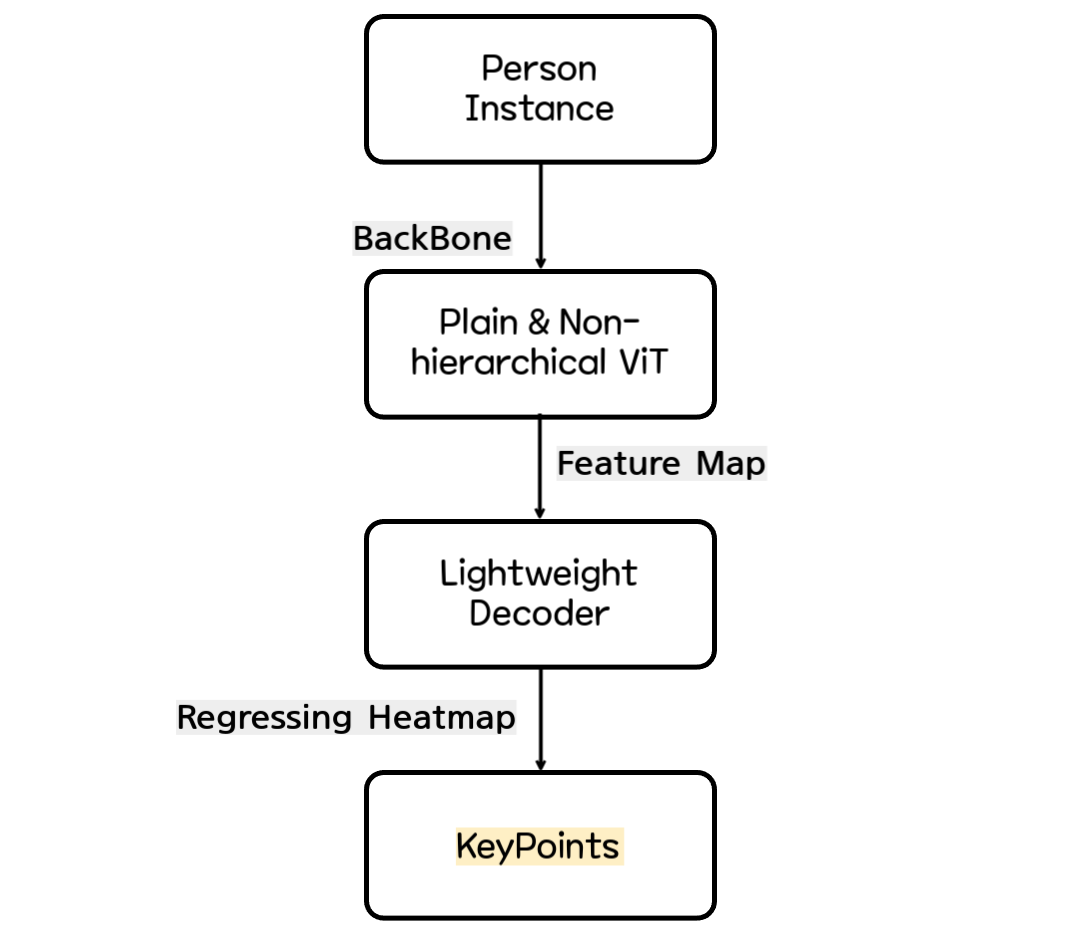
ViTPose의 대략적인 구조는 위와 같다.
- 주어진 Person Instance에서 Feature Map을 잘 뽑아내기 위해 Plain & Non-hiearchical Vision Transformer를 Backbone으로 사용한다.
- 그렇게 얻어진 Feature Map을 가지고 Lightweight Decoder를 통과시킨다. Lightweight Decoder는 Feature Map을 Upsampling하고 Heatmap을 Regressing하여 Keypoint를 예측한다.
이를 통해 COCO 데이터 셋에서 좋은 결과를 얻었으며 이렇게 좋은 성능을 낼 수 있었던 것은 Simplicity, Scalability, Flexibility, Transferability 4가지 장점 덕분이었다.

1) Simplicity
ViT 모델의 강력한 Feature Representation Ability 덕분에 ViTPose는 단순한 구조를 가질 수 있었다. ViT Backbone을 사용하기 위해서는 어떠한 도메인 지식도 필요하지 않다. 단순히 여러겹의 Transformer Layer를 쌓는것만으로 효과적인 Encoder를 구축할 수 있으며 Decoder 또한 성능 저하 없이 하나의 Upsampling Layer와 Convolution Layer로 단순화 할 수 있다. 이러한 구조적인 Simplicity를 통해 ViTPose는 더 나은 병렬성을 가지며 추론 속도와 성능 측면에서 새로운 Pareto Front를 달성한다.
도메인 지식이 필요하지 않는다는 것은 장점으로 작용할 수 있지만 한편으로는 ViT가 가지는 낮은 Inductive Bias 문제를 해결하지 못한 것으로 볼 수 있을 것 같다. 이 점을 극복한다면 더 높은 정확도를 노려볼 수 있을지...
※ Pareto Front
: 모든 목표를 고려했을 때 최선의 타협점을 보여주는 솔루션 집합
2) Scalability
Simplicity는 ViTPose의 뛰어난 Scalability를 야기한다. 원하는 개수만큼 Transformer Layer를 쌓고, 특정 차원을 증가시키거나 감소시키는 것으로 ViT-B, ViT-L처럼 모델 크기를 쉽게 조절할 수 있다.
3) Flexibility
ViTPose는 Training Paradigm이 매우 유연하다. 약간의 수정만으로도 다양한 해상도에 잘 적응할 수 있으며 더 높은 해상도의 Input에 대해 더 정확한 Pose Estimation 결과를 제공한다. Decoder는 Lightweight하기 때문에 계산 비용이 거의 들지 않으며 유연하게 Decoder를 변형하여 여러 Pose 데이터 셋에 맞게 모델을 수정할 수도 있다.
4) Transferability
큰 ViTPose 모델의 지식을 작은 ViTPose 모델에 전달하는 것으로 작은 ViTPose 모델의 성능을 쉽게 향상시킬 수 있다.
결국 본 논문의 Contribution은 다음과 같다.
- 정교하거나 복잡한 Framework를 사용하지 않고 간단한 구조로 이루어진 ViTPose 모델을 제안
- Simplicity, Scalability, Flexibility, Transferability의 장점을 가진다.
- 큰 Vision Transformer 모델을 Backbone으로 사용하는 등 인기 있는 benchmark에 대한 많은 실험을 진행하였다.
2. Related work
2.1. Vision transformer for pose estimation
여기서는 Pose Estimation Task에 ViT 모델을 활용한 기존 연구를 정리한다(Abstract 모델과 동일).
기존 연구들은 ViT를 Pose Estimation의 Decoder 역할을 하는 모델로 사용하려 헀다(TransPose, TokenPose). 그러던 중 등장한 HRFormer는 Transformer를 사용하여 High-resolution feature를 직접 추출하기도 하였다. 하지만 이러한 방법들은 Plain Vision Transformer로 진행한 연구가 아니기 때문에 본 논문에서는 Plain Vision Transformer를 사용하여 단순하고 효과적인 모델을 만들고자 하였다.
2.2. Vision transformer pre-training
ViT의 성공에 따라 다양한 ViT Backbone들이 제안되었으며 최근에는 Plain Vision Transformer를 학습시키기 위한 Self-Supervised Learning 기법 또한 등장하였다. Masking Image Modeling(MIM) 기법을 Pre-training에 사용하여 좋은 Initialization을 제공하며 본 논문에서는 Pose Estimation을 위한 Pre-training이 필수적인지 확인하여, 작은 unlabelled된 Pose 데이터셋을 가지고 Pre-train을 하더라도 좋은 Initialization이 발생한다는 것을 발견하였다.
3. ViTPose

3.1. The simplicity of ViTPose
결국 본 논문의 목표는 ViT를 활용하여 간단하고 효과적인 Pose Estimation 모델을 만드는 것이다. 따라서 Plain ViT 모델을 Backbone으로 사용하고 뒤에 Decoder를 단순히 추가하여 Keypoint Heatmap을 추정하도록 하였다[Figure 2 (a)].
단순함을 위해 Decoder에 Skip Connection이나 Cross Attention을 사용하지 않았고 대신 간단한 Deconvolution Layer와 Prediction Layer만을 사용했다.
구체적으로 설명하면 Person Instance $X\in \mathcal{R}^{\mathcal{H}\times\mathcal{W}\times3}$을 Input으로 받을 때
- 우선 Patch Embedding Layer를 통해 이미지를 Token으로 Embedding한다.
- 그렇게 되면 만들어지는 Token은 모여 집합 $F$;$F\in \mathcal{R}^{\frac{H}{d}\times\frac{W}{d} \times C}$가 된다.
C는 Embedding된 Token의 Channel 수(하이퍼파라미터) - $d$는 Patch Embedding Layer의 Downsampling 비율이며 기본적으로는 16이다(ViT 논문).
- 이후 Embedding된 토큰들은 Multi-Head Self-Attention(MHSA) Layer와 Feed Forward Network(FFN)으로 구성된 여러 Transformer Layer를 거쳐 처리된다[Figure 2 (b)].
$$F'_{i+1} = F_i + MHSA(LN(F_i)), \quad F_{i+1} = F'_{i+1} + FFN(LN(F'_{i+1})) \quad (1) $$
여기서 $i$는 $i$번째 Transformer Layer의 Output을 의미하고 처음 들어가는 feature인 $F_0$은 Input X가 Patch Embedding을 거친 값이다. 각 Transformer Layer에서 spatial & channel 차원이 동일하기 때문에 Backbone 네트워크의 output 차원은 Input과 동일하게 $F_{out}\in \mathcal{R}^{\frac{H}{d}\times\frac{W}{d} \times C}$이 된다.
LN(Layer Normalization)
MHSA와 FFN 이전에 Layer Normalization을 적용하여 학습의 안정성과 성능 향상을 꾀함. Batch Normalization과 달리 각 샘플이 개별적으로 정규화되기 때문에 Batch 크기에 의존적이지 않다.
Backbone의 Output을 처리하기 위해 2가지 종류의 Lightweight Decoder를 사용한다.
- Classic Decoder [Figure 2 (c)]
: 2개의 Deconvolution Blcok으로 구성되며 각 Block은 하나의 Deconvolution Layer와 Batch Normalization, ReLU로 이루어져 있다. 각 Block은 기존 Feature Map을 2배씩 Upsampling 하며 이후 1x1 크기의 Kernel을 가진 Convolution Layer(Predictor)를 사용하여 Keypoint의 위치를 추정하는 Heatmap을 생성한다. - Simple Decoder [Figure 2 (d)]
: Classic Decoder보다 간단하고 Lightweight하게 만들기 위해 본 논문에서는 Bilinear Interpolation-ReLU-3x3 Convolution(Predictor)을 사용하여 Heatmap을 예측하도록 Decoder를 설계하였다. 이렇게 하면 성능이 뒤처지지 않고도 단순하게 Decoder를 구성할 수 있다.
3.2. The scalability of ViTPose
ViTPose는 구조가 단순하기 때문에 다양한 수의 Transformer Layer를 쌓거나 Feature Dimension을 조정하는 것으로 모델 크기를 쉽게 조절할 수 있다. 이 덕분에 실험 파트에서 ViT-B, ViT-L, ViT-H 등 다양한 크기의 모델로 만들어 실험을 진행할 수 있었다.
ViT-H와 ViTAE-G는 14 x 14 Patch Embedding을 사용하므로 Zero-Padding을 사용(16 x 16 맞추기 위해)
3.3. The flexibility of ViTPose
Pretraining data flexibility
지금까지 많은 모델이 좋은 Initialization을 위해 ImageNet을 가지고 Pretraining을 진행하였다. 하지만 본 논문에서는 Flexibility를 확인하기 위해 MS COCO와 AI Challenger 데이터 셋만으로(ImageNet보다 그 수가 적음) 경쟁력 있는 성능을 달성할 수 있었다. 이는 ViTPose가 다양한 규모의 데이터로부터 Flexible하게 좋은 Initialization을 수행한다고 볼 수 있다.
Resolution flexibility
ViTPose의 입력 이미지 크기와 DownSampling 비율 d를 다양하게 조정하는 것으로 Resolution에 대한 Flexibility를 평가한다.

해상도가 달라지더라도 그에 맞게 DownSampling 비율, Patch Embedding Layer의 Stride 등을 바꾸어가며 Table 4와 같이 다양한 Resolution에서 Flexible한 결과를 보였다.
Attention type flexibility
고해상도 Feature Map에서 전체 Attention을 수행하는 것은 많은 메모리 소모와 Computational Cost를 발생시킨다. 이러한 문제를 완화하기 위해 상대 위치 기반의 Window-based Attention이 등장하였지만 모든 Transformer Block에서 Window-based Attention을 사용하는 것은 Global Context 모델링 능력이 부족하여 성능을 많이 저하시킨다.
따라서 본 논문에서는 2가지 기술을 채택하였다.
- Shift Window : 고정된 Window를 사용하여 Attention을 계산하는 대신 Shift-Window 매커니즘을 사용하여 인접한 Window들의 정보를 같이 활용한다(Swin Transformer 기법).
- Pooling Window : 각 Window의 Token을 Pooling하여 Window 내에서 Global Context Feature를 얻는다. 이후 얻은 Feature들을 각 Window에 Key와 Value 토큰으로 사용하여 Feature간 Communication을 가능하게 한다.
이 부분은 코드를 봐야 이해할 것 같다...
위 두 방법이 서로 보완적이고 Attention 계산에 대해 조금 수정한 것만으로 성능을 개선하고 메모리 소모를 줄였다.
단순히 다른 기법을 사용했다는 건데 이게 왜 Flexibility하다는 건지...? 성능을 개선하면 Flexible 한 것인가...
Finetuning flexibility
기존 NLP 분야에서 "Pretrain된 Transformer 모델은 부분적인 파라미터 튜닝만으로 다른 Task에 잘 일반화될 수 있다"는 것이 입증되었다. 이를 Vision Transformer에서도 잘 적용되는지 확인하기 위해 본 논문에서는 MS COCO 데이터 셋을 가지고 3가지 방법으로 FineTuning하였다.
(1) 모든 파라미터를 Unfrozen
(2) MHSA 모듈을 Frozen
(3) FFN 모듈을 Frozen
실험을 통해 ViTPose는 MHSA 모듈을 Frozen한 경우가 모든 파라미터를 Unfrozen한 결과와 유사한 것을 확인할 수 있었다.
Task flexibility
ViTPose에서 Decoder가 매우 Lightweight하기 때문에 Backbone Encoder 하나에 여러 Decoder를 사용할 수 있다[Figure 2 (e)]. 따라서 여러 Pose Estimation Dataset을 같이 다룰 수 있으며 이 경우 각 Iteration마다 여러 Train Dataset에서 Instance를 무작위로 Sampling하고 Heatmap을 추정한다.
3.4. The transferability of ViTPose
작은 모델의 성능을 향상시키는 일반적인 방법은 Knowledge Distillation이다. 일반적인 Knowledge Distillation은 Student 네트워크의 출력이 Teacher 네트워크의 출력을 따라하도록 강제하는 방식으로 이루어지는데, 본 논문에서는 살짝 변형하여 Token 기반의 Knowledge Distillation 기법을 사용하였다.
보통 Output Distillation Loss를 추가하는 방식으로 Knowledge Distillation이 수행된다.
$$Loss = MSE(K_s, K_t)$$
구체적으로는 학습 가능한 Knowledge token $t$를 무작위로 초기화하고 Teacher 네트워크의 Patch Embedding Layer 이후의 Visual Token에 추가한다. 그리고는 잘 학습된 Teacher 네트워크를 Freeze한 후 몇 Epoch 정도 Knowledge Token만을 조정하여 Knowledge를 얻는다.
$$t^* = \operatorname*{argmin}_{t}(MSE(T({t;X}), K_{gt})$$
- $K_{gt}$ : Ground Truth Heatmap
- $X$ : Input Images
- $T({t;X})$ : Teacher 네트워크의 예측
- $t^*$ : Loss를 최소화하는 최적의 Token
이후 Knowledge Token $t^*$는 Freeze되어 Student 네트워크가 학습되는 동안 Visual token과 연결되어 Teacher 네트워크에서 Student 네트워크로 지식을 전달한다.
Student 네트워크의 Loss는 다음과 같다.
$$L^{td}_{t\rightarrow s} = MSE(S({t^* ; X}), K_{gt}) \quad or \quad L^{tod}_{t \rightarrow s} = MSE(S({t^* ; X}), K_t) + MSE(S({t^* ; X}), K_{gt})$$
- $L^{td}_{t \rightarrow s}$ : Token Distillation Loss
- $L^{tod}_{t \rightarrow s}$ : Output Distillation Loss + Token Disttillation Loss
4. Experiments
4.1. Implementation details
ViTPose는 Top-Down 기반의 모델이다. A100 8개를 사용해서 학습하였으며 MMPose의 Training Setting을 사용하였다. Backbone은 MAE(Masked autoencoders are scalable vision learners) 방식으로 초기화하였고 Input 해상도는 256x192, Optimizer는 AdamW, Learning Rate는 5e-4, Post Processing에는 UDP(Delving into unbiased data processing for human pose estimation) 기법을 사용하였다.
자세한 Detail은 논문을 참고하길 바란다.
4.2. Ablation study and analysis

위 Table 2는 사용한 Backbone과 Decoder에 따른 COCO dataset 실험 결과이다. ResNet을 사용했을 때에는 Classic Decoder와 Simple Decoder의 성능 차이가 많이 났지만 ViTPose에서는 두 Decoder의 차이가 작았다.
👉 구조가 단순한 Simple Decoder(3.1. 참고)를 사용하더라도 비슷한 성능을 보인다(복잡한 Decoder 필요 X).
또한 모델의 크기가 커짐에 따라 성능이 일관되게 향상하는 것을 볼 수 있어 ViTPose 모델의 뛰어난 Scalability를 확인할 수 있다.
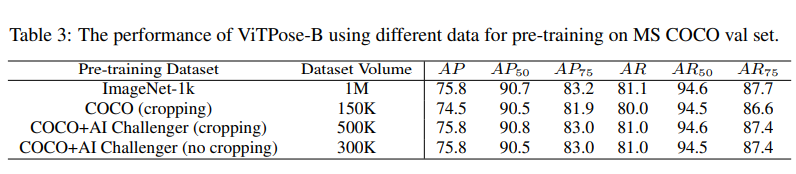
위 실험은 ImageNet으로 Pretrain을 할 필요가 없다는 것을 보여주는 실험이다(3.3. 참고). ImageNet-1k 데이터 셋의 Volume이 훨씬 큼에도 불구하고 COCO와 AI Challenger 데이터 셋을 같이 사용하여 Pretrain한 결과와 비슷하다는 것을 확인할 수 있다.
👉 더 적은 데이터로 Pretrain하더라도 비슷한 성능을 보인다.

위는 Attention Type에 대한 실험 결과이다. HRNet과 HRFormer에서 입증되었듯이 고해상도 Feature Map이 Pose Estimation Task에 유리하기 때문에 ViTPose에서는 Patch Embedding Layer의 다운샘플링 비율을 16 -> 8로 줄였다. 하지만 이로인해 발생하는 메모리 부족 문제를 완화하기 위해 Attention 기법에 조정을 주었다.
당연히 Full Attention을 사용할 때의 성능이 가장 좋았지만 그만큼 Memory를 많이 차지했고 Window, Shift, Pooling window 매커니즘을 사용하여 Window Size를 16 x 12로 확장하였을 때의 성능이 가장 좋았다(메모리를 절약한 방법들 중에).

위는 3.3.의 Finetuning flexibility를 확인하기 위한 실험이다. 위에서부터 전체 Fine Tuning, MHSA Frozen, FFN Frozen을 한 결과이고 MHSA를 Frozen했을 때의 성능이 전체를 Fine Tuning 하였을 때와 비슷한 것을 확인할 수 있다.
👉 FFN 모듈이 더 Task-Specific한 모델링에 큰 역할을 하며 MHSA 모듈은 다소 Task-Agnostic 하다.

COCO 데이터 셋만으로 학습한 결과보다 AI Challenger, MPII 데이터 셋을 같이 활용하여 학습했을 때의 결과가 조금이나마 좋은 것을 확인할 수 있다. 이는 ViTPose 모델이 서로 다른 데이터 셋의 다양한 데이터를 잘 활용할 수 있음을 나타낸다.

위는 ViTPose의 Transferability를 알아보는 실험이다. ViTPose-L -> ViTPose-B로 Knowledge Distillation을 시도하였으며 Token기반의 Distillation은 메모리 사용량을 거의 증가시키지 않으며 성능을 향상시켰고, Output 기반의 Distillation은 메모리 사용량은 다소 늘어났지만 더 크게 성능을 향상시켰다.
두가지 방법을 모두 사용하였을 때의 성능이 가장 높은 것을 보아 두가지 Distillation 방법이 서로 보완적이며 ViTPose 모델은 뛰어난 Transferability를 가진다고 볼 수 있다.
4.3. Comparison with SOTA methods

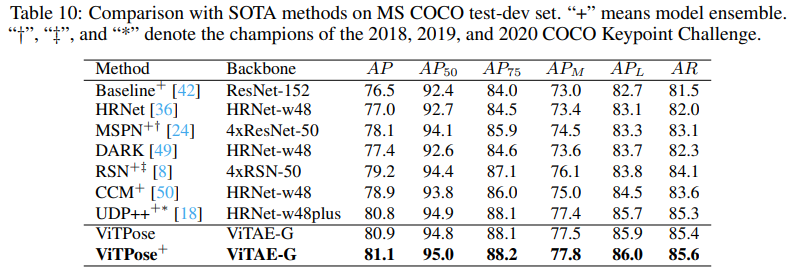
256 x 192 해상도의 입력 이미지와 다중 데이터 셋 훈련 방식을 통해 COCO val과 test 데이터 셋에서 우수한 성능을 기록하였다. 이를 통해 Scalability와 Flexibility를 확인할 수 있으며 단순한 Vision Transformer 모델로 Pose Estimation Task에서 좋은 Feature를 Encoding할 수 있다는 것을 입증하였다.
Backbone으로는 1B 개의 파라미터를 가지는 ViTAE-G를 사용하였고 이를 통해 ViTPose는 80.9 AP라는 SOTA를 기록하였다. 3개지 모델을 앙상블한 ViTPose+는 81.1 AP까지 성능을 보이기도 하였다.
4.4. Subjective results

Figure 3과 같이 ViTPose는 Occlusion, 다양한 자세 상황이더라도 정확한 Pose Estimation 결과를 추론한다.
5. Limitation and Discussion
- 복잡한 Decoder나 FPN 구조를 사용하여 ViTPose의 잠재력을 더 탐구해보지 않았다.
- Flexibility를 더 입증하기 위한 추가 연구가 필요하다(ex. Prompt Tuning)
- 사람 이외의 동물이나 Face Keypoint Detection과 같은 데이터 셋에도 잘 적용될지 확인이 필요하다.
6. Conclusion
Vision Transformer 모델을 기반으로 간단한 구조로 설계한 ViTPose 모델을 제안한다. Simplicity, Scalability, Flexibility, Transferability의 장점을 가지며 COCO 데이터 셋에서 SOTA를 기록하였다.
세 줄 요약
1. Pose Estimation Task에 Vision Transformer 모델를 접목한 ViTPose 모델을 제안하였다.
2. Simplicity, Scalability, Flexibility, Transferability라는 장점을 가지며 Simple한 Decoder, 적은 pretrain data 등 성능이 높으며 구조가 단순하도록 모델을 설계하였다.
3. 그 결과 다양한 데이터로 학습을 하더라도 좋은 성능을 보였으며 특히 COCO 데이터 셋에 대해서는 SOTA를 기록하였다.

'논문 paper 리뷰' 카테고리의 다른 글
| [Paper Review] DeepPose 논문 이해하기 (2) | 2024.09.02 |
|---|---|
| [Paper Review] MIPNet 논문 이해하기 (0) | 2024.08.28 |
| [Paper Review] Stable Diffusion 논문 이해하기 (0) | 2024.08.14 |




댓글