『Multi-Instance Pose Networks: Rethinking Top-Down Pose Estimation. ICCV. 2021. 』
여러 2D Pose Estimation 모델들을 실행하보면 은근 성능이 좋다는 걸 느낄 수 있다. 하지만, 대부분의 Pose Estimation 모델들이 성능이 확 떨어질 때가 발생하는데 이는 사람의 신체가 Occlusion 되었을 때이다. 이 경우에는 모델이 우리 신체를 전부 잡기 위해 내가 위치하지도 않은 곳에 신체가 위치해있다고 말하는 경우가 많은데, MIPNet이라는 모델은 이러한 Occlusion 문제를 해결하기 위해 등장한 모델이다.
기존 2D Human Pose Estimation에서 발생하는 Occlusion 문제를 완화하여 Occlusion 현상을 가정한 CrowdPose, OCHuman 데이터에서 좋은 성능을 보였다하니 어떻게 그러한 성능을 이끌어냈는지 지금부터 확인해보도록 하겠다.
Github
https://github.com/rawalkhirodkar/MIPNet
GitHub - rawalkhirodkar/MIPNet
Contribute to rawalkhirodkar/MIPNet development by creating an account on GitHub.
github.com
0. Abstract
Human Pose Estimation에서 Top-Down 기법의 주요한 가정은 주어진 Bounding Box 속에 한 명의 사람이 있을 것이라는 것이다. 하지만 이러한 가정 때문에 종종 Occlusion된 이미지(ex. Crowd Scene)에서 잘못된 예측이 발생한다.
본 논문에서 제안하는 MIPNet은 위와 같은 가정에 변화를 주어 주어진 Bounding Box에서 여러 객체의 2D Pose Instance를 예측한다. MIMB(Multi-Instance Modulation Block)를 사용하여 Channel별 Feature의 Response를 조절하는 것으로 이를 가능케 했다.
Occlusion 상황을 가정한 CrowdPose, OCHuman 데이터 셋에서 특히 좋은 성능을 보였다.
1. Introduction

Pose Estimation에는 대표적인 두가지 방법론이 존재한다. 첫번째 방법론인 Top-Down 기법은 이미지 속에서 먼저 사람을 Detecting하여 나온 Bounding Box에서 한 사람의 Pose를 추정하는 기법이고, 두번째 방법론인 Bottom-Up 기법은 전체 이미지에서 키포인트를 추정한 후 이 포인트들을 Grouping하는 기법이다.
본 연구에서는 주로 Top-Down 기법에서 발생하는 Occlusion 문제에 대해 접근을 하는데, 기존 Top-Down 기법은 하나의 Bounding Box 안에서 하나의 Instance를 찾기 때문에 하나의 Bounding Box 안에 여러 사람이 존재할 경우에도 한 명의 사람만을 예측하는 문제를 대표적으로 이야기하고 있다. 위에 있는 Figure 1에서 이와 같은 문제를 확인할 수 있으며 이러한 Occlusion 상황에서 기존의 모델은 앞에 있는 사람의 Pose를 예측한다고 한다.
위와 같은 문제를 쉽게 해결하는 방법으로는 하나의 Bounding Box 당 Pose 모델을 여러번 돌려 예측하는 것이지만, 이 경우 다른 Feature를 학습하는 것이 어렵고 Parameter가 증가하여 그다지 효율적이지 않다. 따라서 본 논문에서는 Top-Down 모델 아키텍처가 하나의 Bounding Box에서 Multiple Pose를 예측할 수 있도록 아키텍처를 디자인하였다. 본 연구에서 제안한 방법은 3%가 채 안되는 Parameter의 증가와 16% 미만의 Inference Time 증가만으로 Multiple Instance 예측을 가능케 했다.

이러한 성능을 낼 수 있었던 데에는 본 논문에서 제안한 MIMB(Multi-Instance Modulation Block)의 도움이 컸다. 이 모듈은 Instance 선택기의 역할을 하는 $\lambda$를 기반으로 Feature Tensor를 조정하여 N개의 Instance 중 하나를 인덱싱하게 만든다. 즉, $\lambda$ 값을 활용하여 하나의 Bounding Box 내에 있는 Multiple Instance를 잘 예측하게 돕는 것이다(Figure 2 참고). 또한 MIMB는 존재하는 Feature-Extraction Bacbone 모델들에 15라인이 안되는 코드의 변화만으로 합칠 수 있다는 장점 또한 가진다.
👉 하나의 Bounding Box가 주어졌을 때, Instance-Selector인 $\lambda$를 바꿔가며 Multiple Pose를 예측

대표적인 Top-Down 모델인 HRNet은 Faster R-CNN 모델에서 만들어진 100,000개가 넘는 Bounding Box를 사용한다. 이와 같이 대부분의 Top-Down 방법론은 Object Detector의 Output을 입력으로 받기 때문에 수많은 후보 Bounding Box들을 가지는데, 이러한 방법은 Inference Time과 성능에 좋지 않은 영향을 끼친다.
이러한 성능 감소는 Figure 5에서 볼 수 있으며, 본 연구에서 제안하는 MIPNet 대비 HRNet의 Performance가 전체적인 성능 뿐만 아니라 Confidence Score를 올렸을 때의 AP 감소 폭이 큰 것을 확인할 수 있다.
이 뿐만 아니라 MIPNet은 Challenging Dataset인(Occluded 하기 때문에) CrowdPose와 OCHuman 데이터 셋에서도 좋은 성능을 보였으며, 본 연구에서 제안하는 Contribution은 다음과 같다.
- 하나의 Bounding Box에서 한 명의 사람만을 뽑아내는 기존의 방법론을 발전시켜 여러명을 예측할 수 있게 만들었다. 따라서 CrowdPose와 OCHuman 데이터 셋에서 좋은 성능을 얻을 수 있었다.
- 각 Instance에 대한 Feature Response를 독립적으로 조정하여(by $\lambda$) 여러 Pose Instance를 잘 예측할 수 있었다.
- 이렇게 여러명을 예측할 수 있는 능력은 Bounding Box Confidence를 Resilient하게 만들고 누락된 Bounding Box 또한 처리할 수 있게 돕는다.
2. Related Work
Biased Benchmarks
대부분의 Pose Estimation 모델들은 실제 세상에서 나타나는 모든 Pose와 Occlusion을 대변하지 못한다. COCO와 MPII같이 인기있는 데이터 셋들은 IoU 0.3에서 Occlusion(Crowding)이 발생하는 비율이 3% 미만이고 COCO의 86% 이상은 5개 이상의 Keypoint Annotation을 가진다. 그만큼 지금까지 공개된 모델들은 Occlusion이 발생하지 않는 쪽으로 편향되어 모델 학습이 진행되었고, 따라서 OCHuman이나 CrowdPose와 같이 Occlusion이 많은 데이터에서의 성능이 좋지 않았다.
Top-Down Methods
Top-Down 기법은 Bounding Box 안에서 한 사람의 Keypoint를 예측하는 방법론이다. Top-Down 방식은 Bounding Box 내의 모든 인물을 동일한 크기로 정규화 할 수 있기 때문에 이미지의 크기 변화에 덜 민감하다는 장점을 가진다. 하지만 Top-Down 방식은 Bounding Box 내에 한 명의 사람만이 존재한다는 전제를 가지고 있어 Multi-Person일 때나 Occlusion이 발생할 때 종종 성능이 떨어진다. MIPNet은 하나의 Bounding Box 내에서 여러 Instance를 예측하는 것으로 이러한 문제를 극복하였다.
Occluded Pose Estimation
기존 Occlusion이 발생한 사람의 Pose를 예측하는데에는 여러가지 방법론이 존재한다.
- Top-Down 모델을 사용하여 다중 Peak를 예측한 후 Graph 모델로 이 Peak들을 그룹화하는 방법
- Instance Segmentation을 사용하여 Occlusion 추론을 진행하는 방법
- Graph Neural Network를 사용하여 Top-Down 모델에서 생성된 Pose Proposal(예상된 자세)을 개선하는 방법
- Bottom-Up 방식으로 관절을 Grouping 하기 위해 미분 가능한 계층적 Graph Grouping을 사용하는 방법
여기서 Peak는 Heatmap에서 특정 신체 부위의 위치를 가장 잘 잘 나타내는 지점을 뜻한다.
머신러닝에서 많은 모델들이 Conditional Input 별로 다르게 동작하도록 학습되었다. 하지만 이렇게 하기 위해 여러 모델을 학습시키는 것 대신 본 연구에서는 MIMB를 사용하여 동일한 입력에 대해 여러가지 출력을 예측할 수 있도록 네트워크를 구축하였다. 본 연구에서 활용한 Multi-Instance Pose Network(Supervised Learning)는 Multi-Instance Learning(Weakly Supervised Learning)과 다르다는 것을 강조하고 있다.
3. Method

Human Pose Estimation은 Input으로 이미지를 받으면 K개의 Keypoint를 예측하는 것을 목표로 한다. 대부분의 Top-Down 모델들은 이러한 문제를 K개의 Heatmap을 추정하는 문제로 변환하며, 여기서 Heatmap은 해당 Keypoint가 특정 위치에 존재할 확률을 의미한다.
키포인트 위치를 감지하기 위한 Convolution 기반의 Pose Estimator P를 정의해보자. 학습 및 추론시 Bounding Box가 H x W 크기로 스케일되어 P의 Input으로 들어간다(이전에 Detector가 돌아서 BBox를 추정). 이후 정답 Keypoint에 해당하는 K개의 Heatmap과 P를 거쳐 나온 예측 Heatmap 세트를 MSE로 최소화해나가며 학습을 진행한다.
3.1. Training Multi-Instance Pose Network
본 논문에서는 위에서 정의한 Top-Down Pose Estimator인 P를 수정하여 여러 Instance를 예측하도록 제안한다. 본 논문에서 제안하는 P는 입력 x에 대해 N개의 Instance $\hat{y}_0 ~ \hat{y}_{N-1}$을 예측하며 이는 Instance Selector인 $\lambda$ 값에 따라 조정된다(0<=$\lambda$<=N-1). 다시 말해 P는 Bounding Box를 거친 Input x와 $\lambda$를 입력으로 받아 $\hat{y}_i$를 예측한다.
$B_0$은 Input x를 자르기 위해 사용된 정답 BBox를 의미하며, $B_i$는 $B_0$과 겹치는 n-1개의 정답 BBox를 의미한다. 이 때 겹치는 기준은 최소 k=3개의 Keypoint가 $B_0$에 위치하는지 여부로 판단하였다. 결국 $B_0 ~ B_{n-1}$는 모두 n개의 정답 Pose Instance에 대한 BBox를 나타내며 이 n개의 Instance에 대한 정답 Heatmap을 $y_0 ~ y_{n-1}$로 나타낸다.
- $n$ : Ground Truth Pose Instance의 개수
- $N$ : 모델이 예측한 Pose Instance의 개수
- $\hat{y}_0 ~ \hat{y}_{N-1}$ : 모델이 예측한 N개의 Instance에 대한 Heatmap
- $B_0 ~ B_{n-1}$ : Ground Truth BBox n개
- $y_0 ~ y_{n-1}$ : Ground Truth Heatmap n개
Loss를 정의하기 위해 Predicted Pose Instance를 Ground Truth Heatmap에 할당해야 한다. $\hat{y}_0$은 $B_0$에 해당하는 $y_0$에 할당되고, 다음 N-1개의 Instance는 각각의 BBox와 $B_0$까지의 거리에 따라 정렬한 후 남은 정답 Heatmap에 할당된다.
네트워크 P에 대한 학습은 Loss = $ \frac{1}{N}\sum_{i=0}^{N-1}\mathcal{L}_i $가 최소화되도록 학습한다.

모델이 예측한 Pose Instance 개수 $n$과 Ground Truth Pose Instance 개수 $N$의 차이에 따라 아래와 같이 계산방법이 나뉜다.
- $n$ <= $N$일 경우(GT보다 모델이 예측한 Instance 개수가 많을경우)
- 예측한 Pose Instance 중 n개에 대해서만 Prediction Loss를 계산하며 남은 $N-n$개의 Instance에 대한 Loss는 $y_0$을 Ground Truth로 추가하여 계산한다(짝꿍이 없는 애들의 짝을 $y_0$으로 만들어서 Loss 계산).
- $n$ > $N$일 경우(GT보다 모델이 예측한 Instance 개수가 적을경우)
- $B_0$과 가까운 N개의 정답 Pose Instance만 Loss 계산에 사용한다.
3.2. Multi-Instance Modulation Block
이번 챕터에서는 본 논문에서 핵심적인 방법론으로 제안하고 있는 MIMB(Multi-Instance Modulation Block)에 대해 설명한다. MIMB는 기존 Feature를 추출하는 Backbone 모델에 쉽게 도입할 수 있으며 Top-Down Pose Estimator가 입력 이미지 x로부터 여러 Instance를 예측할 수 있게 해준다. MIMB의 설계는 Squeeze-and-Excite 블록에서 영감을 받았다(SENet).
Squeeze-and-Excite Block은 여러 Feature Map 중 어떤 Feature Map이 중요한지를 알려주는 역할을 한다.
Figure 3의 오른쪽에 나타난 것처럼 Instance Selector $\lambda$를 사용하여 Excite 모듈의 출력에 대한 Channel-wise activation을 조절한다. MIMB는 동일한 Convolution Filter를 사용하더라도 입력의 다양한 Instance에 동적으로 대응할 수 있다는 장점을 가지며 Feature Backbone을 복제하거나 Instance 당 고정된 채널 수를 할당하는 방법들 대비 효율적이다.
MIMB 내의 Squeeze, Excite, Embed 연산은 $F_{sq}, F_{ex}, F_{em}$로 나타나며, $\lambda$는 Scalar의 One-Hot 형태로 표현된다. Feature map $X$는 $X' = [x'_1, x'_2, ... x'_C]$로 표현된다.
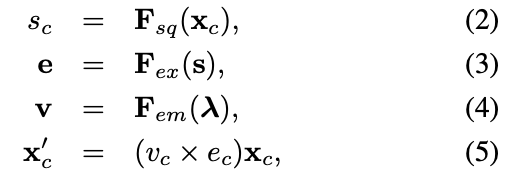
(2) : C 채널을 가지는 Feature Map을 Squeeze한다
(3) : Squeeze된 Feature Map들을 벡터로 모은 $s$에 Excite를 진행하여 $e$를 생성
(4) : $\lambda$(One-Hot 형태)를 Embedding하여 $v$를 생성
(5) : Squeeze-Excite를 거친 값 중 $\lambda$에 해당하는 값만 사용하여 해당 Channel Feature Map에 곱해줌
$F_{sq}$ : Global Average Pooling을 사용하여 Global Spatial Information을 Channel Descriptor에 Squeeze함
$F_{ex}$ : $F_{sq}$의 Output을 가지고 Channel-wise 모델링을 진행(2개의 Fully-Connected Layer)
$F_{em}$ : $\lambda$를 Embedding해준 이후 Excite 모듈의 Output과의 Channel-wise Activation을 진행. $F_{em}$은 $F_{ex}$와 비슷한 디자인을 가진다.
여기서 Activation은 One-Hot Encoding 결과와 이전 결과로 나온 벡터를 연산해주는 과정을 의미하는 것으로 보인다.
추론 과정에서는 $\lambda$를 0~N-1까지 바꾸어가며 N개의 예측 결과를 얻고 이를 합친 후 OKS-NMS를 적용한다.
4. Experiments
본 연구에서는 COCO, CrowdPose, OCHuman 3가지 데이터 셋을 활용하여 MIPNet을 평가하였다. 활용한 평가지표는 OKS(Object Keypoint Similarity)를 활용한 AP이며 Detector로는 YOLO와 Faster R-CNN을 사용하였다.
OKS에 대한 정리는 추후 진행하도록 하겠다.
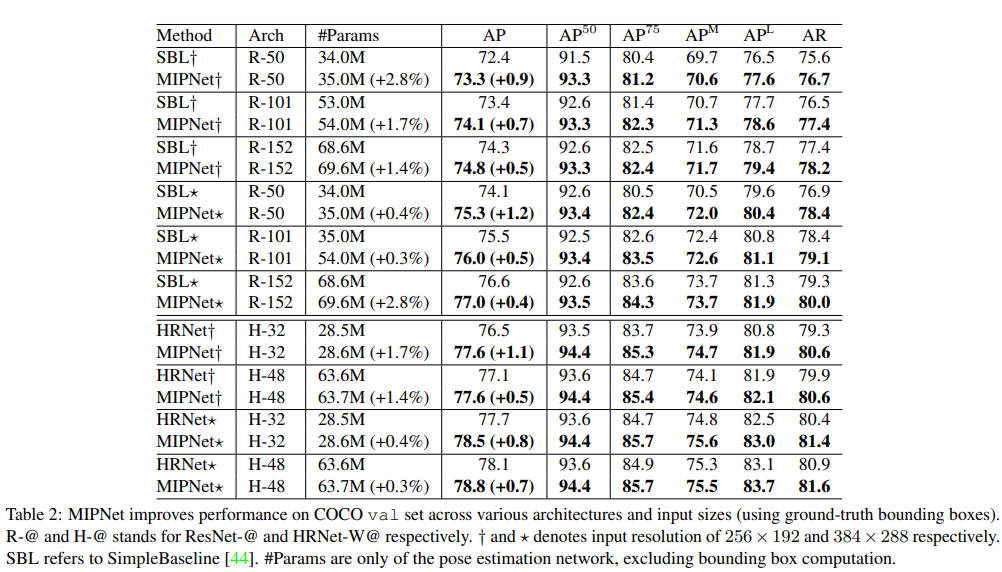
COCO Dataset은 64,000개의 이미지와 270,000명의 사람이 라벨링 되어 있는 데이터이다. SimpleBaseline(SBL)과 HRNet 모델 대비 MIPNet은 좋은 성능을 보였다.

CrowdPose Dataset은 20,000개의 이미지와 80,000며의 사람이 라벨링 되어 있는 데이터이다. 마찬가지로 CrowdPose 데이터셋에서도 MIPNet이 더 좋은 성능을 보인 것을 확인할 수 있다.
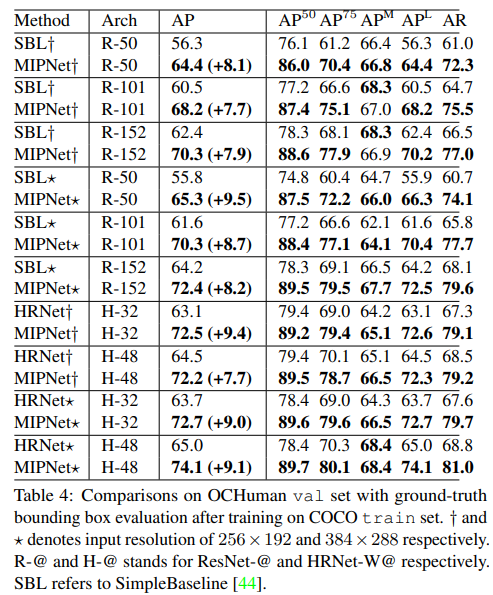
OCHuman은 4,731개의 이미지와 8,110명의 사람이 라벨링 되어 있는 데이터이다(2024/08월 기준 Github에서 확인했을 때는 5,081장). Challenging한 데이터이고 결국 이 논문에서 말하고 싶은 Occluded 상황을 가정한 데이터인데 MIPNet이 좋은 성능을 보이며 본 연구의 방법론의 효용성을 입증하고 있다.
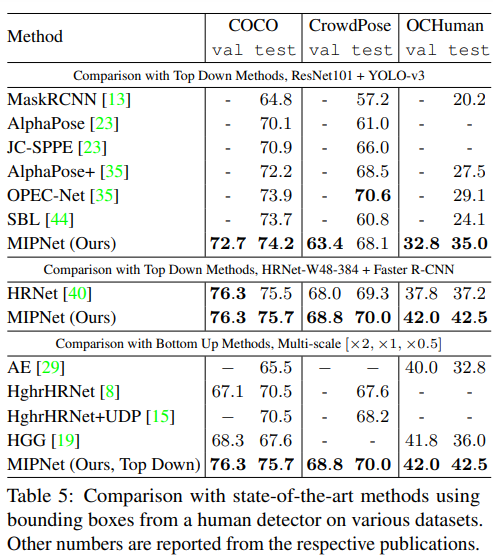
여러 데이터로 Detector를 바꾸어가며 실험을 진행한 결과는 위와 같다. CrowdPose와 OCHuman 데이터에서 좋은 성능을 보였다는 것에 주목할 필요가 있다.
CrowdPose 데이터 셋 실험 결과 중 AlphaPose+ 결과는 왜 Bold체로 표시하지 않은지 의문이다. 단순 실수?
5. Discussions

2개의 Head를 가진 모델과도 비교해 보았는데 MIPNet이 더 좋은 성능을 보였으며

위 그림에서 볼 수 있듯이(파란색이라 잘 보이지 않음.. 왜 파란색으로 했을까) $\lambda$가 0에서 1로 이동하는 동안 모델이 인식하는 Joint가 앞에 위치한 사람에서 뒤에 위치한 사람으로 이동하는 것을 확인할 수 있다.

물론 몇가지 케이스에서는 실패하는 경우도 존재했다.
6. Conclusion
본 논문에서는 기존 Top-Down 2D Pose Estimation Task에서 1개의 Bounding Box에서 1명의 사람을 추론한다는 가정을 타파하여 MIMB 모듈을 활용한 Multi-Instance Pose Estimation을 진행하였다. 때문에 매우 복잡하고 Occluded된 데이터 셋에서 좋은 결과를 얻을 수 있었다.
세 줄 요약
1. 기존 2D Human Pose Estimation Task 중 Top-Down 기법에서는 1개의 Bounding Box에 1명의 사람이 있다고 가정하여 Occlusion 상황에서 좋지 못한 성능을 보였다.
2. 따라서 본 논문에서는 SENet의 방법론에서 착안한 MIMB 모듈을 사용하여 1개의 Bounding Box에서 여러 명의 사람을 추정할 수 있도록 네트워크를 구축하였다.
3. 그 결과 CrowdPose, OCHuman과 같이 Occlusion이 많이 일어나는 데이터에서 좋은 성능을 보일 수 있었다.

'논문 paper 리뷰' 카테고리의 다른 글
| [Paper Review] ViTPose 논문 이해하기 (1) | 2024.08.30 |
|---|---|
| [Paper Review] Stable Diffusion 논문 이해하기 (0) | 2024.08.14 |
| [Paper Review] HRNet for Visual Recognition 논문 이해하기 (0) | 2024.03.24 |




댓글