『 Deep High-Resolution Representation Learning for Visual Recognition. TPAMI. 2019. 』
- 이번에는 Pose 모델의 BackBone으로 자주 활용되는 HRNet for Visual Recognition모델을 리뷰해보도록 하겠다. Segmentation Task에서도 활용가능한 모델이지만, 최근 Pose 관련 연구를 진행 중이기 때문에 이번 리뷰는 Pose Estimation Task 관련된 내용 위주로 리뷰하도록 하겠다(for Human Pose Estimation 논문 리뷰는 다음 링크를 참고).
- 코드로는 이미 여러번 활용해 본 모델이며 대강의 방법론도 알고 있었지만, 디테일 한 분석을 하기 위해 이번 논문 리뷰를 작성하였다.
- 본 논문을 읽으면서 Resolution이라는 단어를 해상도라고 직역하는게 올바른 표현인지 의문이 들었다. 이미지에서 해상도는 픽셀의 수를 이야기 하지만 논문을 읽다보면 나오는 low-resolution 속 정보는 정확히 말하면 representation 정보이지 RGB 픽셀 정보는 아니기 때문이다. 우선은 별다른 아이디어가 떠오르지 않아 리뷰에는 해상도로 적었지만, 이 글을 읽으시는 분들 중 더 나은 해석을 아시는 분이 계시다면 지식을 공유해 주시면 좋겠다. 🥹
0. Abstract
Pose Estimation, Semantic Segmentation과 같이 위치 정보에 민감한 비전 Task들에게 고해상도(High Resolution)는 필수적이다. 본 논문이 나올 당시의 SOTA모델들은 대부분 Convolution을 통해 고해상도의 이미지를 낮은 해상도의 Representation으로 Encode하고 이를 원래의 크기로 복원하는 프로세스를 많이 보였는데 본 논문에서는 대신 고해상도의 Representation을 전체 프로세스에서 유지할 수 있도록 아키텍처를 구상한 HRNet(High-Resolution Network) 모델을 제안한다.
HRNet에는 2가지 큰 특징이 존재한다. 첫 번째는 High-to-Low Resolution Convolution을 병렬로 연결하였다는 것이고, 두 번째는 프로세스 속에서 해상도에 따라 반복적으로 정보를 교환한다는 것이다. 이를 통해 Representation은 더 많은 정보를 포함하게 된다.
HRNet은 Pose Estimation, Semantic Segmentation, Object Detection 등 여러 분야에서 강력한 Backbone 모델로서 활용할 수 있다.
1. Introduction

CNN 계열의 모델은 여러 Vision Task에서 SOTA를 이루어 냈는데 그럴 수 있었던 가장 큰 이유는 풍부한 Representation을 학습한 것이다. 최근 성능이 좋았던 AlexNet, VGGNet, GoogleNet, ResNet들은 모두 Feature Map의 사이즈를 점진적으로 줄여(Convolution을 통해) 저해상도 Representation을 만든다. 이후 이를 다시 고해상도로 복원하는 방법론들이 최근 SOTA 모델로 등장하였다(Ex. SegNet, DeconvNet, U-Net, Encoder-Decoder 등).
본 논문에서는 전체 프로세스 동안 고해상도 Representation을 유지할 수 있는 HRNet을 제안한다.
BottleNet에서 발생하는 정보의 손실을 본 논문에서는 매우 부정적으로 보고 있는 것 같다.
구체적인 방법론으로는 고해상도 Convolution Stream에서 시작하여 점차 High-to-Low Resolution Convolution Stream을 하나씩 더하는 식으로, 병렬적인 Multi-Resolution Stream을 연결하였다. 이 때 Network는 K개의 Stage로 구성되며 N번째 Stage는 N Resolution과 일치하는 N Stream을 가진다. 이러한 병렬적인 Stream끼리 정보를 교환하는 식으로 Multi-Resolution Fusion을 반복한다.
이렇게 얻어진 고해상도 Representation은 의미론적으로 강할 뿐 아니라 공간적으로도 정확하다.
- 저해상도에서 고해상도로 복원하는 대신 전체 프로세스에서 고해상도를 유지하면서 학습된 Representation이 더 정확한 공간정보를 가진다.
- 저해상도 Representation을 Upsampling하는 대신 Multi-Resolution Fusion을 반복하기 때문에 High-to-Low Resolution Representation이 의미론적으로 강력하다.
본 논문에서는 2가지 버전의 HRNet을 제안한다. 1st Version은 단순히 고해상도 Convolution Stream을 거쳐 나온 고해상도 Representation으로 Heatmap Estimation을 사용하는 Pose Estimation Framework에 적용하였다. 2nd Version은 병렬적인 모든 High-to-Low Stream에서 나온 Representation을 결합한 것으로 Segmentation Map을 예측하는 Semantic Segmentation에 적용하였다.
추가적으로는 Multi-Level Representation으로 구성된 HRNetV2p를 만들어 기존 SOTA 모델들에 적용해 보았고 더 좋은 성능을 내는 것을 확인하였다.
2. Related Work
Learning Low-Resolution Representation
FCN(Fully Convolution Network)는 Classification Network를 제거하고 네트워크 만의 Coarse Segmentation Map을 예측한다.
모든 Layer가 Convolution Network일 때의 장점은 Input 이미지가 어떤 사이즈여도 상관 없다는 것이다.
Recovering High-Resolution Representations
저해상도를 고해상도 Representation으로 복원하는 방법에는 여러가지가 있다.
- VGGNet처럼 DownSample Process의 대칭으로 구성하는 방법
- SegNet처럼 Skipping Connection을 사용하는 방법
- U-Net처럼 Feature Map을 복사하는 방법
- RefineNet처럼 비대칭적인 Upsampling을 사용하는 방법
Multi-Scale Fusion
Multi-scale Map을 합치는 일반적인 방법으로는 Network를 Multiple Network로 분리하고 결과 Map을 합치는 것이다.
예를들어 Hourglass, U-Net, SegNet은 High-to-Low Downsample Process의 Low Level Feature들을 Skip Connection을 통해 Upsample Process에 합친다. PSPNet과 DeepLab의 경우 Pyramid Pooling과 Atrous Spatial Pyramid Pooling으로 얻은 Pyramid Feature들을 합친다.
기존 방법들과 HRNet의 차이점은 다음과 같다.
- Fusion Output이 1개가 아니라 K개(논문에서는 4개)
- Fusion Module이 여러번 반복된다.
Our Approach
본 논문에서 제안한 방법론은 병렬적인 Higt-to-Low Convolution Stream을 연결하는 것이다. 이를 통해 전체 프로세스에서 위치 정보를 잘 유지하며 High Resolution Representation을 얻을 수 있다.
3. High-Resolution Networks
위의 그림은 HRNet의 아키텍처 예시이다. 앞서 언급한 것 처럼 Fusion Output이 4개이며 이를 위해 4개의 stage로 구분된 것을 확인할 수 있다.
3.1. Parallel Multi-Resolution Convolutions
1st Stage에서는 고해상도 Convolution Stream으로 시작하며 점차 High-to-Low Resolution Stream을 추가하여 Multi-Resolution Stream을 병렬로 연결한다. 그 결과 다음 Stage는 [이전 단계의 해상도 + 낮은 해상도]로 구성된다.
3.2. Repeated Multi-Resolution Fusions
Fusion Model의 목표는 Multi-Resolution Representation에서 여러번 반복하며 정보를 교환하는 것이다. 위의 그림처럼 3개의 Resolution을 합친다고 했을 때, 다음에 만들어지는 Resolution의 형태는 선형 결합의 형태로 표현할 수 있다. 이 과정에서 가중치 역할을 하는 함수 f는 Input Resolution Index와 Output Resolution Index에 따라 달라진다.
3.3. Representation Head
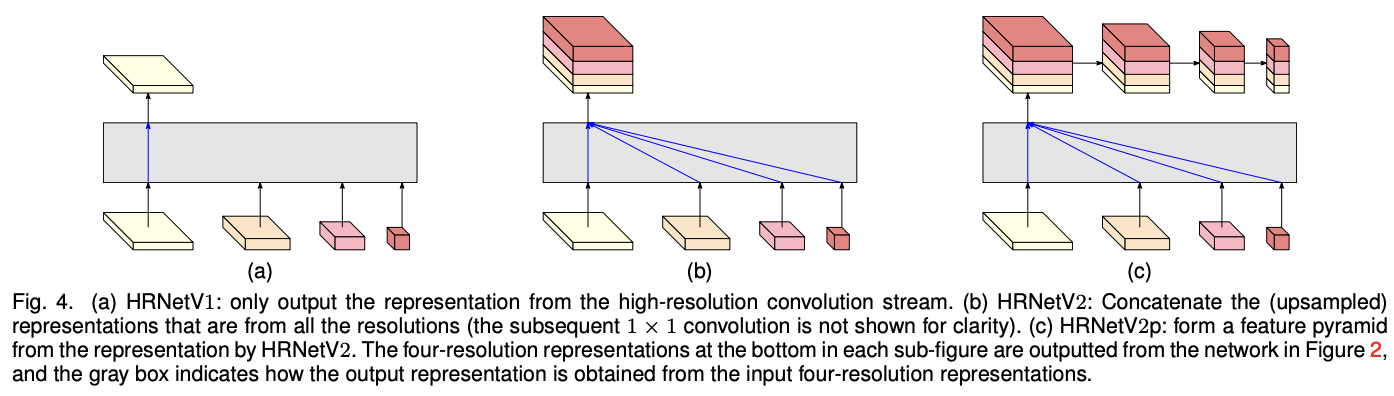
HRNetv1, HRNetv2, HRNetv2p(논문에는 HRNetv1p라고 나와있는데 오타인 것 같다) 3가지 종류의 Representation Head를 사용하였다.
- HRNetv1 : 고해상도 Stream에서 하나의 Representation만을 뽑음
- HRNetv2 : Bilinear Upsampling을 통해 저해상도 Representation의 크기를 조절하여 4개의 Representation을 연결
- HRNetv2p : HRNetv2에서 출력되는 고해상도 Representation을 Downsampling하여 Multi-Level을 표현함
HRNetv1은 Pose Estimation, HRNetv2는 Semantic Segmentation, HRNetv2p는 Object Detection에 사용하였다.
3.4. Instantiation
전체적으로 4개의 병렬 Convolution Stream으로 이루어진 4개의 Stage로 이루어져 있다. 이 때의 해상도는 각각 1/4, 1/8, 1/16, 1/32이다.
1st Stage는 4개의 Residual Unit을 포함하고 각 Unit은 Width(채널 수)가 64인 BottleNeck과 Feature Map의 width를 C로 바꾸는 3x3 Convolution으로 이루어져있다. 2, 3, 4 stage는 각각 1, 4, 3개의 모듈 블록을 포함하고 각각의 블록은 4개의 Residual Unit을 포함한다. 각각의 Unit은 해상도에 대해 2개의 3x3 Convolution을 포함한다.
3.5. Analysis
Multi-Resolution Parallel Convolution은 Group Convolution과 비슷하지만, Group Convolution은 해상도가 동일하다는 단점이 존재한다. Multi-Resolution Fusion과 일반적인 Convolution간의 연결을 통해 HRNetv2와 HRNetv2p에서 모든 해상도에 대한 Representation을 파악할 수 있다.
4. Human Pose Estimation
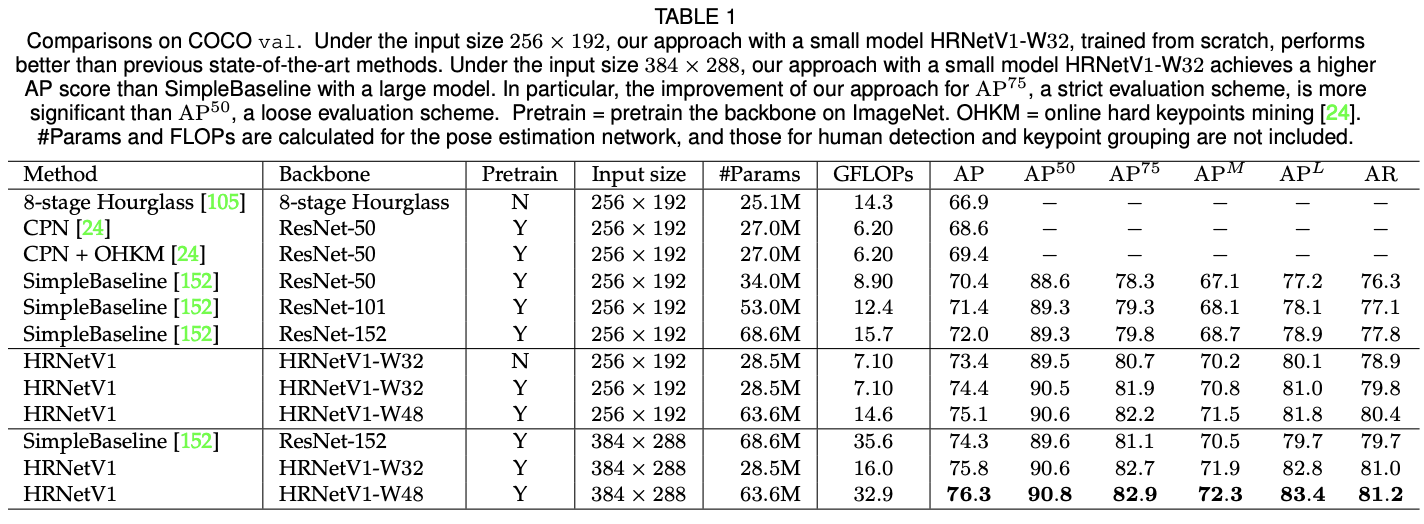
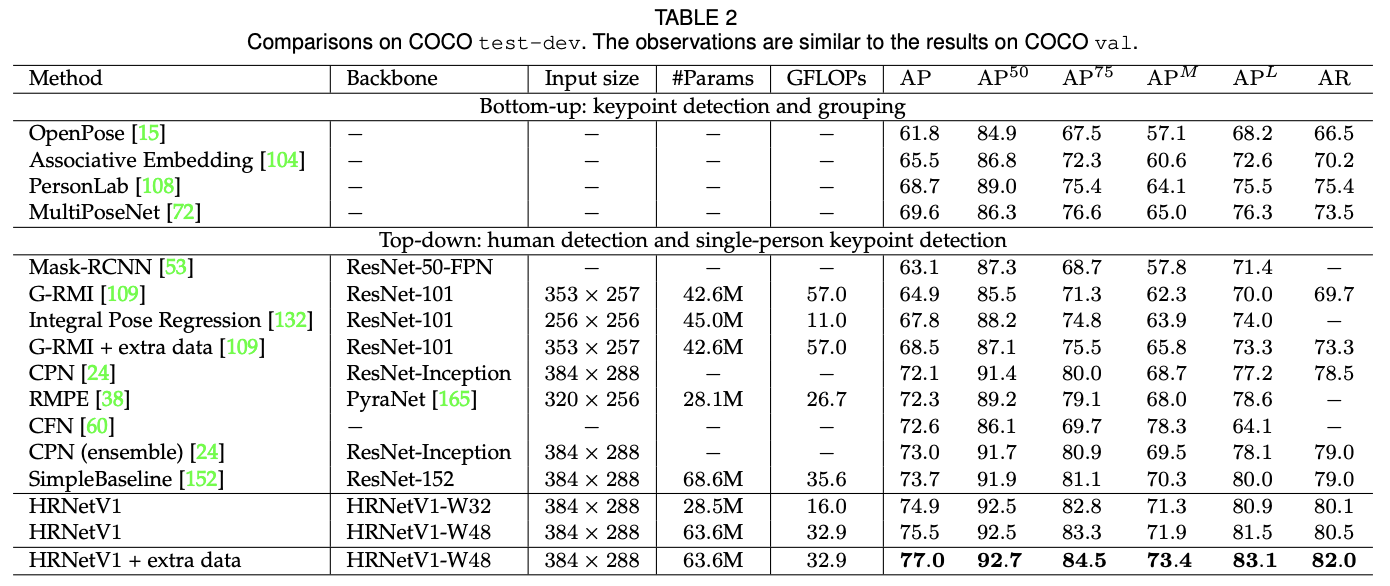
H/4 x W/4 크기의 K개 히트맵을 찾는 문제로 바꾸어 SOTA를 달성하였다. Pose Estimation Task에서는 HRNetv1과 HRNetv2의 결과가 비슷하여 Computational Cost가 적은 version 1을 선택하였다.
MSE를 Loss Function으로 GT 히트맵과 예측 히트맵을 비교한다. 이 때 GT 히트맵은 GT Keypoint에서 2 pixel을 가우시안으로 표현한 것이다.
이 말대로면 GT Joint를 단순히 Gaussian을 이용하여 면적으로 표현한 것인데 이러한 방법론을 다른 Task에서 활용할 수 있을 것 같다.
Evaluation Metric으로는 OKS(Object Keypoint Similarity)를 사용하였다. 또한 Detection을 먼저 진행하고 Pose를 예측하는 Top-Down 모델이기에 먼저 Human Detection Box를 Height : width = 4 : 3으로 맞추고 256*192 or 384*288로 자른 후 진행하였다.
5. Conclusion
본 논문에서는 Vision Recognition 문제를 해결하기 위한 High-Resolution Network를 제안한다. 기존의 Low-Resolution Classification & High-Resolution Representation Learning Network와의 차이점은 다음과 같다.
- High Resolution과 Low Resolution Convolution을 평행하게 연결하였다.
- 저해상도에서 고해상도로의 복원과정 없이 전체 프로세스 동안 고해상도를 유지하였다.
- Multi-Resolution을 반복적으로 합치면서 풍부한 고해상도 Representation을 만들었다.
세 줄 요약
1. 기존 CNN 모델들은 고해상도 정보를 저해상도로 낮추고 복원하는 과정을 거치기 때문에 Representation에 있어 손실이 발생한다.
2. 따라서 본 논문에서는 풍부한 Representation을 만들기 위해 전체 프로세스 동안 고해상도의 Representation을 유지하는 HRNet 모델을 제안한다.
3. Multi-Resolution의 정보를 반복적으로 합치며 풍부한 Representation을 만들 수 있었고 여러 Task에서 좋은 성능을 보였다.

'논문 paper 리뷰' 카테고리의 다른 글
| [Paper Review] Stable Diffusion 논문 이해하기 (0) | 2024.08.14 |
|---|---|
| [Paper Review] HybrIK 논문 이해하기 (1) | 2024.03.07 |
| [Paper Review] METER 논문 이해하기 (0) | 2023.11.04 |




댓글