『 An Empirical Study of Training End-to-End Vision-and-Language Transformers. ICCV. 2021. 』
- 본 논문은 실험 위주의 논문으로 이전까지 주로 사용하던 CNN 기반의 방법 대신 Transformer 기반의 Vision-Language Pretraining 모델을 만드는 것을 목표로 한다.
- VQA Task에서 사용되는 모델이며 Fully Transformer VLP 모델을 End-to-End로 구성하였다.
0. Abstract
본 논문에서는 Fully Transformer-based Vision-Language model인 METER(Multimodal End-to-end TransformER)를 소개한다. 모델 구조는 크게 5가지로 나누어 실험을 수행하였고 이를 통해 Vision-Language Transformer 모델을 학습하는 방법에 대한 인사이트를 제공한다.
1. Introduction
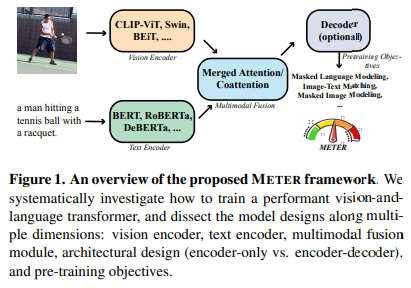
Transformer 모델은 NLP Task에서뿐만 아니라 CV Task에서도 이전까지 주로 사용하던 CNN 기반의 방법보다 좋은 성능을 내기 시작했다. 하지만 Transformer를 사용하는 최신 Multimodal 모델들은 Pretrained Object Detector를 사용한다는 특징이 있는데, 이 경우 2가지의 문제점이 발생한다.
- Pretrained Object Detector를 사용하기 때문에 VQA 모델을 학습할 때 해당 OD 부분은 Freeze를 하고 학습을 진행하게 된다. 따라서 이는 전체 VQA 모델의 학습 능력을 제한한다.
- Object Detector를 통과한 후 VQA 모델을 거치기 때문에 아무래도 추론 속도가 더 오래 걸리게 된다.
따라서 본 논문에서는 Object Detector를 사용하지 않는 Fully Transformer 모델을 구성하고자 하였고, 그러기 위해 모델의 디자인을 아래와 같이 크게 5가지로 나누어 실험을 진행하였다.
1. Vision Encoder
2. Text Encoder
3. Multimodal Fusion
4. Architectual Design
5. Pretraining Objectives
2. Glossary of VLP Models
Glossary : 용어사전

OD-based Region Features
ViLBERT, LXMERT : Object Detector를 통과한 후 2개의 Transformer 모델을 사용해 Co-Attention을 진행
Visual-BERT, VL-BERT : Object Detector를 통과한 결과를 하나의 Transformer 모델에 통과시켜 Merged-Attention 진행
위와 같이 이전까지는 Object Detector를 사용한 연구가 많이 존재했지만, 학습 능력의 제한, 긴 추론 시간의 문제가 발생하였다.
CNN-based Grid Features
위와 같은 두 가지 문제점 극복을 위해 Pixel-BERT, CLIP-ViL과 같은 CNN 기반의 연구들이 등장하였다. 하지만 최신 ViT 연구들에 비해 낮은 Accuracy를 기록했다.
ViT-based Patch Features
또한 ViT 기반의 VLP 모델을 만드려는 연구 또한 존재하였지만, SOTA에 미치지 못하는 성능을 보였다.
3. The METER Framework
3.1. Model Architecture
Vision Encoder
ViT, DeiT, Distilled-DeitT, CaiT, VOLO, BEiT, Swin Transformer, CLIP-ViT 모델로 실험을 진행하였다.
Text Encoder
Emb-only, ELECTRA, CLIP, DeBERTa, BERT, RoBERTa, ALBERT 모델로 실험을 진행하였다.
Multimodal Fusion

Co-attention 방법과 Merged attention 방법을 모두 실험하였다. Co-attention 방법은 Visual Encoder와 Text Encoder를 거쳐 나온 임베딩 결과를 각각의 Transformer Block에 통과시켜 Cross-Attention을 진행하는 방법이고, Merged attention은 Visual Encoder와 Text Encoder를 거쳐 나온 임베딩 결과를 단순 Concat을 한 뒤 하나의 Transformer에서 Self-Attention을 하는 방법이다.
Encoder-Only vs. Encoder-Decoder

Visual-BERT와 같은 다양한 VLP 모델이 이전까지 Encoder-Only 아키텍처를 사용하였다. 하지만 VL-T5, SimVLM과 같은 최신 연구에서는 Encoder-Decoder 아키텍처를 선택하는 모습을 보였다. 따라서 본 논문에서는 두 아키텍처를 모두 연구에 활용하였다.
3.2. Pre-training Objectives
Masked Language Modeling
: 기존 NLP 연구에서 많이 활용된 기법으로 입력 문장의 일부 단어를 마스킹하고 마스크된 단어를 모델이 예측하도록 하는 기법
Image-Text Matching
: 텍스트 쿼리가 주어졌을 때 이와 가장 잘 매칭되는 이미지를 찾는 기법
(CLS 토큰을 주는 Binary Classification 문제로써 모델 학습을 진행)
Masked Image Modeling

: MLM 기법의 이미지 버전으로 이미지의 일부분을 가리고 가려진 부분을 예측하는 딥러닝 기
3.3. Our Default Settings for METER
Model Architecture
Figure 2의 (a) 구조를 Default로 두었고 Visual Encoder와 Text Encoder를 각각 1개씩 두어 Encoder를 통과한 뒤 M=6인 Transformer Encoding Layer를 통과하도록 구성하였다. 하나의 Layer에는 Attention Block, Cross-Attention Block, FFN Block으로 이루어져 있다.
Pre-training Datasets
MLM + ITM 기법을 사용하였다.
Pre-training Datasets
Pre-training을 위해 COCO, Conceptual Captions, SBU Captions, Visual Genome의 총 4백만 개의 Image Captioning Data를 활용하였다.
Downstream Tasks
VQA Task를 수행하기 위해 VQAv2, Flickr30k 데이터를 사용하였다.
Implementation Details
자세한 실험 정보는 논문 참고
4. Experiments
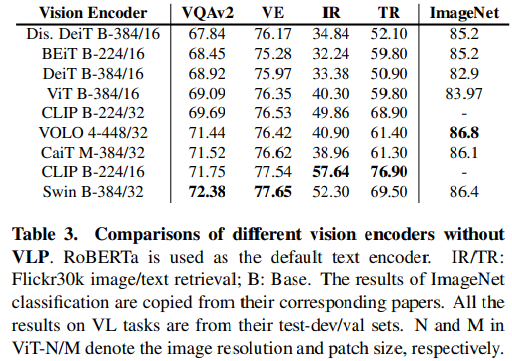

위 실험 결과와 같이 Vision Encoder로는 CLIP-ViT 224/16, Swin Transformer 모델을 사용할 때 가장 성능이 좋았다.
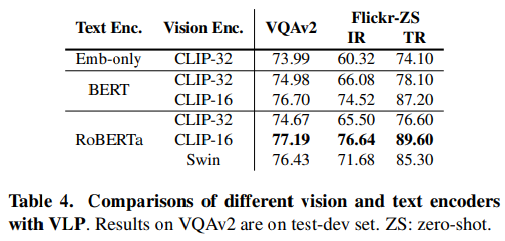
Text Encoder는 RoBERTa를 사용할 때 성능이 가장 좋았다.

Multimodal Fusion 방법으로는 Co-attention, Architecture 방법으로는 Encoder만 사용할 때 성능이 가장 좋았다.
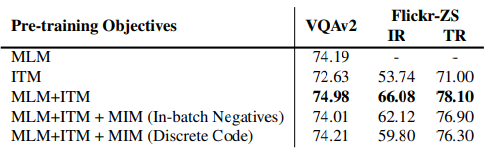
사전학습 기법으로는 MLM과 ITM 기법만을 사용할 때 성능이 가장 좋았다.

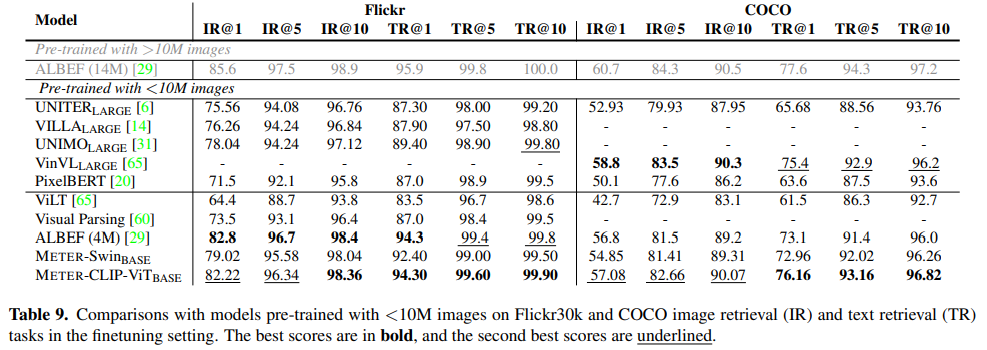
학습 이미지가 10M보다 적은 모델들과의 성능 비교 결과이다. 최종적으로 METER 모델에서 선정한 CLIP Vision Encoder 기반 모델의 성능이 대부분의 데이터에서 좋은 성능을 보이는 것을 확인할 수 있다.
5. Conclusion
본 논문에서는 많은 아키텍처 실험을 통해 Fully-Transformer VLP 모델을 End-to-End 방식으로 구현하였다. 실험을 통해 4백만개의 사전 학습 이미지만으로 SOTA와 비슷한 성능을 보이는 것을 확인하였다.
세 줄 요약
1. 기존에 Object Detector를 사용할 때 모델의 학습 능력을 제한하고 추론 속도가 오래걸린다는 문제 존재
2. Fully-Transformer VLP 모델을 End-to-End 방법으로 학습할 수 있는 METER 모델 제안
3. 다섯 가지 모델 구조에 대한 다양한 실험을 통해 SOTA와 가장 경쟁력 있는 모델 구성

'논문 paper 리뷰' 카테고리의 다른 글
| [Paper Review] HybrIK 논문 이해하기 (1) | 2024.03.07 |
|---|---|
| [ToBig's] BERT 논문 이해하기 (0) | 2023.09.13 |
| [X:AI] DDPM 논문 이해하기 (0) | 2023.08.17 |




댓글