『 Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. ICCV. 2021 』
ViT의 등장 이후 Vision Task에 Transformer 모델을 활용하기 위한 연구자들의 노력은 계속되었다. Swin Transformer는 그중 하나인 모델로 Microsoft Research Asia에서 2021년 발표한 논문이다.
본 논문은 기존 ViT에서 모든 Patch에 대해 Self Attention을 진행하여 많은 Computational Cost가 발생한다는 것을 지적하며 각 Patch를 Window로 나누어 Self Attention을 진행 + 해당 Window를 Shift하여 다시 Self Attention을 진행하는 방법론을 제안한다.
Swin Transformer는 Shifted Windows Transformer가 모델 이름의 어원이며, Computer Vision Task에서 현재까지도 좋은 Backbone으로 활용되고 있는 모델이다.
Swin Transformer Code
https://github.com/microsoft/Swin-Transformer
GitHub - microsoft/Swin-Transformer: This is an official implementation for "Swin Transformer: Hierarchical Vision Transformer u
This is an official implementation for "Swin Transformer: Hierarchical Vision Transformer using Shifted Windows". - GitHub - microsoft/Swin-Transformer: This is an official implementation...
github.com
Swin Transformer V2
https://arxiv.org/abs/2111.09883
Swin Transformer V2: Scaling Up Capacity and Resolution
Large-scale NLP models have been shown to significantly improve the performance on language tasks with no signs of saturation. They also demonstrate amazing few-shot capabilities like that of human beings. This paper aims to explore large-scale models in c
arxiv.org
0. Abstract
Swin Transformer는 Computer Vision에서 일반적인 Backbone으로 사용할 수 있는 모델이다. 본래 NLP에서 시작된 Transformer 모델을 Vision Task에 적용할 때에는 Visual Entity의 크기와 해상도가 다양하다는 어려움이 존재하는데, 본 논문에서는 이를 극복하기 위해 Shifted Windows 방법을 사용한 Hierarchical Transformer를 제안한다. 이 모델은 Self Attention 계산량을 줄이고 다양한 scale을 처리할 수 있는 유연성을 갖는다.
Image Classification, Object Detection, Semantic Segmentation 같은 Computer Vision Task에서 좋은 성능을 보였다.
1. Introduction
이전까지의 Computer Vision은 오랫동안 CNN 아키텍처를 기반으로 발전해온 반면, NLP에서는 Transformer를 통해 발전해 왔다. 이러한 Transformer 모델을 Computer Vision에 적용하려면 두 가지 문제점이 존재한다.
- 언어 Transformer에서 사용하는 단어 Token과 달리 Visual Elements의 크기가 매우 다르다. (서로 다른 크기의 예측을 필요로하는 Object Detection에서 중요)
- 텍스트 단어에 비해 이미지 픽셀의 해상도가 훨씬 높다. (Pixel 단계에서 Dense한 예측을 요구하는 Semantic Segmentation에서 중요)
이러한 문제를 극복하기 위해 Hierarchical Feature Map을 구성하고 이미지 크기 처리에 대해 선형 계산 복잡도를 가지는 범용적인 Backbone인 Swin Transformer를 제안한다.
※ Backbone
입력 이미지의 특징을 추출하여 Feature Map을 만들어주는 과정. 이렇게 만들어진 Feature Map은 다른 신경망과 연결되어 Image Classification, Object Detection 등 다른 Computer Vision Task에 적용될 수 있다.
일반적으로 Backbone은 이미지의 크기, 해상도, Task의 종류에 따라 선택되며 대표적인 Backbone으로는 ResNet, VGGNet 등이 있다.
Backbone -> Neck -> Head
Feature Map을 만드는 Backbone -> Feature Map을 조정하는 Neck -> 최종적인 Task를 수행하는 Head

Figure 1의 (a)에서 볼 수 있듯이 Swin Transformer는 작은 크기의 Patch에서 시작하여 인접한 Patch를 점진적으로 합쳐가는 Hierarchical 구조로 구성된다. 이러한 구조로 인해 FPN(Object Detection)이나 U-Net(Semantic Segmentation)처럼 Hierarchical 정보를 활용할 수 있다.
입력 이미지의 사이즈가 64 x 64 이라고 가정해 보자, Figure 2의 (b)에서 볼 수 있듯이 ViT는 16 x 16 을 하나의 Patch로 구성한다. 그렇게 되면 가로 4(64/16) x 세로 4 = 16개의 Patch를 가지게 되고, 이때 각 Patch와 전체 Patch에 대한 Self-Attention을 수행하여 Quadratic 계산 복잡도를 가진다. 한편, Swin Transformer는 Feature Pyramid Network 구조처럼 작은 Patch Size에서 시작하여 점점 인접한 Patch를 합쳐간다. Figure 1의 (a)에서 볼 수 있듯이 처음에는 4 x 4 를 하나의 Patch로 구성한다. 그림에서 보이는 빨간 선은 Window를 구분해 놓은 것으로 Swin Transformer에서는 하나의 Window 내의 Patch 끼리만 Self-Attention을 수행하여 Linear한 계산 복잡도를 가진다.
따라서 16 x 16 크기를 가진 16개의 Window 안에 각각 4 x 4 크기를 가진 16개의 Patch를 가지고 Patch 안에서만 Self-Attention을 수행하며, 다음 계층으로 갈수록 인접한 Patch들을(Window로 봐도 될 듯..?) 합쳐가며 계산을 진행한다. 이때 Window 안의 Patch 수가 고정되어 있기 때문에 Linear한 계산 복잡도(이미지 크기에 따라 n x 16 배)를 가질 수 있다. 이때 일반적인 Transformer 구조처럼 전체 이미지의 정보를 한 번에 파악하는 것이 아니라 Window의 개념을 도입하면서 CNN의 Locality Inductive Bias를 추가해 이미지 데이터에서 더 좋은 성능을 낸 것 같다.
논문에서는 입력 이미지를 224, Window Size를 7로 사용한 실험을 이후에 언급해 주는데 그대로 Figure 1을 해석하면 그림 안의 숫자가 잘 이해되지 않아서 임의의 해석으로 진행했습니다... 피드백 환영 합니다 🥲
※ Self-Attention
16-01 트랜스포머(Transformer)
* 이번 챕터는 앞서 설명한 어텐션 메커니즘 챕터에 대한 사전 이해가 필요합니다. 트랜스포머(Transformer)는 2017년 구글이 발표한 논문인 Attention i…
wikidocs.net

Figure 2는 Swin Transformer의 또다른 핵심 구조인 Shifted Window 기법을 설명한다. Figure 1처럼 Window로 자른 뒤 해당 영역 내에서만 Self-Attention을 수행하면 Window 가장자리의 픽셀들은 근처에 있는 픽셀임에도 다른 Window로 구분되는 문제가 발생한다. 따라서 Layer가 지날수록 Window를 바꿔가며 계산을 진행하였다. 자세한 기법은 3.2 장에서 설명하고 있다.
Shifted Window 기법이 실제로 Sliding Window 기반의 Self-Attention 기법보다 Latency는 낮지만 유사한 성능을 보였다.
2. Related Work
CNN and variants
: CNN 관련 여러 모델들이 빠르게 발전해왔다.
Self-attention based backbone architectures
: ResNet의 일부 계층을 Self-Attention으로 대체하여 성능을 더 높인 모델이 있었지만 메모리 사용량이 너무 많았다. 따라서 본 논문에서는 Sliding Window 대신 Shifted Window 방법을 사용하였다.
Self-attention/Transformers to complement CNNs
: CNN을 Self-Attention이나 Transformer 모델을 사용하여 보강하는 연구도 있었다.
Transformer based vision backbones
: Transformer를 Vision Backbone으로 사용할 수 있다. (ViT, DeiT)
3. Method
3.1. Overall Architecture

Figure 3는 전체적인 Swin Transformer의 구조(Tiny, Small, Base, Large 中 Tiny)이다.
- Patch Partition : 입력된 RGB 이미지를 중복되지 않는 Patch로 나누어 준다. (ViT Patch 분할 방법) 이때 하나의 Patch는 하나의 Token 역할을 하고 논문에서는 가장 작은 사이즈인 4 x 4 크기의 Patch를 사용하므로 4 x 4 x 3 = 48 크기의 차원을 갖는다.
- Stage 1 : 이후 Linear Embedding Layer를 거쳐 $H/4 x W/4 x 48$ 차원에서 $H/4 x W/4 x C$ 크기로 투영된다. 이후에는 Swin Transformer Block을 거치는데 Figure 3 (b)에서 볼 수 있는 W-MSA(Window-Multihead Self Attention)와 SW-MSA(Shifted Window MSA)를 사용한다. Activation Function으로는 GELU를 사용하였다. (3.2 장에서 설명)
- Stage 2 : Stage 2부터는 Swin Transformer Block을 거치기 전에 Patch Merging 과정을 거친다. 처음으로는 인접한 2 x 2 개의 Patch를 합쳐준다. 이때 Concat으로 합쳐주기 때문에 차원의 수가 4C 크기가 되기에 Linear Layer를 거쳐 2C로 줄여준다. 최종적으로 이전 Stage 보다 Token 수가 4(2x2) 배 줄어들고 채널 수는 2배가 된다.
- Stage 3 ~ : Stage 2와 같은 과정을 Stage 3, Stage 4에 반복하여 $H/16 x W/16 x 4C$, $H/32, W/32, 8C$의 출력 해상도를 갖는다.
※ GELU (Gaussian Error Linear Unit)
GELU (Gaussian Error Linear Unit)
BERT, GPT, ViT 모델에서는 인코더 블락 안의 2-layer MLP 구조의 활성화 함수로 ReLU가 아닌 GELU (Gaussian Error Linear Unit) 함수가 사용됩니다. 최신 NLP, Vision SOTA 성능을 도출하는 모델들이 GELU 함수를 사용
hongl.tistory.com
3.2. Shifted Window based Self-Attention
Self-attention in non-overlapped windows
Swin Transformer에서는 기존의 Self-Attention이 모든 쌍에 대한 연산하여 Quadratic 계산량을 가지는 문제를 Shifted Window 기법을 사용해 극복하였다.

위 수식은 기존에 사용하던 방법인 MSA(Multihead Self Attention)와 본 논문에서 사용한 W-MSA(Window-Multihead Self Attention)의 계산량을 나타낸다.
- 가장 작은 Patch : 4x4
- Window : M x M 개의 Patch (M=7이 Default)
따라서 MSA 기법은 이미지 크기(hw)의 제곱에 비례하는 반면, W-MSA 기법은 M의 크기가 고정되어 이미지 크기에 따라 선형적으로 증가한다.
Shifted window partitioning in successive blocks
하지만 단순히 W-MSA 기법을 사용하면 Window의 가장자리에 있는 Patch 들은 근처에 있는 Patch임에도 다른 Window에 속해 Attention 계산을 수행할 수 없다. 이러한 문제를 극복하기 위해 Window를 M/2 만큼 Cyclic하게 Shift한 뒤 계산을 다시 수행하는 과정을 거친다.
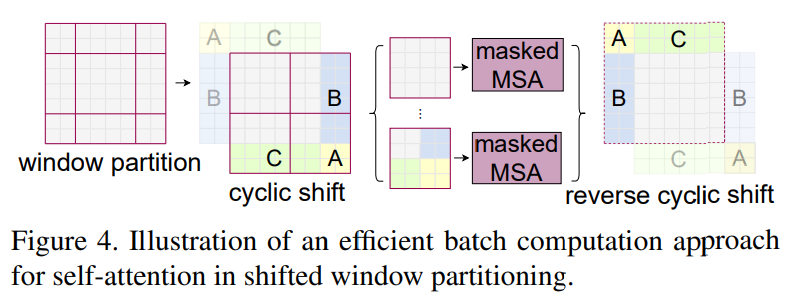
여기서 Cyclic Shift란 M//2(7//2 = 3)개의 Window를 우측 하단으로 회전 이동 시키는 것을 말한다. 이때 움직인 Window들은 Masking 되어서 Self-Attention을 수행한다. 마스크 연산을 거친 후에는 다시 원래의 위치로 되돌린다.
결국 Swin Transformer Block 안에서 W-MSA, MLP, SW-MSA, MLP 과정을 거치게 되고 수식은 다음과 같다.

Efficient batch computation for shifted configuration
Window를 Shift하고 나면 기존 2x2 크기의 Window가 3x3 크기의 Window가 되고 몇몇 Window 들의 크기가 M x M보다 작아지는 현상이 발생한다. 이러한 문제에 대한 쉬운 해결책으로는 Padding이 있지만 본 논문에서는 Shift한 Window들을 Masking하고 다시 동일한 창 수로 Self-Attention을 수행한다. 이 방법이 낮은 Latency를 이끌어 냈다고 한다.

Relative position bias
Swin Transformer에서는 Transformer처럼 Positional Embedding 과정을 거치는 대신 Relative position bias를 더해준다.

기존 Positional Embedding은 절대 좌표를 단순히 더해주었는데, 이렇게 상대 좌표를 더해주는 방식이 더 좋다고 말하고 있다.
3.3. Architecture Variants
Swin Transformer는 128개의 채널을 가지는 모델을 Base Model로 하고 4배 작은 Tiny, 2배 작은 Small, 2배 큰 Large 모델이 있다.

4. Experiments
- Image Classification : ImageNet-1K
- Object Detection : COCO
- Semantic Segmentation : ADE20K
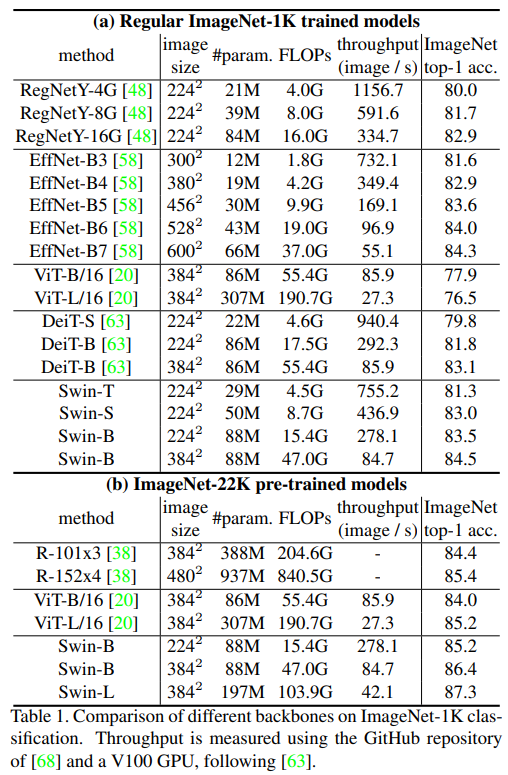
4.1. Image Classification on ImageNet-1K
4.2. Object Detection on COCO

4.3. Semantic Segmentation on ADE20K

4.4. Ablation Study

Shifted Window 기법을 사용한 결과가 모든 Task에서 성능이 좋다.
5. Conclusion
본 논문에서는 Hierarchical Feature Representation을 생성하고 Linear 계산 복잡도를 가지는 Swin Transformer 모델을 제안한다. Image Classification, Object Detection, Semantic Segmentation에서 좋은 성능을 보였으며, 다양한 Vision Task에서 효율적인 Backbone으로 사용할 수 있다. Vision 뿐만 아니라 NLP에서도 사용할 수 있기를 기대한다고 한다.
<참고자료>
https://greeksharifa.github.io/computer%20vision/2021/12/14/Swin-Transformer/
Python, Machine & Deep Learning
Python, Machine Learning & Deep Learning
greeksharifa.github.io
https://deep-learning-study.tistory.com/728
[논문 읽기] Swin Transforemr(2021), Hierarchical Vision Transformer using Shifted Windows
안녕하세요, 오늘 읽은 논문은 Swin Transformer: Hierarchical VIsion Transformer using Shifted Windows 입니다. Swin Transformer는 transformer 구조를 object detection에 적용한 모델입니다. text에 비해서 image는 어떻게 patch
deep-learning-study.tistory.com
https://visionhong.tistory.com/31
[논문리뷰] Swin Transformer
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows Ze Liu† / Yutong Lin† / Yue Cao / Han Hu / Yixuan Wei† / Zheng Zhang / Stephen Lin / Baining Guo / Microsoft Research Asia 이번 포스팅에서는 2021년 3월에 마이크로
visionhong.tistory.com
https://blog.kubwa.co.kr/inductive-bias-4af72375b2d1
Inductive Bias
안녕하세요!
blog.kubwa.co.kr
세 줄 요약
1. ViT가 많은 계산 복잡도를 가진다는 문제를 극복한 Swin Transformer 모델 제안
2. Patch 수를 적게 시작해 점차 합쳐가는 Hierarchical 구조, Shifted Window 기법을 활용해 계산 복잡도를 줄이고 성능을 향상
3. Image Classification, Object Detection, Semantic Segmentation에서 좋은 성능을 보였으며 Vision Task에서 효율적인 Backbone으로 사용할 수 있음

'논문 paper 리뷰' 카테고리의 다른 글
| [X:AI] DINO 논문 이해하기 (0) | 2023.08.10 |
|---|---|
| [X:AI] Taskonomy 논문 이해하기 (0) | 2023.07.13 |
| [X:AI] Inception-v4 논문 이해하기 (1) | 2023.07.01 |




댓글