『 Taskonomy: Disentangling Task Transfer Learning. CVPR. 2018 』
Computer Vision을 공부하다보면 Object Detection, Pose Estimation 등 Computer Vision 안에도 수많은 Task가 있는 것을 알 수 있다. 일반적으로 우리는 이렇게 나누어진 한 가지 Task 내에서 PreTrained 된 모델을 가지고 와 새로운 데이터를 Transfer Learning 하여 학습, 평가를 진행하는데, Taskonomy 논문에서는 이러한 Transfer Learning 과정이 한 가지가 아닌 여러 Task 사이에서 이루어질 수 있는 방법을 제안한다.
지금까지 딥러닝을 공부해온 사람이라면 참신하다는 생각을 가질 수 밖에 없고 실제로도 인기가 있어 2018년 CVPR 컨퍼런스의 Best Paper Award를 수상하였다.
Taxonomy가 분류 체계라는 뜻이니까 Task끼리 분류된걸 연관하여 사용했다는 의미로 지었을까..? 😯
논문 보충자료
http://taskonomy.stanford.edu/taskonomy_supp_CVPR2018.pdf
논문 관련 사이트
http://taskonomy.stanford.edu/
Taskonomy
Do visual tasks have a relationship, or are they unrelated? For instance, could having surface normals simplify estimating the depth of an image? Intuition answers these questions positively, implying existence of a "structure" among visual tasks. Knowing
taskonomy.stanford.edu
0. Abstract
본 논문은 여러 Visual Task들이 서로 관련이 있다는 가정에서부터 시작한다. 애초에 Transfer Learning이 이러한 가정에서 시작한 개념이기에 여러 Task간의 작업 또한 서로 의존성을 가질 것이라고 이야기한다. 실제로 논문에서는 잠재 공간에서의 의존성을 발견하였고 이 관계를 연구하였다.
1. Introduction
Object Recognition, Depth Estimation, Edge Detection 등은 일반적인 비전 Task로 많이 연구된다. 이러한 비전 Task들은 서로 관련성을 가지지만 지금까지는 이 관계성을 사용하지 않고 별개로 발전하였다. 따라서 본 논문에서는 이러한 비전 Task간의 구조를 파악하고 공간을 매핑하기 위한 프레임워크를 제안한다. 여기서 말하는 "구조(Structure)"는 여러 Task 간의 관계를 봤을 때 한 Task가 다른 Task에 얼마나 유용한 정보를 제공하는지에 대한 관계를 의미한다.
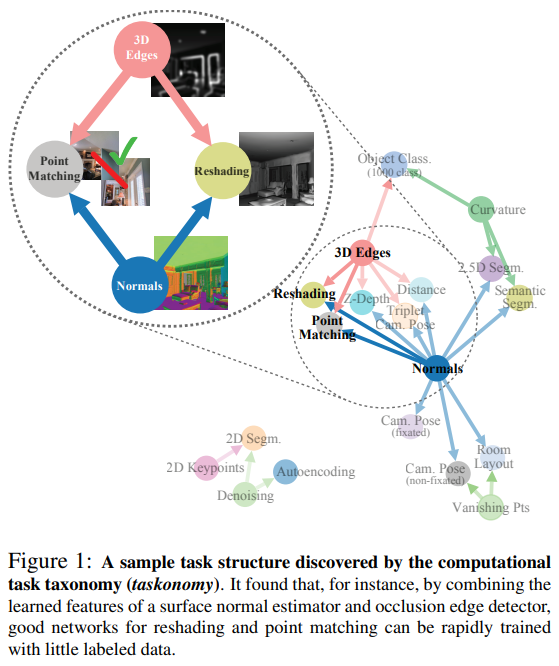
결국 서로 다른 Task들 간의 관계를 그래프 형태로 표현하고, 이를 이용해 새로운 Task에 있어 사용되는 딥러닝 모델을 효율적으로 학습할 수 있다. Target Task를 단독으로 학습했을 때 대비 성능이 향상된 수준을 "Transferability" 척도로 측정하였고, 이렇게 조사한 Task 간의 관계를 Affinity Matrix(유사도 행렬)로 표현한 후 Target Task에 대한 최적의 Transfer Policy를 찾아내었다.
모든 과정은 각 Task에 대한 Prior Knowledge가 개입하지 않도록 구성하였다.
2. Related Work
Self-supervised Learning
Unsupervised Learning
Meta-learning
: 다른 Task를 위해 기학습된 AI 모델을 이용하여 다른 Data를 이용해 다른 Task에서도 잘 수행할 수 있도록 학습시키는 방법
(여기서 Meta-Level 은 상위 레벨에서 더 추상화된 것을 의미한다)
Multi-task learning
Domain adaption
: Transfer Learning의 형태로 Task는 동일하나 Domain이 달라지는 경우 최적의 Transfer Policy를 찾는 연구 주제
Learning Theoretic
: 모델의 일반화 성능을 보장하기 위한 방법으로 Intractable(계산 불가능)한 계산을 살짝 피해 이론적 증명을 피하고 더 실용적인 접근을 꾀함
3. Method
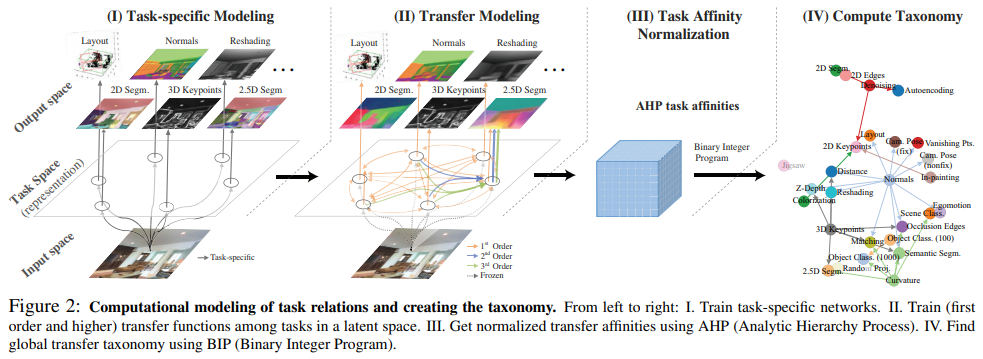
Taskonomy는 여러 Task간의 Transferability를 나타낸 Hypergraph이다. 하나의 Edge가 여러 Node와 연결된 것 처럼 하나의 Target Task에 여러 Source Task가 연결되어 이들을 성능 극대화를 위해 동시에 활용할 수 있다고 이야기 한다.
$T = {t_1, ... , t_n}$ : Target Task Set
$S = {s_1, ... , s_n}$ : Source Task Set
$k$ : Transfer Order, 하나의 Target Task에 대하여 활용 가능한 Source Task의 개수
Taskonomy는 위의 그림에서 볼 수 있듯이 4단계를 거쳐 진행된다.
- 1단계 : Source Task Set $S$ 내의 각 Task에 대해 특화된 Task-Specific 모델을 독립적으로 학습한다.
- 2단계 : 지정된 Trasnfer Order $k$에 따라 만들어지는 Trasferability를 계산한다.
- 3단계 : 계산된 Transferability에 대해 정규화를 적용하여 Affinity Matrix(유사도 행렬)을 얻는다.
- 4단계 : Affinity Matrix를 기반으로 각 Target Task에 대해 최적의 성능을 보이는 Transfer Policy를 탐색한다.
본 논문에서는 Computer Vision에서 주로 연구되는 26가지의 주제를 Task로 명시하였다. 물론 이때 각각의 Task에서 모든 것을 사용한 것이 아닌 Task Space에서 샘플링을 하여 실험하였다.

Step 1 : Task-Specific Modeling
Source Task Set 내의 각 Source Task 들을 Task-Specific한 Network를 이용하여 학습한다. 이 때 각 Task-Specific한 Network는 Encoder-Decoder 구조를 지닌다.
Step 2 : Transfer Modeling
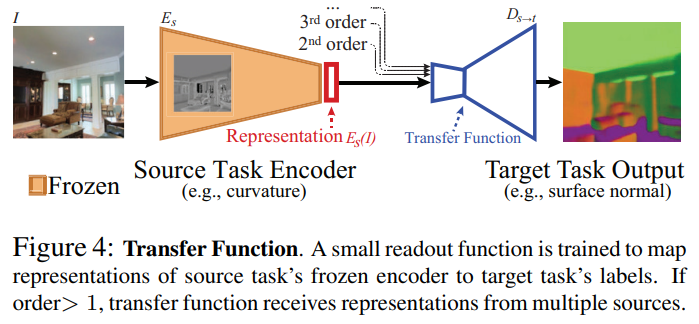
Souce Task Set과 Target Task Set에 속하는 s와 t를 s의 Task-Specific Network의 Encoder와 새로운 Decoder를 합쳐 만든 Transfer Network에 통과시킨다. 전체 학습 과정에 대한 식은 아래와 같다.
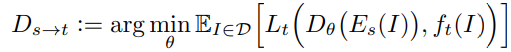
$f_t(I)$ : 입력 이미지 $I$에 대한 Target Task t의 Ground Truth
$D_{s\rightarrow t}$의 성능이 높을 수록 s, t간의 Transferability가 높으며, 여기서는 모든 $(s,t)$ 조합에 대해 계산한다. 하지만 이 때 Trasfer Order $k$가 1보다 커질 경우 계산량이 지나치게 방대해 질 수 있기 때문에, $k$가 1보다 큰 경우 본 논문에서는 우선 $k=1$로 계산하여 Hypergraph를 그리고 Beam Search를 적용해 상위 $max(5,k)$개의 Souce Task를 선택해 이들간의 조합만을 고려하였다.
Step 3 : Ordinal Normalization using Analytic Hierarchy Process
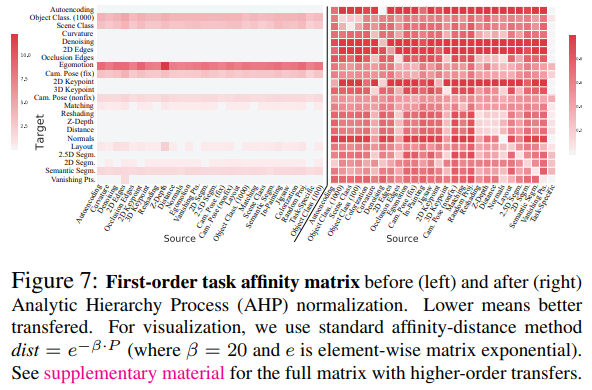
Step 2에서 계산한 Transferability를 기반으로 Affinity Matrix를 구하는 단계이다. 이 때, Target Task에 따라 Loss의 범위가 다르기 때문에 Normalization을 진행 해준다. 본 논문에서는 Operations Research와 같은 분야에서 자주 사용되는 Analytic Hierarchy Process에서 따온 Normalization 방법을 사용하였다.
Step 4 : Computing the Global Taxonomy
Task Affinity Matrix를 완성한 뒤 이를 사용하여 Target Task의 성능을 극대화 하는 Transfer Policy를 찾아낸다. 이 때 Boolean Interger Programming(BIP) 문제를 푸는 것으로 목적 함수와 제약식이 설정된다.

4. Experiments
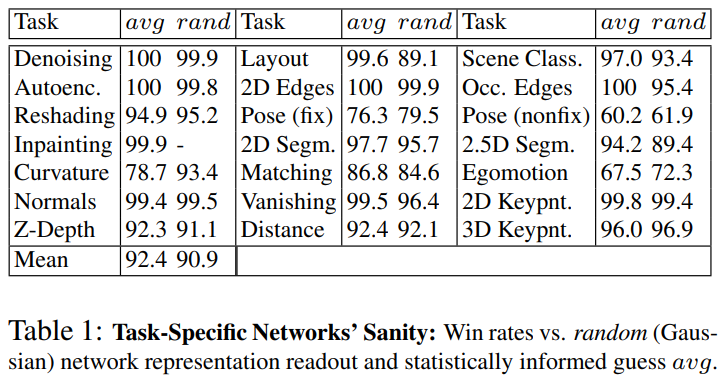
Step 1에서 각 Task에 대해 학습시킨 Task-Specific Model의 성능이 좋은지부터 Test
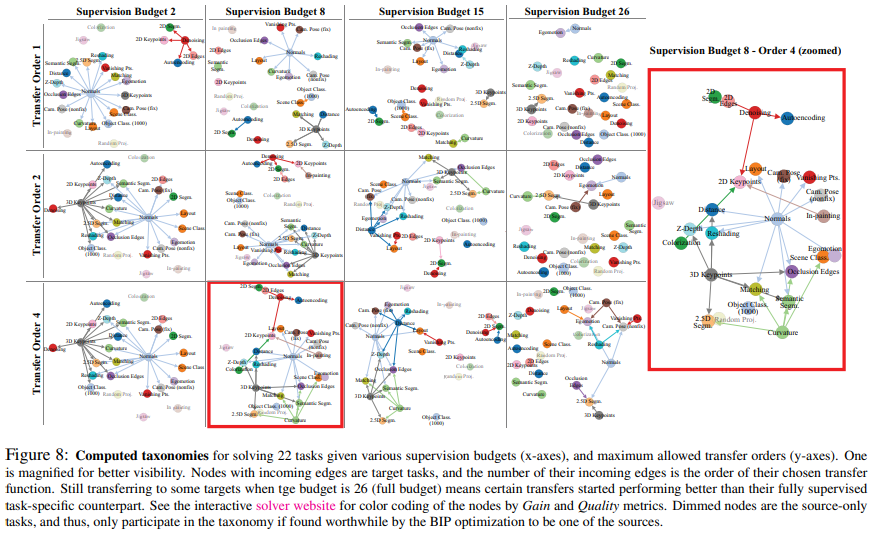
Supervision budget과 Transfer Order $k$를 바꿔가며 학습한 결과 Taskonomy
Taskonomy에 기반한 Transfer 규칙을 각 TargetTask에 적용한 테스트 결과

Max Transfer Order $k$를 증가시킬 수록, Supervision Budget을 증가시킬 수록 Gain과 Quality가 증가하는 경향을 보인다.
-> 더 많은 Source Task로 부터 얻은 지식을 Transfer할 수록 성능이 높아진다는 가설 성립
이전까지의 실험에서는 Source-Target을 정해두고 실험했지만, 현실적인 상황에서는 새로운 Target Task에 대하여 기존에 있던 Source Task만을 가지고 최적의 Transfer Policy를 찿아야 할 것이다. (Cold-Start 문제와 비슷!!)
따라서 기존 Task들을 모두 Source로 옮기고 새로운 Task를 단일 Target으로 한 실험을 진행하였다.
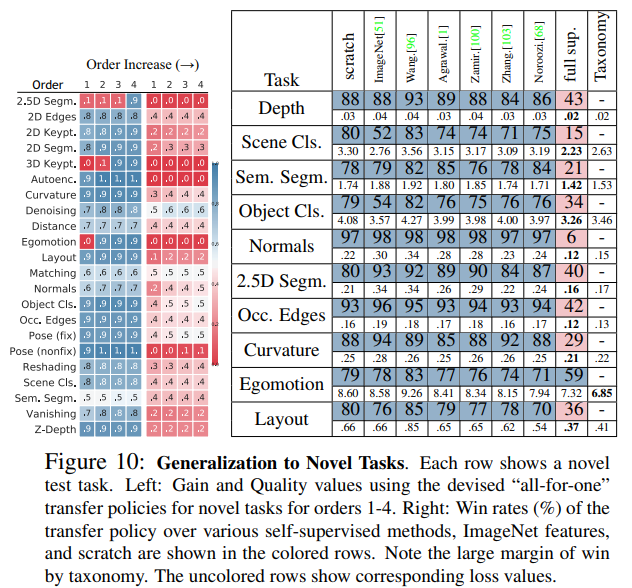
실험 결과 Taskonomy에 기반하여 찾은 Transfer Policy로 학습한 결과가 전체적으로 우수한 것을 확인하였다.
5. Significance Test of the Structure
Taskonomy로 찾은 최적의 Transfer Policy의 효과 확인

이외에도 다른 데이터를 사용한 일반화 성능 검증, 안정성 검증, Task간의 유사도 검증을 실시하였다.
6. Limitations and Discussion
(1) Model Dependence
학습은 DNN으로, 데이터는 이미지 데이터만을 사용하여 실험 결과가 Model, Data에 대해 Specific함
(2) Compositionality
본 논문에서 다룬 Task가 모두 사람이 정의한 Task로 더 많은 Task를 다루지 못함
(3) Space Regularity
26개의 Task에 대해서도 샘플링하여 Task로 사용했기 때문에 일반적인 Task라고 봐도 될지에 대한 검증이 필요
(4) Transferring to Non-visual and Robotics Tasks
Vision Task에만 검증을 수행하여 시각적이지 않은 분야에서도 Taskonomy 기법으로 Transferability를 높일 수 있을 지 의문
(5) Lifelong Learning
Taskonomy를 한 번에 완성하였는데 지속적으로 시스템이 학습을 수행하며 어떤 Task를 꾸준히 발전시킬 수 있을지 연구 필요
<참고자료>
Taskonomy: Disentangling Task Transfer Learning 리뷰 - 블로그 | 코그넥스
Interpretable Machine Learning 개요: (1) 머신러닝 모델에 대한 해석력 확보를 위한 방법
www.cognex.com
세 줄 요약
1. Task간의 관계를 파악해 Transferability를 보이고 새로운 Task의 성능을 높인 Taskonomy방법 제안
2. Task간의 Transferability를 구하는 4가지 단계를 거쳐 최적의 성능을 보이는 Transfer Policy를 찾음
3. 더 많은 Source Task로 부터 얻은 지식을 Transfer할 수록 성능이 높아지고 Transfer Policy를 사용할 때의 성능이 좋음

'논문 paper 리뷰' 카테고리의 다른 글
| [X:AI] Swin Transformer 논문 이해하기 (0) | 2023.07.20 |
|---|---|
| [X:AI] Inception-v4 논문 이해하기 (1) | 2023.07.01 |
| [X:AI] StarGAN 논문 이해하기 (0) | 2023.05.25 |




댓글