『 HRFormer: High-Resolution Transformer for Dense Prediction. NeurIPS. 2021. 』
이번에 소개할 논문은 HRNet 구조에 Transformer 기법을 적용한 HRFormer 논문이다. HRNet이 등장한 이후 전체 네트워크 동안 고해상도를 유지하는 것이 성능을 높이는 데 도움을 주었다는 것이 입증되었고, ViT 모델이 등장하며 한단계 더 발전한 기법을 활용할 수 있게 되었다. 이 논문은 이러한 2가지 성공적인 기법을 잘 믹스하여 Pose Estimation, Semantic Segmentation Task에서 특히 좋은 성능을 낼 수 있었다.
본 논문에서는 Image Classification, Pose Estimation, Semantic Segmentation Task에 대해 설명하지만 이번 리뷰에서는 내가 알고 싶은 Pose Estimation 관련 내용 위주로 분석하도록 하겠다.
Github
https://github.com/HRNet/HRFormer
GitHub - HRNet/HRFormer: [ NeurIPS2021] This is an official implementation of our paper "HRFormer: High-Resolution Transformer f
[ NeurIPS2021] This is an official implementation of our paper "HRFormer: High-Resolution Transformer for Dense Prediction". - HRNet/HRFormer
github.com
0. Abstract
본 논문에서는 Dense Prediction Task에서 High-Resolution Representation을 학습하는 High-Resolution Transformer(HRFormer) 모델을 제안한다. HRFormer에서는 HRNet에서 사용한 다중 해상도 병렬 설계를 활용하고 Local-Window Self-Attention을 사용하여 전역적으로도, 지역적으로도 이미지를 잘 분석할 수 있도록 디자인하였다. 이는 기존에 저해상도 Representation만을 가지는 ViT(Vision Transformer)와 대조되어 고해상도를 잘 분석할 수 있었고, 이러한 장점으로 Pose Estimation과 Semantic Segmentation Task에서 좋은 성능을 보였다.
※ Dense Prediction이란?
: 이미지 내의 픽셀 또는 영역마다 가지는 라벨을 예측하는 컴퓨터 비전 작업
https://stats.stackexchange.com/questions/281530/what-is-dense-prediction-in-deep-learning
What is dense prediction in Deep learning?
I am using TensorFlow's pre-trained model of Convolutional Neural Network. https://github.com/tensorflow/models/blob/master/slim/nets/resnet_v2.py#L130 I found following sentence: However, for...
stats.stackexchange.com
※ Vision Transformer가 저해상도 Representation을 가지는 이유
: ViT는 이미지를 Patch로 나누어 Input으로 활용하는 데 이 때 각 Patch마다 가지는 해상도가 낮아지기 때문. 이는 전역적인 정보를 분석하는 데에 적합하다.
1. Introduction
Abstract에서 언급한 것 처럼 ViT는 이미지를 Patch로 나누어 Representation을 추출하기 때문에 세밀한 공간 정보를 잃게 된다(위에서 말한 것처럼 저해상도 Representation을 가지기 때문에). 또한 단일 해상도 Representation만을 출력하여 Multi-Scale Variation을 처리하는 능력이 부족하다는 단점을 가진다.

본 논문이 제안하는 HRFormer(High-Resolution Transformer)는 ViT의 이러한 두가지 단점을 개선하였다. 특히 HRNet 구조를 차용하여 디테일한 공간 정보를 유지하고, 다중 해상도 간에 정보 교환을 가능케 하였다. 이를 위해 사용한 방법은 다음과 같다.
- 모델 초기에는 Convolution이 좋은 성능 -> Stem + 1st Stage에 Convolution 사용
- 고해상도를 전체 네트워크 동안 유지하면서 중간 해상도, 저해상도 Stream이 고해상도 Representation을 보조
- 짧은 범위, 긴 범위의 Attention을 혼합하여 다중 해상도에서 특징 정보가 교환될 수 있도록 함
- 이미지를 겹치지 않는 Window로 나누어 Self-Attention을 진행 -> 메모리 소모량, 계산 복잡도를 제곱에서 선형으로 줄임
- Self-Attention 뒤에 3x3 Depth-wise Convolution + FFN을 도입하여 분리된 Window 간에 정보를 교환할 수 있도록 만듦
HRNet에 대한 설명은 여기에서 확인
그 결과 Image Classification, Pose Estimation, Semantic Segmentation에서 경쟁력있는 성능을 달성하였다.
2. Related Work
Vision Transformer
ViT의 등장 이후 MViT, PVT, Swin과 같은 연구가 등장하며 모델 성능은 점차 향상되어 왔다. 이 연구들은 ResNet-50의 공간 구성을 따른다는 특징을 지니는데, 본 연구에서는 이와 달리 HRNet에서 영감을 받아 모델을 설계하였다.
CvT, CeiT, LocalViT 같은 연구들은 Depth-wise Convolution을 Self-Attention이나 FFN에 삽입하여 Transformer 모델의 Locality를 향상시키려 시도하였다. 본 연구에서는 이러한 Depth-wise Convolution을 차용한 이유를 Locality 향상 뿐만 아니라 겹치지 않는 Window 간의 정보를 교환하기 위함이라고 말한다.
겹치지 않는 Window를 사용했다는 것이 어찌보면 기존 ViT의 Patch와 같다고 볼 수 있을 것 같다.
High-Resolution CNN for Dense Prediction
고해상도 CNN을 만드는 기법에는 크게 3가지가 존재한다.
- Downsampling을 하지 않기 위한 Dilated Convolution 사용하기
- Decoder를 사용하여 고해상도 복원하기
- 전체 네트워크 동안 고해상도를 유지하기(HRNet)
본 논문에서는 3번째 기법을 사용하였으며 ViT와 HRNet의 장점을 모두 가지도록 설계하였다.
3. High-Resolution Transformer
Multi-resolution parallel transformer
다중 해상도 병렬 디자인으로는 크게 HRNet의 디자인을 따르며 고해상도 Convolution Stem에서 시작하여 매 Stage마다 저해상도로 가는 Stream을 하나씩 추가한다. 이들은 병렬로 연결되며 Figure 2를 보면 HRNet의 설계도와 비슷하지만 Transformer Block에 의한 Update가 이루어지는 것을 확인할 수 있다.
Local-window self-attention
Local -window에서 Self-Attention을 수행하는 방법은 다음과 같다.
- Feature Map을 겹치지 않는 작은 Window(K x K)로 나눈다.
- 각 Window 내에서 독립적으로 MHSA(Multi-Head Self-Attention)을 수행한다.
- 이 때 상대적 위치 임베딩(Relative Position Embedding) 기법을 적용하여 Local-Window Self-Attention에 상대적 위치 정보를 통합한다.
상대적 위치 임베딩은 T5 모델에 적용된 기법을 활용하였다.
FFN with depth-wise convolution
Local-Window Self-Attention만 사용할 경우 Window 간의 상호 정보 교환이 일어나지 않는다. 따라서 본 논문에서는 Transformer Block의 FFN 중간에 3x3 Depth-wise Convolution을 추가하였다(Figure 1).
Representation head designs
Figure 2를 보면 HRFormer의 출력은 서로 다른 4가지 해상도를 가진 Feature Map으로 구성되는데, 해결하고자 하는 Task에 따라 뒤에 붙는 Head의 설계를 달리 하였다.
- ImageNet Classification
- 4가지 해상도 Feature Map을 BottleNeck Layer에 보내 채널을 변경(128, 256, 512, 1024)하고 Fusion한 후 2048 채널의 가장 낮은 해상도 Feature Map을 생성
- 이후 GAP(Global Average Pooling)을 적용하여 최종 Classifier를 연결
- Pose Estimation
- 가장 높은 해상도의 Feature Map에만 Regression Head를 연결
- Semantic Segmentation
- 저해상도 Representation들을 모두 가장 높은 해상도로 Upsampling한 후 연결
- 결합된 Representation 위에 Semantic Segmentation Head를 연결
Instantiation

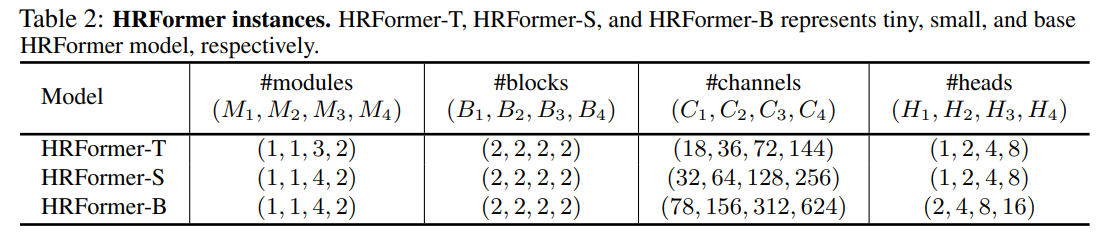
Table 1은 HRFormer의 전체 아키텍처 구성을 나타낸다. 기본적인 윈도우 크기는 7x7로 설정하였고 Table 2에서는 복잡도가 증가하는 3가지 HRFormer 인스턴스의 구성을 보여준다. 모든 모델에서 MLP expansion ratio(R)은 4로 설정하였다.
Analysis
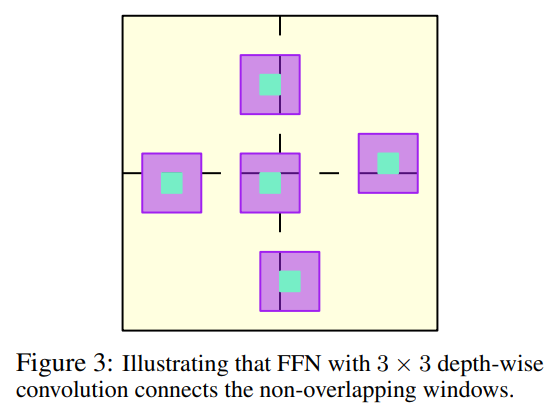
3x3 Depth-wise Convolution은 (1) Locality의 강화 (2) Window 간 상호 작용을 가능케 하는 것 2가지 장점을 가진다. Figure 3를 보면 3x3 Depth-wise Convolution을 포함한 FFN이 상호작용을 어떻게 확장하는 지 확인할 수 있다. 이러한 방법은 메모리 및 계산 효율성을 크게 향상시킨다.
4. Experiments

4.1. Human Pose Estimation
Training setting
실험은 COCO Pose Estimation Benchmark로 진행하였으며 MMPose의 기본적인 Train, Test 설정을 따랐다. 실험은 32G짜리 V100 8개로 진행하였다고 한다.
Results
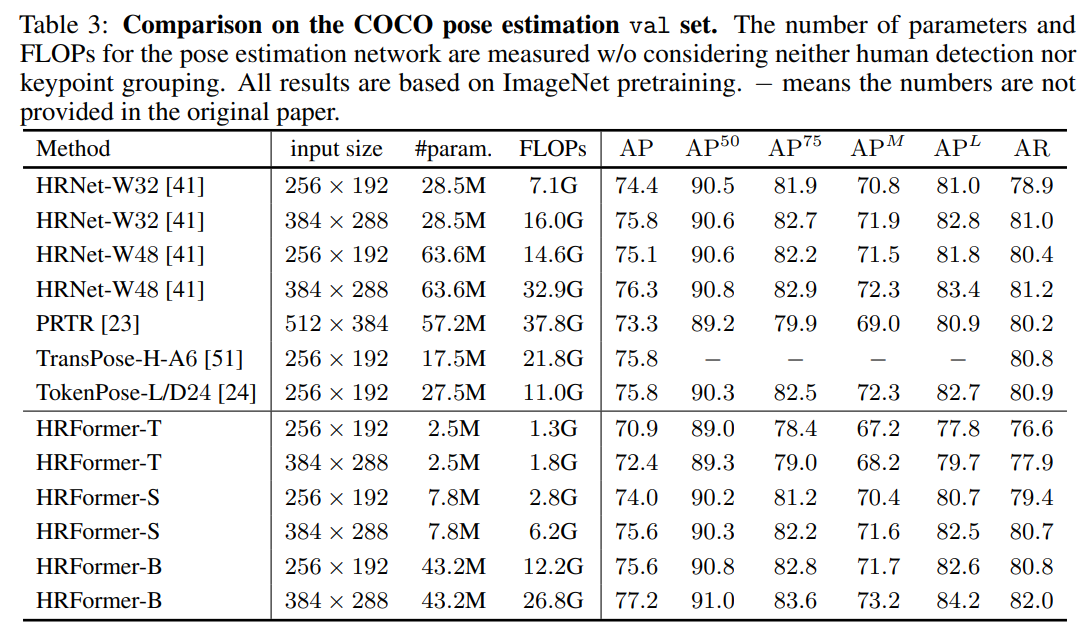
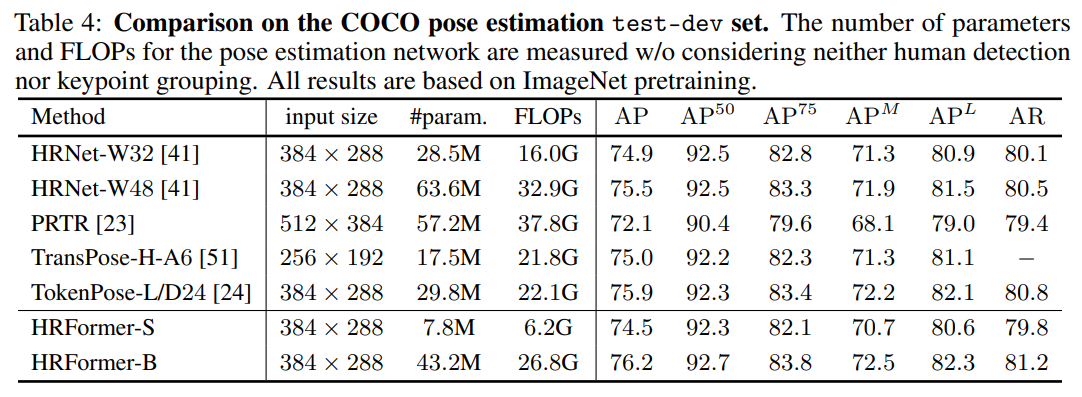
실험 결과는 Table 3와 Table 4에 나타난 것과 같다. 대표적인 Convolution 기법인(영감을 받은) HRNet과 최근 Transformer 기반의 방법론인 PRTR, TransPose, TokenPose 모델들과 성능을 비교하였으며 UDP나 DARK 같은 고급 기법을 사용하지 않고도 더 나은 성능을 보였다(UDP나 DARK 기법을 사용하면 더 좋은 성능을 보일 것이라 기대).
4.2. Semantic Segmentation과 4.3. ImageNet Classification 부분은 원하는 Task가 아니라 설명 제외
4.4. Ablation Experiments
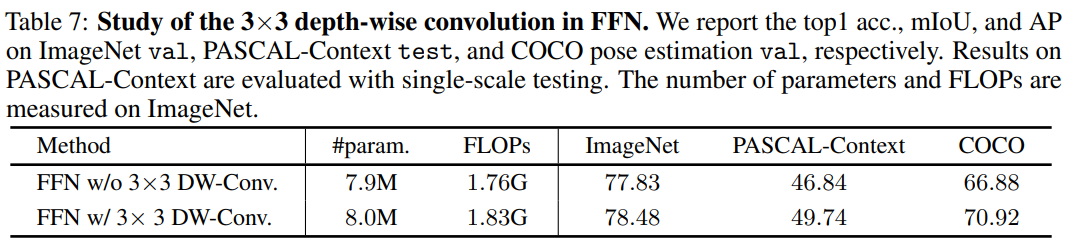
Table 7은 FFN 내에 적용한 3x3 Depth-wise Convolution의 효과를 알아보기 위한 실험 결과이다. 적용한 경우가 적용하지 않은 경우보다 성능이 좋았다는 것을 알 수 있다.
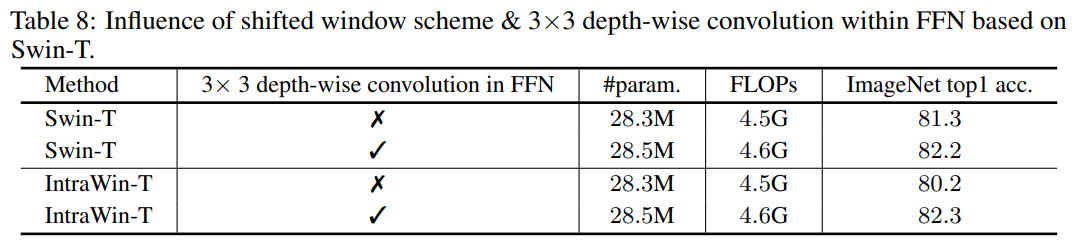
Table 8에서는 Swin Transformer에서 사용한 Shifted-Window 방법을 HRFormer의 기법과 비교하였다. 놀랍게도 본 논문에서 활용한 3x3 Depth-wise Convolution을 활용하였을 때 Swin Transforemr, IntraWin Transformer 모두에서 성능이 향상되었다.

결국 HRFormer에서도 Shited Window 기법보다 3x3 Depth-wise Convolution을 사용한 것이 성능이 더 좋은 것을 확인하였다.
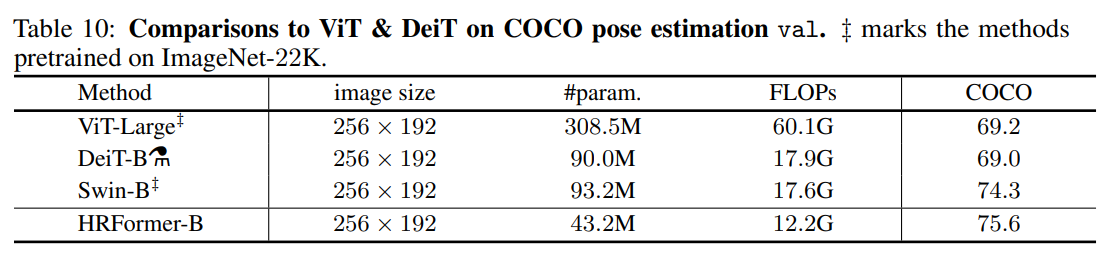
Table 10에서는 Transformer 기반의 모델들을 사용한 Pose Estimation 결과를 비교한다. Pose Estimation을 목표로 만들어진 모델들이 아니다보니 당연하게도 HRFormer의 성능이 더 높게 나온 것을 알 수 있다.
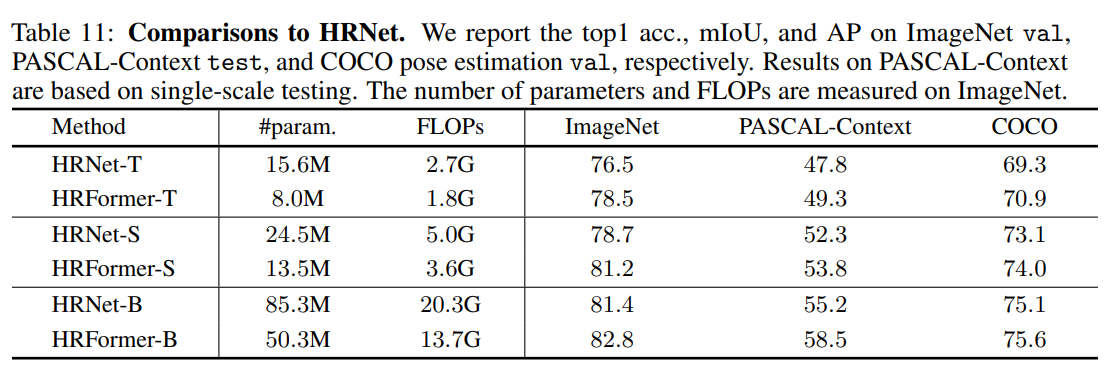
HRNet과 비교하였을 때 HRFormer가 Transformer 기반인데에도 더 적은 계산 복잡성을 가지고 더 높은 성능을 보이는 것을 확인할 수 있었다.
이번에 읽어 본 논문은 HRNet과 ViT의 기법을 섞어 만든 HRFormer이다. HRNet 논문을 읽어보았기 때문에 쉽게 논문이 읽혔던 것 같고 핵심적인 개념 또한 HRNet 구조를 기반으로 Transformer Block을 사용한 느낌이라 어렵지 않았던 것 같다. 놀라웠던 점은 Transformer 구조를 차용하였는데 기존 HRNet보다 연산량이 적다는 점이 었으며 Image Classification, Semantic Segmentation, Pose Estimation 3개의 Task에서 모두 성능 개선을 이루어냈다는 점에서 특별한 Contribution이 있는 것 같다.
물론 아쉬운 점도 존재한다. Transformer 구조를 차용하였음에도 성능 개선 정도가 미미하다는 점, UDP나 DARK같은 기법의 활용 여부를 언급만 해둔채로 실험을 진행하지 않은 점들이 아쉽게 느껴진다(UDP나 DARK를 사용하였을 때 성능이 떨어질 수도 있으니...). 전체적으로 담백하게 쓰여진 논문이라고 생각하고 만약 내가 논문을 작성한다면 이런식으로 어떤 모델을 베이스로 어떤 기법을 활용하였고 그 실험 결과는 어떤지 깔끔하게 정리하여 제출하고 싶다.
세 줄 요약
1. HRNet 모델 구조를 바탕으로 ViT의 장점을 적용한 HRFormer 모델을 제안하였다.
2. 겹치지 않는 Window에서의 Self-Attention과 Depth-wise Convolution을 활용하여 전역적, 지역적 모두에서 효율적인 이미지 분석을 가능케 하였다.
3. Image Classification, Pose Estimation, Semantic Segmentation 3가지 Task에서 모두 기존 모델 대비 성능을 향상시켰다.

'논문 paper 리뷰' 카테고리의 다른 글
| [Paper Review] SimCC 논문 이해하기 (0) | 2024.11.24 |
|---|---|
| [Paper Review] Unbiased Data Processing for Human Pose Estimation 논문 이해하기 (1) | 2024.09.12 |
| [Paper Review] HigherHRNet 논문 이해하기 (2) | 2024.09.08 |




댓글