『 RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose. arxiv. 2023. 』
이번에 소개할 논문은 이전에 리뷰했던 SimCC 모델의 방법론을 활용하여, 더 빠른 속도로 모델 추론이 가능하게끔 설계한 RTMPose 논문이다. 지금까지 내가 실제 테스트를 돌려보았을 때 가장 속도와 성능의 밸런스가 좋았던 모델이었던 것 같고, 아직 논문이 Publish는 되지 않았지만, 아래 Github 링크와 같이 MMPose Framework에 녹아져 있어 학습이나 추론에 충분이 활용할 수 있는 모델이다.
정말 많은 모델에 대해 실험을 진행하였으며, 따라서 실험과 방법, 저자가 말하는 Contribution에 초점을 맞추어 논문을 읽어보려 한다.
Github
https://github.com/open-mmlab/mmpose/tree/main/projects/rtmpose
mmpose/projects/rtmpose at main · open-mmlab/mmpose
OpenMMLab Pose Estimation Toolbox and Benchmark. Contribute to open-mmlab/mmpose development by creating an account on GitHub.
github.com
0. Abstract
최근 2D Human Pose Estimation 연구는 좋은 벤치마크를 보이고 있지만, 모델 파라미터가 많고 latency가 높아 실제 산업 분야에서 활용하기 어렵다. 따라서 본 논문은 이러한 문제를 해결하기 위해 MMPose를 기반으로 빠른 속도를 내는 RTMPose를 제안한다.
Abstract부터 우리는 모델의 속도를 높이는 연구를 할 것이라고 딱 정해두고 가는 모습이다.
1. Introduction

실시간 Human Pose Estimation은 Human Computer Interaction, Sports Anaylsis, VTuber 등 다양한 응용 분야에서 주목받고 있지만, 아직 실시간으로 Multi-Person Pose Estimation을 수행하는 것은 어렵다. 이러한 문제를 해결하기 위해 본 논문에서는 2D Multi Person Pose Estimation Framework의 성능과 latency에 영향을 미치는 요소를 5가지(Paradigm, Backbone network, Localization method, Training strategy, Deployment)로 구분하여 이를 경험적으로 분석하였다.
본 논문에서는 여러 분석을 통해 다양한 기법의 장점을 모은 RTMPose를 제안한다. 우선 방법론으로는 Top-Down 방식을 차용하였는데, 그 이유는 기존 Top-Down 방식은 정확하지만 느리다는 고정관념이 있었지만 최근 Object Detector의 발달로 Top-Down 방식을 사용하더라도 충분히 실시간 성능을 낼 수 있기 때문이다. Backbone으로는 CSPNeXt를 사용하였으며, Head로는 SimCC 기반의 알고리즘을 사용하여 더 낮은 계산 비용으로 경쟁력 있는 정확도를 가지도록 구성하였다.
또한 BlazePose에서 제안된 Skip-frame detection 전략을 사용하여 Latency를 줄이고, Robustness를 위한 NMS, Smoothing Filtering을 사용하였다. 실험으로는 다양한 Inference Framework에서 테스트를 진행하였으며, Figure 1에서처럼 빠른 속도와 효율성에서 장점을 보였다.
2. Related Work
Related Work 파트에서는 이전까지의 Bottom-Up, Top-Down, Coordinate Classification(SimCC), Vision Transformer에 대한 내용을 다룬다. 관련된 내용은 지금까지 봤던 다수의 Human Pose Estimation 내용과 비슷하다. 자세한 내용은 논문을 참고.
3. Methodology
3.1. SimCC: A lightweight yet strong baseline
RTMPose는 효율적인 Backbone 아키텍처를 사용한데에 더하여 SimCC를 재구성하여 경량화되면서도 강력한 모델 아키텍처를 구현하였다. SimCC는 Heatmap 위주의 Pose Estimation 연구 방법을 Classification 문제로 변환하여 정의한 방법론으로 수평 및 수직 축을 가지고 세분화된 bin으로 나누어 Quantization Error를 극복한 방법이다. 또한 Label Smoothing 기법을 사용하여 Gaussian기반의 Soft Labeling을 가능하게 만들어 모델 학습 과정에 Inductive Bias를 넣어 성능을 향상시켰다. (자세한 설명은 SimCC 리뷰를 참고)
RTMPose는 기존 SimCC 구조에서 비용이 많이 발생하는 Upsampling layer를 제거하였다. 그 결과 Table 1에서 볼 수 있듯이 Upsampling layer를 제거한 SimCC*의 계산복잡도가 크게 감소한 것을 확인할 수 있다(성능은 어느정도 유지하면서).
이부분에서 이해안되는 점
SimCC는 Upsampling layer를 제거하는게 핵심인 방법론으로 Head단이 아예 classifier 형태로 바뀐 것으로 알고 있는데, 어디에 있는 Upsampling layer를 제거했다는 것인지?
👉 Code Check
MMPose에 있는 SimCC 코드를 살펴보니 Coordinate Classification을 계산하기 전 _make_deconv_head 함수에 의해 Deconvolution이 이루어지는 것을 확인하였다. SimCC 논문에서는 Deconv=0이라는 점을 강조하여 이 부분이 원 저자의 의도와 같은지는 모르겠지만, RTMPose에서 말하는 Upsampling layer를 제거하였다는 것이 어떤 의미인지(config에서
deconv_type 인자를 None으로)는 이해하였다.
기존 SimCC 논문에서 Backbone으로 사용한 ResNet-50을 CSPNeXt-m으로 교체하여 69.7% AP까지 달성하였다.
3.2. Training Techniques
Figure 3에서 볼 수 있듯이 다음으로는 UDP 방식으로 Backbone을 Pretrain하여 성능을 70.3% AP까지 올렸으며, 다음의 최적화 전략을 사용하여 성능을 더 끌어올렸다.
- EMA(Exponential Moving Average) : 70.3% -> 70.4%
- Flat Cosine Annealing(Learning rate 감소 전략) : -> 70.7%
또한 RTMPose에서는 2단계의 Augmentation을 진행하였는데 Strong Augmentation과 Weak Augmentation을 결합하여 사용하였다. 구체적으로는 180 Epoch 동안에는 Random rotation factor가 높은 80을 사용하였고 Cutout 확률은 1로 두었으며(Strong Augmentation), 이후 30 Epoch 동안에는 작은 Random rotation factor를 사용하고 Cutout 확률도 0.5로 설정하였다. 이러한 전략은 더 다양한 데이터 분포를 학습하면서 실제 환경에 잘 적응할 수 있기 위해 사용하였다(-> 71.0%).
글에는 생략되어 있지만 Figure 3을 보면 Normalization layer와 Bias에 Weight Decay를 진행하지 않아 71.2% 까지 성능을 올린 것을 확인할 수 있다.
3.3. Module Design
일반적으로 모델 성능은 Feature Dimension이 높아질수록 향상되기 때문에 1D Keypoint Representation을 256 차원(Hyperparameter)으로 확장하였고, 이를 통해 성능이 71.4%로 향상되었다.
이 부분에 있어 근거가 부족하다고 느꼈다. 기존 HRNet과는 달리 SimCC의 핵심 아이디어는 Feature Dimension을 줄이면서 모델 파라미터를 줄이는 것이였는데 여기서는 다시 줄였던 Representation을 키워주었다. 그럴거면 아예 Backbone에서 나오는 결과를 1D가 아닌 해당 Representation 크기로 출력되게 설계하면 되지 않을까?
FC Layer를 거쳐 Representation을 확장시킨 후에는 Self-Attention 모듈을 활용하였다. GAU(Gated Attention Unit) 아키텍처를 사용하였으며, 기존 Transformer 대비 속도가 빠르고 메모리 비용이 낮다는 장점을 가진다. GAU는 Transformer Layer의 FFN(Feed Forward Network)을 GLU(Gated Linear Unit)으로 개선하고 Attention 매커니즘을 적용한 방법이다.
이러한 Self-Attention 모듈을 적용하여 모델 성능을 71.9%로 향상시켰다.
3.4. Micro Design
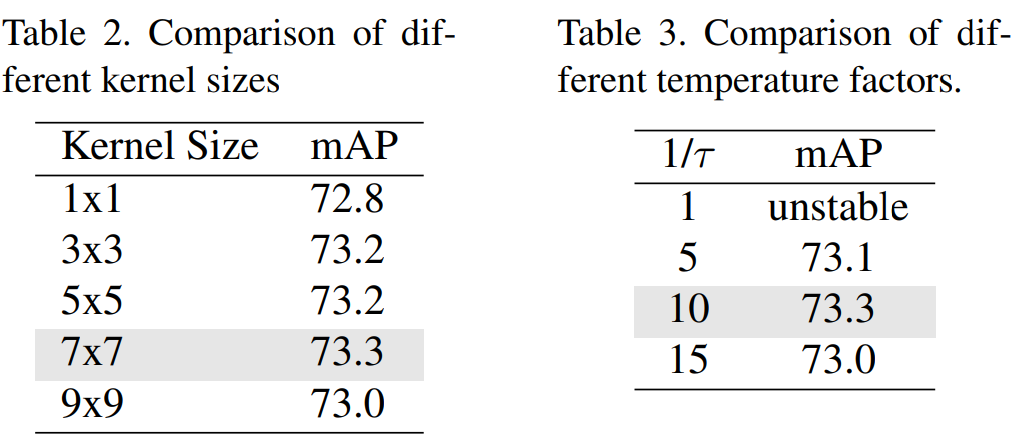
Loss Function
Coordinate Classification을 Ordinal Regression 문제로 간주하여 SORD에서 제안한 Soft Label Encoding 방식을 적용하였다. 또한 Temperature를 Softmax에 적용하여 모델의 출력과 Soft Label의 정규화 분포를 조정함(τ=0.1 일 때 72.7%로 향상)
Seperate σ
SimCC에서 수평 및 수직 축에 동일한 σ를 사용했던 기존 방식을 개선하여 별도의 σ를 사용함(72.8%로 개선)
0.1 AP 상승은 다른 요인에 대해서도 충분히 달라질 수 있을 것 같은데 효과가 있다고 볼 수 있는건지..?
Larger Convolution Kernel
실험을 통해 마지막 Convolution 층의 Kernel 크기가 7x7일 때 가장 좋은 성능을 보임(Table 2, 73.3%)
More Epochs and Multi-Dataset Training
학습 Epoch를 증가하여 270 Epoch에서 73.5%, 420 Epoch에서 73.7%로 성능이 향상되었고 Pretrain과 Fine-Tuning 과정에서 COCO + AI Challenger 데이터를 모두 사용하여 최종적으로 75.3%의 성능을 낼 수 있었다.
3.5. Inference Pipeline
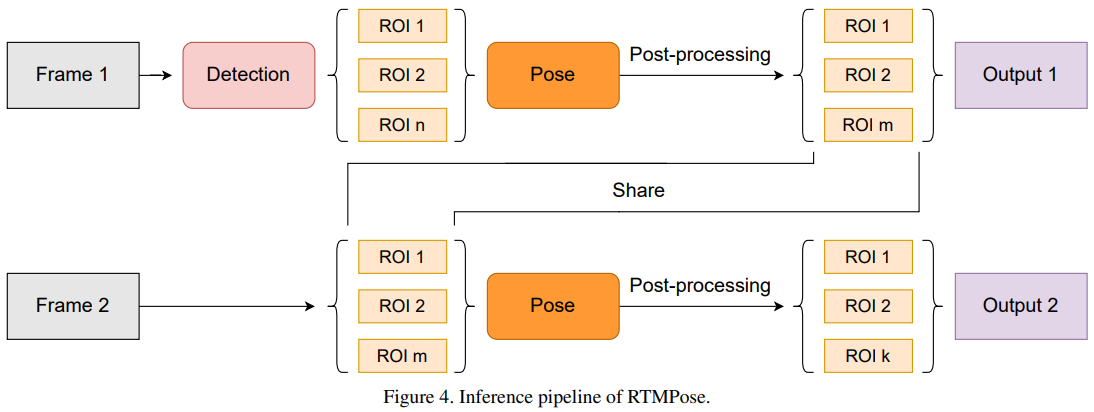
Inference 과정에서는 BlazePose에서 영감을 받아 Skip-Frame Detention을 사용하였다.
Skip-Frame Detection
K Frame마다 Human Detection을 수행하며, 사이에 있는 Frame에는 이전의 Pose Estimation 결과를 사용해 Bounding Box를 만들어 latency를 크게 낮추었다.
또한 Post-Processing으로는 OKS기반의 Pose NMS와 OneEuro Filter를 사용하였다. 여기서 OneEuro Filter는 Pose Estimation 결과를 Smooth하게 보정하는 역할을 수행한다.
SimCC의 경우 계산 복잡도가 많아지는 Post-Processing을 제거하였는데, RTMPose에서는 성능을 더 높이기 위해 Post-Processing을 추가하여 사용한 것으로 보인다.
4. Experiments
4.1. Setting
Pretrain으로는 UDP를 사용한 Heatmap 기반 방법을 사용하였고 8개의 A100으로 실험을 진행하였다.
4.2. Benchmark Results
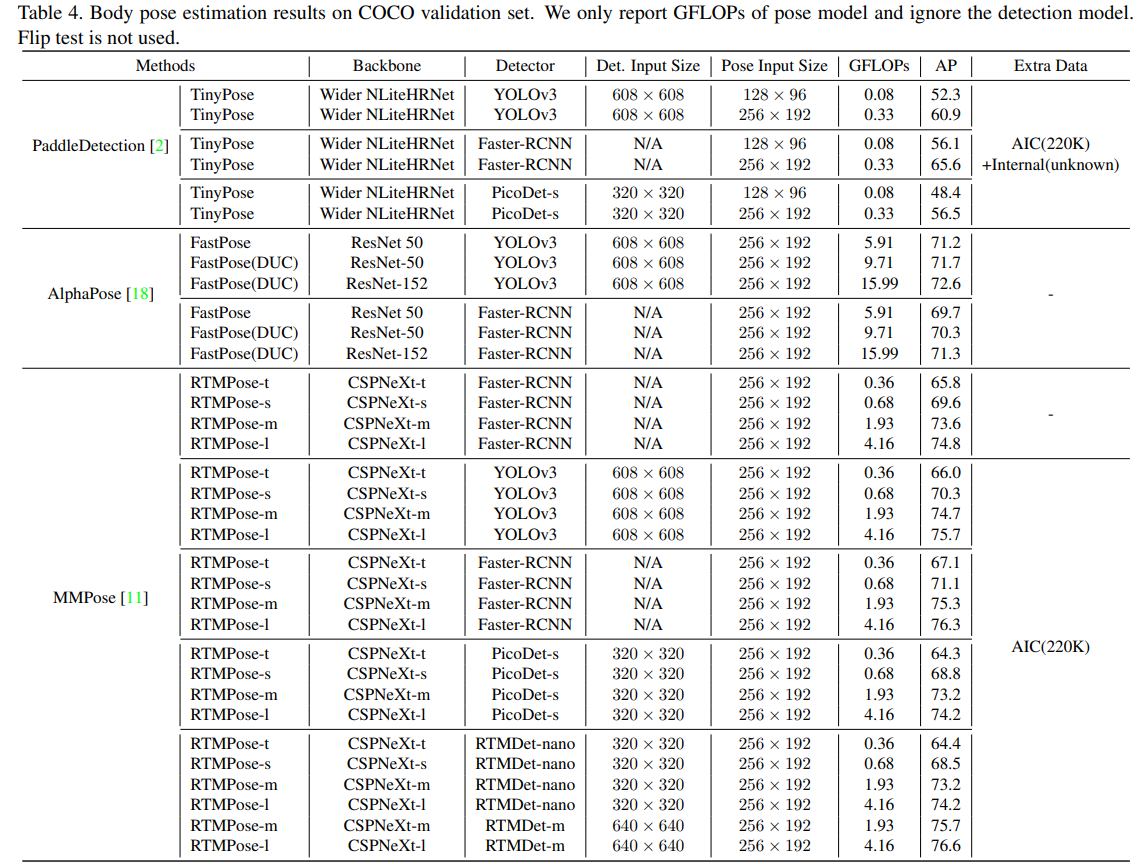
Table 4를 보면, COCO Dataset에서 RTMPose의 성능이 경쟁 모델들의 성능보다 크게 높은 것을 확인할 수 있다.
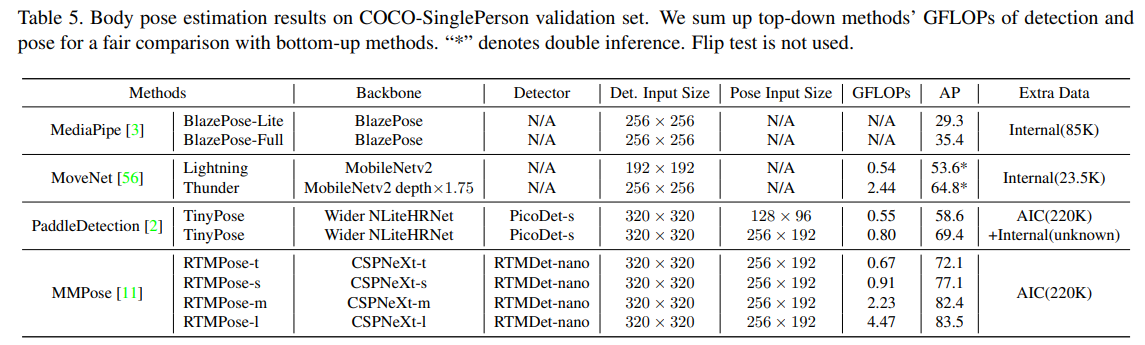
COCO-SinglePerson 데이터 셋에서도 좋은 모습을 보였으며
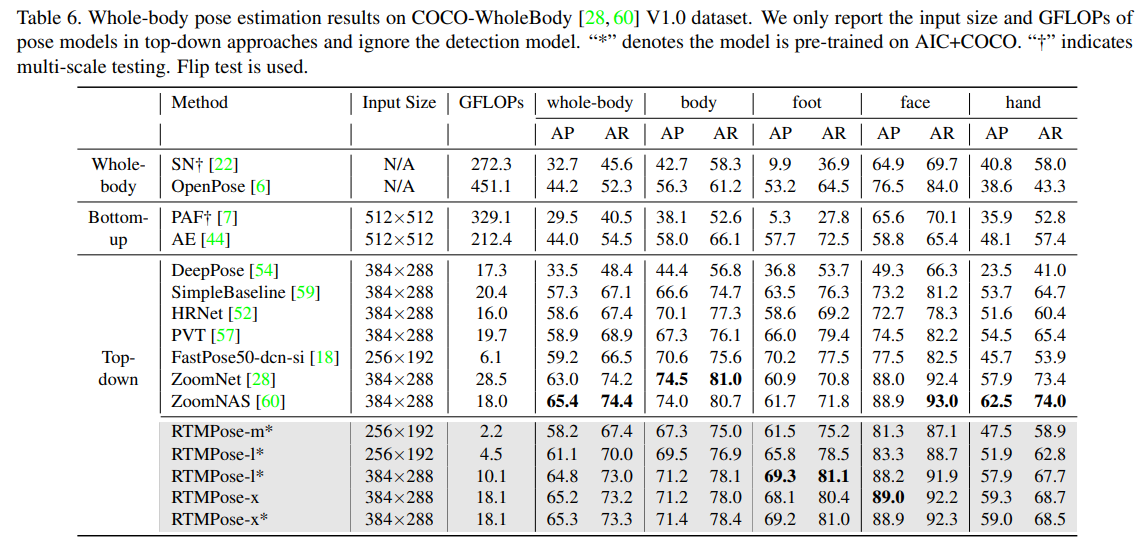
WholeBody 데이터셋에서도 GFLOPS는 크게 낮추었으며 그만큼 성능(AP)을 방어하였다.
다른 데이터 셋인 AP-10K, CrowdPose, MPII 데이터 셋에서도 평가를 진행했으며, GFLOPs는 낮추고 AP, PCKh 성능은 높이는 결과를 얻을 수 있었다(자세한 실험 결과는 논문 참고)
4.3. Inference Speed
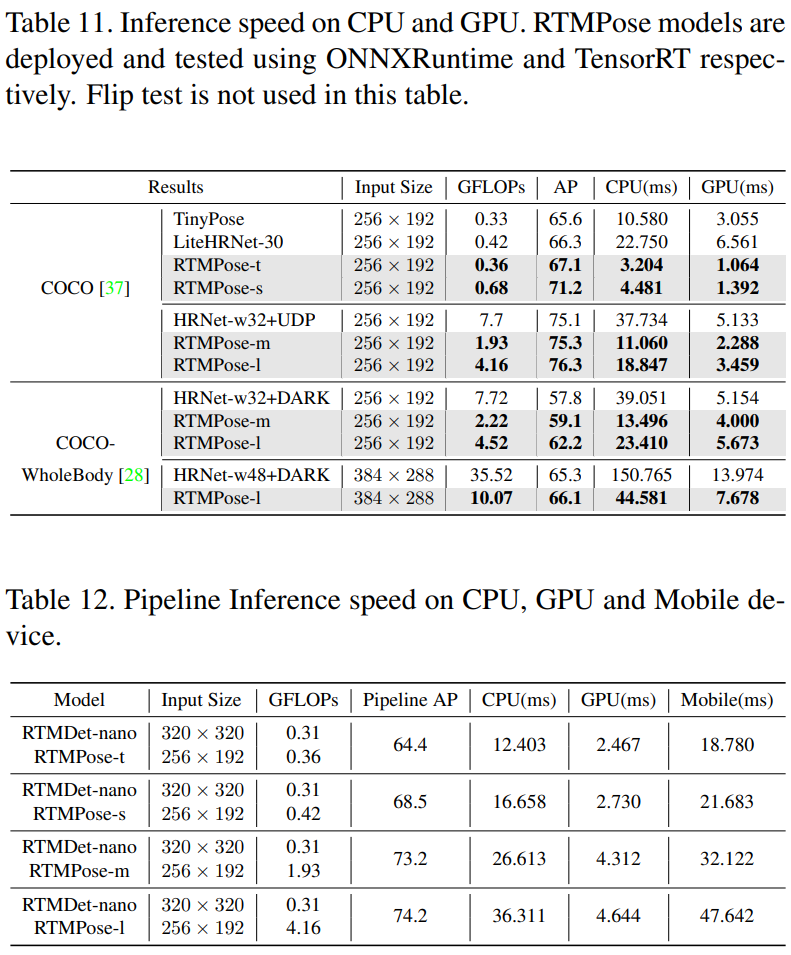
MMDeploy를 활용하여 Inference 속도 테스트를 진행하였다. FP16은 GTX 1660 Ti GPU에서, ONNX와 ONNXRuntime은 I7-11700 CPU에서 1개의 thread만으로 테스트를 진행하였다. Table 11을 보면 기존 모델들 대비 빠른 연산 속도와 높은 AP를 기록한 걸 확인할 수 있다.
5. Conclusion
이 논문에서는 Pose Estimation의 중요한 요소인 Paradigm, Model Architecture, Training Strategy, Deployment에 대해 탐구하였다. 그 결과 여러 실험을 통해 RTMPose라는 성능과 속도의 균형을 맞춘 밸런스있는 모델을 제안하였다. 본 알고리즘과 오픈소스의 구현을 통해 본 저자들은 산업에서의 실용적인 Pose Estimation 수요를 충족하고, 추후 Human Pose Estimation 연구에 기여할 수 있기를 기대한다.
RTMPose 논문은 아직 Publish가 되지 못한 논문이다. OpenReview 사이트를 통해 RTMPose Paper 리뷰를 살펴보면, 논문이 제출된 ICLR Conference가 추구하는 바와 맞지 않다는 점이 Reject 된 가장 큰 이유로 보인다. 물론 논문을 읽고나서 공식 리뷰를 읽어보면 고개를 끄덕이게 되는 리뷰가 많다. Introduction에서 이야기한 Pose Estimation의 성능과 Latency에 영향을 미치는 5가지 요인에 대한 탐구가 부족하다는 점(ViTPose 처럼 아예 섹션을 나누었다면 어땠을까), 흥미로운 Insight 없이 Hyperparameter Tuning만을 진행한 것으로 보인다는 점, 이러한 문제들이 논문을 읽고 나니 충분히 이해가 되는 점들이었다. 실제로 논문을 읽으면서 성능을 어떻게 개선하였다 점들을 기록한 일기 느낌을 받기도 하였는데, 사실 Application 활용면에서는 결과만 좋으면 된다고 생각할 수도 있어 논문 Accept에 대해서는 참으로 어려운 문제인 것 같다.
그럼에도 RTMPose가 오픈 소스라는 점과 실제 코드를 실행해보았을 때의 속도와 성능의 균형이 매우 좋기 때문에, Pose Estimation을 다루는 사람이라면 한번쯤은 다뤄보면 좋을 모델이라고 생각한다. 아직까지 사용해본 2D Human Pose Estimation 모델 중에 이보다 더 실시간성과 성능의 균형을 잘 잡은 모델은 보지 못하였다.
이건 적다보니 생각이 난 점인데, 전체적인 모델 개선이 정말 디테일한 하이퍼파라미터 튜닝처럼 진행돼서 실험결과가 과적합된 결과일 수도 있을 것 같다.
세 줄 요약
1. Human Pose Estimation 기술을 응용 Application이나 산업단에서 사용할 수 있도록 더 빠르고 성능이 좋은 모델을 개발하고자 함
2. 지금까지 존재하는 여러 기법(CSP-NeXt, SimCC 등)들과 디테일한 구조에 대한 튜닝을 진행하여 성능과 속도의 균형을 잡은 RTMPose 모델을 제안함
3. COCO, MPII 등의 다양한 Pose Estimation 데이터 셋에서 성능은 보전한채 속도를 많이 높일 수 있었으며, ONNX와 TensorRT 변환 속도를 측정하여 충분히 모델이 실시간 분석에 사용될 수 있음을 확인함

'논문 paper 리뷰' 카테고리의 다른 글
| [Paper Review] ControlNet 논문 이해하기 (0) | 2024.12.02 |
|---|---|
| [Paper Review] SimCC 논문 이해하기 (0) | 2024.11.24 |
| [Paper Review] HRFormer 논문 이해하기 (1) | 2024.10.08 |




댓글