『 HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation. CVPR. 2020. 』
HRNet이 Top-Down 모델에서 굉장히 좋은 성능을 냈다고 하면, 이번에는 HRNet의 기법을 Bottom-Up 기반의 모델에 적용시킨 HigherHRNet이 등장하였다. Bottom-Up 모델은 아무래도 시간이 빠른 대신 관절의 위치를 정확히 잡는 정확도가 문제가 되었는데 High-Representation을 사용하여 그 점을 충분히 완화한 점을 보여준 논문이다.
Github
https://github.com/HRNet/HigherHRNet-Human-Pose-Estimation
GitHub - HRNet/HigherHRNet-Human-Pose-Estimation: This is an official implementation of our CVPR 2020 paper "HigherHRNet: Scale-
This is an official implementation of our CVPR 2020 paper "HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation" (https://arxiv.org/abs/1908.10357) - HRNet...
github.com
0. Abstract
본 논문에서는 고해상도 Feature Pyramid를 사용하여 Scale-aware Representation을 학습하는 Bottom-Up 방식인 HigherHRNet 모델을 제안한다. 이 때의 Feature Pyramid는 HRNet의 Feature Map Output과 Transposed Convolution을 통해 Upsampling된 고해상도 Output으로 구성된다.
Bottom-Up 방식은 Scale Variation 때문에 작은 사람의 Pose를 잘 잡아내지 못하는 문제가 있었는데, HigherNet에서 제안하는 Multi-Resolution Supervision과 Multi-Resolution Aggregation으로 이러한 문제를 덜 수 있었다. 때문에 이전까지의 Bottom-Up 방식 모델보다 더 좋은 성능을 얻을 수 있었다.
1. Introduction

Pose Estimation의 방법론은 크게 Top-Down과 Bottom-Up 2가지로 나뉜다. Top-Down 방법의 경우 탐지한 사람의 Bounding Box를 Crop하고 Resize하기 때문에 사람의 Scale Variance에 덜 민감하다. 한편 Bottom-Up 방법의 경우 어떤 사람의 Keypoint인지를 모른채 모든 사람의 관절을 우선 추정한 후 같은 사람의 관절끼리 Grouping을 진행한다. 때문에 Scale Variation 문제를 다루는데 있어 어려움이 존재한다(특히 이미지 속에서 작게 나타난 사람들). 실제로 Top-Down과 Bottom-Up 방법론의 성능은 꽤나 많은 차이가 나고 있다.
물론 Top-Down 방법에도 단점이 있고 Bottom-Up 방법에도 장점이 있다. Top-Down의 단점은 사람을 먼저 탐지한 이후 Pose Estimation을 해주기 때문에 Detector 성능이 중요하고 End-to-End 구조를 가질 수 없다는 점이며 Bottom-Up의 장점은 추론 속도가 빨라 Real-time을 바라볼 수 있다는 것이다.
Bottom-Up 방법론에서 작은 사람을 예측하기 위해 주목해야 할 점은 다음의 2가지이다.
- Scale Variation을 잘 다루는 것. 지금까지는 작은 사람에 대한 정확도를 올릴 경우 큰 사람에 대한 정확도가 떨어졌다.
- 작은 사람의 Keypoint를 정확하게 예측하기 위해 고해상도 Heatmap을 만드는 것.
지금까지의 Bottom-Up 방법들은 Keypoint를 Grouping 하는 것에 집중하거나 입력 이미지 해상도의 1/4 크기의 Feature Map 만을 사용하였다. 이러한 방법들은 Figure 1 (a)처럼 Scale Variation을 고려하지 않고 Image Pyramid에만 의존한 결과이며, Image Pyramid가 물론 Scale Variation을 생각한 방법이기는 하지만 작은 해상도의 Representation을 다시 정확한 고해상도 Heatmap을 만들어 내는데에 어려움이 존재한다.
따라서 본 논문에서는 이러한 과제를 해결하기 위해 HigherHRNet(Scale-aware High-Resolution Network)을 제안한다. HigherHRNet은 새로운 고해상도 Feature Pyramid 모듈을 사용하여 고해상도 Heatmap을 생성한다. 기존 Feature Pyramid가 Feature Map 크기를 1/32 해상도에서 시작하여 1/4 해상도로 점차 증가시켰다면, HigherHRNet에서는 1/4 해상도에서 시작하여 Deconvolution을 통해 더 높은 해상도의 Feature Map을 생성한다(Figure 1 (c)). 또한 HigherHRNet이 다양한 해상도에서 Scale Variation을 처리할 수 있도록 Multi-Resolution Supervision과 Multi-Resolution Heatmap Aggregation 방법을 사용하였다.
그 결과 기존 Bottom-Up 방법론을 사용한 모델들을 제치고 SOTA를 달성하였으며, 주요 Contribution은 다음과 같다.
- Bottom-Up에서 거의 연구되지 않은 Scale-Variation 문제를 다룸
- 고해상도 Feature Pyramid를 생성하고 작은 사람을 잘 인식하는 HigherHRNet 제안
- COCO 데이터 셋과 CrowdPose 데이터 셋에서 좋은 성능을 보임
2. Related works
Top-Down Methods 와 Bottom-Up Methods의 일반적인 방법론에 대해 소개하고 있다. 이에 대해서는 지금까지 여러번 정리를 해왔기 때문에 생략(논문 참고).
OpenPose를 설명하는 부분에 오타 발견 netork -> network ㅎㅎ
Feature Pyramid
Scale Variation을 해결하기 위해 논문이 등장한 시기의 많은 Object Detection이나 Segmentation 모델들이 Pyramid 형태의 Representation을 사용하고 있다(SSD, FPN 등등). 하지만 Pose Estimation Task에서는 아직 Pyramid Representation에 대한 연구가 많지 않아 본 논문에서는 1/4 해상도에서 시작하여 고해상도 Feature Pyramid를 만드는 구조를 사용하였다(FPN 모델이 1/32 -> 1/4).
High Resolution Feature Maps
High Resolution Feature Map을 만드는 방법에는 4가지 종류가 있다.
- Encoder-Decoder : Encoder에서는 Context 정보를 축약하고 Decoder에서는 주로 Bilinear Upsampling + Skip Connection을 통해 원래의 해상도 Feature를 생성
- Dilated Convolution : Convolution 과정에서 Feature Map 해상도를 유지하는데에 활용. 공간 정보를 보존하는데 도움이 되지만 연산량이 많다는 단점이 있음
- Deconvolution(Transposed Convolution) : 일반적으로 네트워크의 마지막 부분에 사용하여 해상도를 높여줌(ex. Simple Baseline).
사실 Deconvolution과 Transposed Convolution은 엄밀히 다르다고는 하지만 본 논문에서는 동일하게 보고 설명하고 있다.(참고자료) - HRNet(High-Resolution Network) : 고해상도 Representation을 유지하는 네트워크 구축. 저해상도에서는 Contextual 정보를, 고해상도에서는 공간적인 정보를 보존하고 이를 잘 융합.
이러한 방법론들 중 본 논문에서는 Feature Map을 만드는 데에는 HRNet을, 만들어진 Feature Map을 가지고 Heatmap을 추론하기 위해서는 Deconvolution 방법을 채택하였다.
3. Higher-Resolution Network

3.1. HigherHRNet
HigherHRNet에서는 HRNet 모델을 Backbone으로 사용하였다. HRNet은 첫번째 Stage를 고해상도로 시작하여 Stage가 거듭날수록 현재 Stage내에 있는 Branch(SubNetwork) 중 가장 해상도가 낮은 Branch를 기준으로 1/2 크기의 해상도를 가진 Branch를 추가한다. 이전 Stage에 존재하던 Branch는 그대로 다음으로 이어지며 Stage가 진행될 수록 해상도가 절반이 된 Branch가 추가된다고 생각하면 된다. Figure 2의 앞 부분에 3개의 Branch를 가진 HRNet 구조가 나타나 있다.
본 논문에서는 이러한 HRNet의 방법론 대로 Backbone을 인스턴스화 하였다.
- Stem :Input Image의 해상도를 1/4로 만들어주는 Stride=2, 3x3 Convolution layer를 가짐
- 1st Stage : 4개의 Residual Unit(Channel이 64인 BottleNeck 구조) + 3x3 Convolution(Channel 개수를 $C$로)
- 2nd, 3rd, 4th Stage : 각각 1, 4, 3개의 Multi-Resolution Block
- Stage마다 Branch가 추가될때 해상도는 절반, Channel은 2배가 됨($C$, $2C$, $4C$, $8C$)
- Multi-Resolution Group Convolution안에 있는 Branch는 4개의 Residual Unit을 가짐. 각각의 Residual Unit에는 해상도마다 2개의 3x3 Convolution이 존재.
- HRNet은 Top-Down 기법으로 설계되었기 때문에 1x1 Convolution을 추가하여 Heatmap과 Tagmap을 예측하고 예측을 위해 Input 이미지의 1/4크기인 고해상도 Feature Map만 활용하였으며 각 Keypoint에 대해 Scalar Tag를 사용하였다.
여기서 Tagmap은 각 Keypoint의 소속 정보를 담은 Map을 의미한다. 특정 Keypoint가 어떤 사람의 관절인지를 알기 위해 각 Keypoint는 Scalar Tag를 가진다. 따라서 Bottom-Up 방법론에서는 Tagmap이 Heatmap과 같이 예측되어야 한다.
대부분의 Heatmap 예측 방식은 Ground Truth Keypoint에 Gaussian Kernel을 적용하여 만들어진 Heatmap을 예측한다. 기존 Bottom-Up 방식에서 문제가 되었던 "작은 사람을 잘 추정하지 못하는 문제"를 잘 해결하기 위해서는 이 Heatmap의 해상도가 중요한데, 이를 위해 Gaussian Kernel의 표준 편차를 줄이는 방식이 Trivial Solution이지만, 이 경우 최적화가 어려워지고 오히려 성능이 떨어진다.
표준 편차를 줄이면 Heatmap이 Joint 위치에 더 좁고 집중된 형태로 위치한다. 해상도는 결국 픽셀의 밀도를 의미하기 때문에 표준 편차를 줄여 특정 Keypoint에 집중되어 분포한 형태를 고해상도라고 명칭한 것
따라서 본 논문에서는 표준 편차를 유지한 채 Heatmap을 더 높은 해상도로 예측하는 방법을 제안한다. Simple Baselines 논문에서 영감을 받아 HigherHRNet에서는 HRNet의 가장 높은 해상도 Feature Map에다가 Deconvolution 모듈을 붙였다(Figure 2). HRNet의 마지막 Feature Map과 예측한 Heatmap을 Input으로 받아 2배 해상도를 가진 Feature Map을 만든다. 그 결과 1/4, 1/2 해상도를 가진 Feature Pyramid가 만들어지고 Deconvolution 모듈에서도 1x1 Convolution을 붙여 Heatmap을 예측하게 만든다.
3.2. Grouping
최근 Bottom-Up 연구에서는 Associative Embedding을 사용하여 Grouping을 진행한다. 자세한 내용은 논문 참고
https://ganghee-lee.tistory.com/49
(논문리뷰) Associative embedding : End-to-End Learning for Joint Detection and Grouping 설명 및 정리
위 사진에서 첫번째 행에서 보이는 것과 같이 Image에서 사람의 pose를 추정하는 person pose estimation과 두번째 행에 있는 instance segmentation문제는 보통 2-stage로 진행됐었다. (detecting stage & grouping stage)po
ganghee-lee.tistory.com
3.3. Deconvolution Module
Input Feature Map의 2배 크기를 가진 Feature Map을 만들기 위해 본 논문에서는 Deconvolution 모듈을 사용하였다. (Simple Baseline)처럼 4x4 Deconvolution, BatchNorm, ReLU를 통해 Upsampling을 수행하도록 설계하였다. 선택적으로 Deconvolution 후에 몇 개의 기본 Residual Block을 추가할 수 있으며 HigherHRNet에서는 4개의 Residual Block을 추가하였다.
Simple Baseline과 달리 Deconvolution 모듈의 Input이 Feature Map + Heatmap의 형태이며 각 Deconvolution 모듈의 출력 Feature Map은 최종 Heatmap을 예측하는데에 사용된다.
3.4. Multi-Resolution Supervision
다른 Bottom-Up 기반 모델들과 다르게 본 논문에서는 Multi-Resolution Supervision을 사용하였다. 이는 학습 과정에서 Scale Variation을 다루기 위함이며, 이를 위해 Ground Truth Keypoint를 HigherHRNet이 사용하는 모든 해상도에 맞게 위치시킨 후 사용하였다. 모든 해상도에 맞게 Keypoint를 위치시킨 후 표준 편차가 2인 Gaussian Kernel을 사용하여 Grount Truth Heatmap을 만들어 예측 Heatmap과 비교한 것이다.
모든 해상도에서 표준 편차를 고정시켰는데 그 이유는 서로 다른 해상도의 Feature Pyramid 구조가 서로 다른 크기의 Keypoint를 예측하는데에 충분하기 때문이다.
Loss의 경우 각 해상도에서 예측한 Heatmap과 Grount Truth Heatmap 간의 MSE를 계산하여 이를 합친 것을 최종 Loss로 산정하였다. FPN과는 달리 다른 크기의 사람을 Feature Pyramid에서 다른 Level에 배정하지는 않았다.
FPN에서는 작은 객체는 높은 해상도 Feature Map에, 큰 객체는 낮은 해상도 Feature Map에 할당함(휴리스틱하게 기준 설정)
HigherHRNet에서 FPN처럼 작은 객체는 높은 해상도에, 큰 객체는 낮은 해상도에 배정하지 않은 이유
1. FPN은 모든 객체 Class를 다루었지만 우리는 사람 객체만 다루어서
2. FPN은 4층짜리인데 우리는 2층짜리 Pyramid 구조여서
3. Keypoint끼리 상호작용이 존재하기 때문에 이들을 다른 Level로 떨어뜨리는 것이 효과적이지 않아서
한편, Tagmap의 경우에는 전역적인 추론이 필요하기 때문에 낮은 해상도에서만 예측을 진행하였다(1/4 사이즈).
3.5. Heatmap Aggregation for Inference
Inference 과정에서 Heatmap Aggregation을 진행한 방법으로는 Upsampling된 모든 해상도의 Heatmap을 평균내어 합치는 방법을 사용하였다. 다양한 해상도에서 예측한 Heatmap을 Bilinear Interpolation을 사용하여 Input 이미지 해상도로 Upsampling을 진행하였고, 여러 해상도의 정보를 활용하였다는 특징을 가진다.
이러한 방법은 결국 Scale-aware Prediction을 만들기 위함인데, 기존 Top-Down은 Bounding Box를 같은 Scale로 정규화하여 이 문제를 해결했지만 Bottom-Up 방법은 마땅한 방법이 없었기에 위와 같은 방법을 사용하였다. 예를 들어 낮은 해상도 Heatmap에서 놓친 작은 사람의 Keypoint를 높은 해상도에서는 잡아낼 수 있다.
4. Experiments
4.1. COCO Keypoint Detection
실험에 활용한 데이터 셋은 COCO 데이터 셋이다. Evaluation Metric으로는 OKS(Object Keypoint Similarity)를 사용했으며 이에 대한 AP와 AR로 평가하였다. 자세한 Training , Test Implementation은 논문을 참고(ex. 3.4.에서 언급한 것 처럼 Input Image가 512x512일 경우 256x256과 128x128 해상도에 맞는 Ground Truth Heatmap을 만들어 사용).
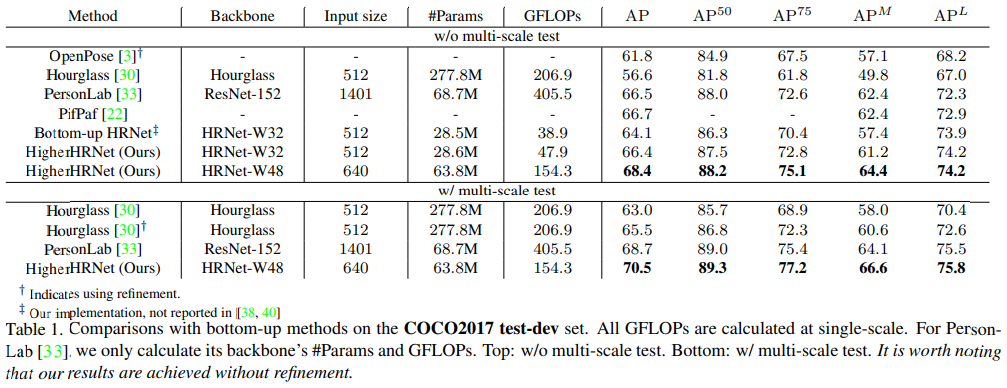
Table 1은 다른 Bottom-Up 기반의 모델들과 성능을 비교한 결과이다. 기존 모델들보다 더 좋은 성능을 보였으며 기존 HRNet보다 파라미터와 GFLOPs가 소폭 상승했지만 2.2가량 AP가 상승한 것을 확인할 수 있다.
GFLOPs가 증가했다는 점은 Bottom-Up 기반 모델의 장점인 속도가 떨어진 것으로 볼 수 있어 아쉬움
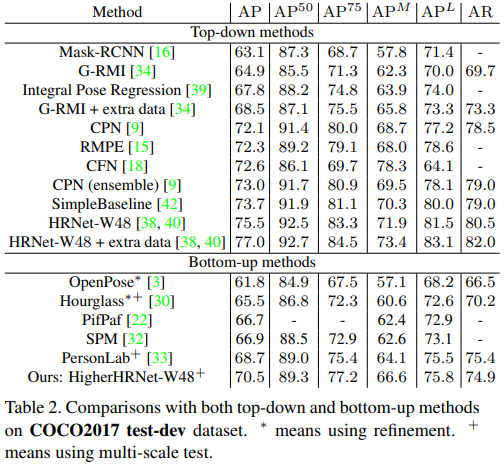
Top-Down 모델의 성능까지 같이 기록한 성능 결과 표
4.2. Ablation Experiments

HRNet -> HigherHRNet으로 갈때에는 Deconvolution 모듈을 하나 추가하였다. $AP^M$은 Medium Person을 의미하며, 해상도가 높아질수록 작은 크기의 사람을 잘 잡는 것을 확인할 수 있다.
이론대로 256 -> 512로 갈때 성능 개선이 많이 이루어지지 않은 점이 아쉽다(전체 성능은 떨어진 점도). 논문에서는 이를 COCO 데이터 셋에 한정된 문제일 수 있다고 보고있다.
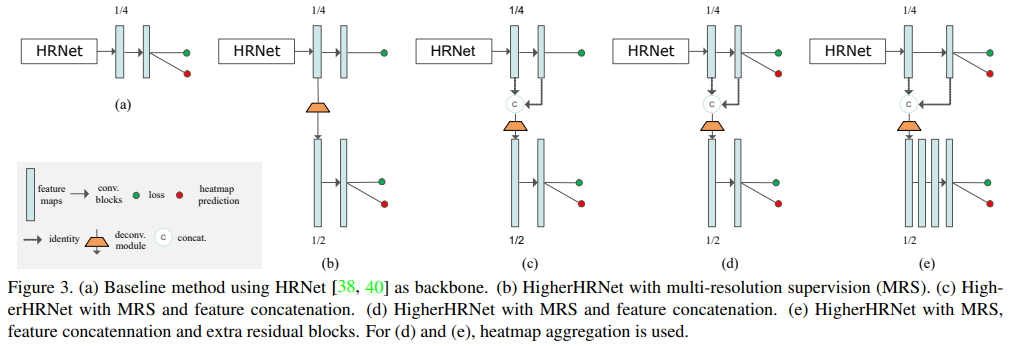

Figure 3에서 볼 수 있듯이 각 개별 요소들을 바꾸어가며 Ablation Study를 진행하였다(결과는 Table 4).
- (a) : HRNet을 Backbone으로 사용한 기본 방법
- (b) : MRS(Multi-Resolution Supervision)을 사용한 Higher HRNet
- (c) : MRS와 Feature Concate를 사용한 방법
- (d) : MRS와 Feature Concate를 사용한 방법(저해상도에서도 Heatmap 예측)
- (e) : MRS와 Feature Concate, 추가 Residual Block을 사용한 방법
결국 모든 방법을 모두 사용한 (e) 방법의 AP 성능이 가장 높았던 것을 확인할 수 있다.
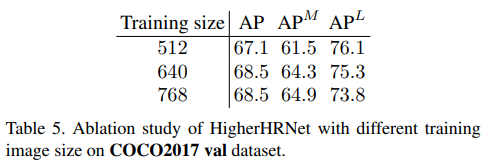
해상도를 높일 수록 작은 사람에 대한 성능은 증가하지만 큰 사람에 대한 성능이 줄어들었으며(아쉬움)
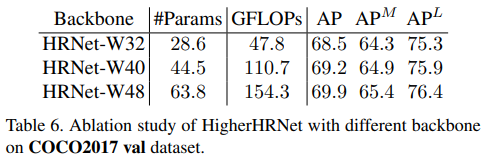
Channel의 수가 많아질 수록(모델이 커질수록) 성능이 더 좋았던 것 또한 확인하였다(당연한 것).
4.3. CrowdPose
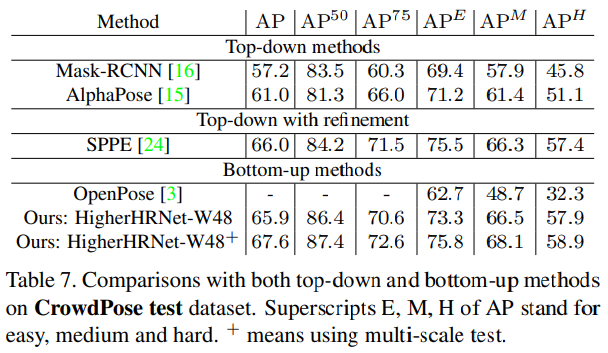
CrowdPose 데이터 셋으로 수행한 실험에서도 마찬가지로 준수한 성능을 보였다.
본 논문에서는 HRNet을 기반으로 한 Bottom-Up 방식의 Pose Estimation 모델인 HigherHRNet을 제안하였다. Bottom-Up 방식의 모델에서 고해상도 정보를 어떻게 네트워크 동안 유지할 것인지에 대한 고민에서 시작한 모델이며 Encoder-Decoder, Dilated Convolution 등 여러가지 방법들 중 HRNet을 선택하여 네트워크를 디자인하였다.
Bottom-Up 방식 모델들 중 가장 좋은 성능을 보였다는 점에 Contribution있으며 다소 계산량이 많아진 것은 아쉽지만 이에 대한 앞으로의 발전 방향을 제시해준 논문이었다고 생각한다. 다만 아쉬운 점은 실험 결과에 있어 이것저것 모듈을 전부 붙인 결과가 제일 좋았다는 점으로 결국 모델이 커질 수록 성능은 좋아지고, 그러려면 속도를 포기해야 하는데 그럼 굳이 Bottom-Up 방식을 사용하는 데에 이점이 존재하는가?라는 의문이 들었다는 점이다.
이에 대한 후속 연구가 있는지 찾아볼 필요가 있을 것 같다.
세 줄 요약
1. Bottom-Up 방식으로 고해상도-저해상도 Representation 정보를 잘 보존한 HigherHRNet 모델을 제안하였다.
2. HRNet 모델을 Backbone으로 두었고 FPN 기반의 Multi-Resolution Supervision 방식을 사용하였다.
3. COCO와 CrowdPose 데이터 셋에서 지금까지의 Bottom-Up 모델 중 가장 좋은 성능을 기록하였다.

'논문 paper 리뷰' 카테고리의 다른 글
| [Paper Review] Unbiased Data Processing for Human Pose Estimation 논문 이해하기 (1) | 2024.09.12 |
|---|---|
| [Paper Review] HRNet for Human Pose Estimation 논문 이해하기 (1) | 2024.09.06 |
| [Paper Review] Simple Baselines 논문 이해하기 (0) | 2024.09.05 |




댓글