『 Simple Baselines for Human Pose Estimation and Tracking. ECCV. 2018. 』
이번 논문은 2018년 ECCV에 Accept된 Simple Baselines 논문이다. 후속 Pose 논문들을 보다 많은 논문들이 이 논문을 Reference하고 있어 관심이 갔다. Tracking보다는 Pose Estimation 자체에 관심이 많아 해당 분야 쪽으로 서술을 진행하도록 하겠다.
Github
https://github.com/Microsoft/human-pose-estimation.pytorch
GitHub - microsoft/human-pose-estimation.pytorch: The project is an official implement of our ECCV2018 paper "Simple Baselines
The project is an official implement of our ECCV2018 paper "Simple Baselines for Human Pose Estimation and Tracking(https://arxiv.org/abs/1804.06208)" - microsoft/human-pose-estimation.p...
github.com
0. Abstract
몇 년간 Pose Estimation 모델이 많이 발전하였지만 그만큼 모델이 복잡해지고 어려워졌다. 이에 본 논문에서는 간단하면서도 효과적인 방법을 제안하려 한다.
1. Introduction
Pose Estimation 문제를 해결하는 딥러닝 모델들이 발전하면서 네트워크 아키텍처와 실험 방법(Experiment Practice)이 복잡해지고 있다. 이 때문에 알고리즘의 분석과 비교가 어려워 성능을 비교하더라도 어떠한 모델 디테일이 중요한지 파악하기가 어렵다.
따라서 본 논문은 간단한 방법으로 얼마나 좋은 성과를 낼 수 있을지에 대한 호기심으로 시작한다. 따라서 모델 구조를 단순하게 가져갔는데, ResNet Backbone에서 시작하여 뒤에 몇 개의 Deconvolution Layer를 추가한 구조로 디자인하였다. 이렇게 단순한 구조만으로 COCO 데이터 셋에서 좋은 성능을 보였다. 본 논문의 연구는 이론적이라기보다는 실험을 통해 간단한 구조로 좋은 성능을 내는 모델을 찾아낸 것에 가깝다고 볼 수 있다.
2. Pose Estimation Using A Deconvolution Head Network

전체 네트워크는 Figure 1의 (c)와 같다. 왼쪽에 보이는 Hourglass나 CPN 모델보다 훨씬 간단한 구조인 것을 확인할 수 있다. 이러한 구조를 사용한 이유는 깊고 낮은 해상도에서 Heatmap을 생성하는 가장 간단한 방법이기 때문이다.
Batch Normalization, ReLU가 적용된 3개의 Deconvolution Layer를 사용하며 각 Layer는 4x4 Kernel을 가진 256개의 Filter를 가지며 Stride는 2이다. 마지막에는 1x1 Convolution Layer가 추가되어 k개의 Keypoint에 대한 k개의 Heatmap을 생성한다. Loss로는 MSE를 사용하며 목표 Heatmap은 Ground Truth Joint에 2D Gaussian을 적용하여 생성한다.
본 논문에서는 Hourglass와 CPN 모델과의 비교를 다수 진행한다(이전 연구들 중에서 가장 성능이 높았던 모델이기 때문인 것 같다). 본 논문에서 제안한 모델은 Hourglass와 CPN 모델과 고해상도 Feature Map을 생성하는 방식에서 차이를 가진다. 두 모델은 모두 Upsampling을 사용하여 Feature Map의 해상도를 증가시키고 다른 Block에서 Convolution을 수행한다. 하지만 본 논문에서 제안한 모델은 Upsampling과 Convolution 파라미터를 Deconvolution Layer에 결합하여 더 간단한 구조를 가지고 Skip-Connection을 사용하지 않는다.
물론 3가지 모델의 공통점도 존재하는데 가장 작은 Feature Map에서부터 3번의 비선형성을 가진 Upsampling을 진행하여 고해상도 Feature Map과 Heatmap을 얻는다는 것이다.
어떤 방식이든 고해상도의 Feature Map을 얻는 것이 중요하다는 것으로 보인다. 추후 HRNet에 해당 내용이 어떻게 녹아들어 있을지 기대가 되는 부분이다.
3. Pose Tracking Based on Optical Flow
Pose Tracking 파트는 내가 논문을 읽으려 하는 목적과 살짝 달라 정리하지 않았다. 추후 읽을 수 있겠지만 우선 지금은 아래 블로그를 참고하자.
Simple Baselines for Human Pose Estimation and Tracking 논문 정리
simple baselines for human pose estimation paper를 읽고 정리한 내용이다.
velog.io
4. Experiments
위와 마찬가지로 Pose Estimation 관련 실험 내용만 정리하도록 하겠다.
Pose Estimation on COCO
실험에 사용한 데이터는 COCO 데이터 셋이다. Metric으로는 OKS를 기반으로 10개의 Threshold에 대한 AP를 활용하였다.
Train : ResNet Backbone은 Classification Task에서 ImageNet 데이터로 사전학습된 가중치를 활용하여 초기화한다. 다른 Implement Detail은 논문 참고.
추후에 등장한 ViTPose에 기존 연구들이 ImageNet으로 사전학습된 모델을 Backbone으로 많이 활용한다는 내용이 기술되어있는데 그게 여기쯔음부터 등장한 내용이겠구나!
Test : 테스트 과정에서는 2단계의 Top-Down 패러다임이 적용된다. Faster RCNN Detector를 사용하며 Hourglass 모델이 그랬던 것처럼 원본 이미지와 뒤집힌 이미지의 평균 Heatmap을 활용하여 Joint 위치를 예측한다. 또한 최종 예측 전에 가장 점수가 높은 Response에서 두번째로 높은 Response 방향으로 1/4 Offset이 적용된다.
1/4 Offset : Heatmap 안에서 특정 포인트 A가 가장 높은 Response를 가지고 B가 두번째로 높은 Response를 가진다면 A에서 B 방향으로 사이 거리의 1/4만큼 이동한다는 의미이다.
Ablation Study

Table 2는 본 논문이 제안하는 모델의 다양한 옵션에 대한 실험 결과이다.
- Deconvolution Layer 개수 실험
- (a) : 3개의 Deconvolution layer, Heatmap Size : 64 x 48
- (b) : 2개의 Deconvolution layer, Heatmap Size 32 x 24
- Deconvolution layer가 3개일 때의 성능이 더 좋음
- Kernel Size 크기 실험
- (a), (c), (d)를 비교하였을 때 Kernel Size가 4일때의 성능이 더 좋음
- Backbone 실험
- (a), (e), (f)를 비교하였을 때 ResNet-152일 때의 성능이 제일 좋음
- Image Size 실험
- (a), (g), (h)를 비교하였을 때 Input Size가 클 수록 성능이 좋음

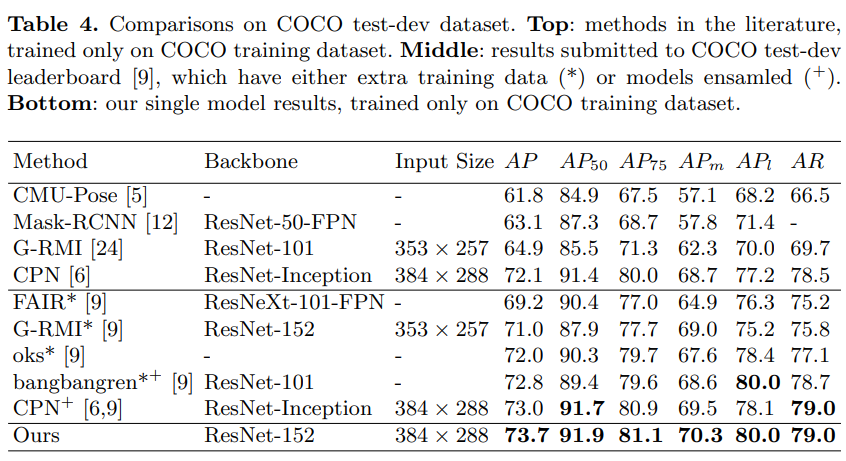
COCO 데이터 셋을 가지고 다른 모델들과 성능을 비교하였을 때 본 논문이 제안하는 모델이 구조도 간단하고 성능도 좋다는 것을 알 수 있다.
이후는 Tracking에 관련된 실험 내용이기에 서술하지 않았다.
이번 논문은 Pose Estimation과 Tracking 분야에서 비교적 간단한 구조를 가지는 모델을 설계하여 지금까지의 SOTA 모델과 견줄 수 있는 모델을 소개한다. 정확한 모델 명칭은 없는 것 같고 그냥 baseline이라고 부르는 것 같다. Tracking쪽은 제하고 Pose Estimation과 관련된 부분만을 집중해서 봤는데 이렇게 보니 내용이 거의 없는 정도로 느껴지는 것 같다. 그만큼 Pose Estimation과 Tracking에 모두 Contribution을 가지고 있는 논문인 것 같다.
아쉬운점
1. 2가지 Task를 한 논문에 모두 녹이려 해서인지 모델 구조에 대한 설명이 자세히 나타나있지 않다는 점이다. 왜 Backbone으로 ResNet을 사용했고, 단순한 구조를 만들면서 파라미터 수가 얼마나 줄어들었는지 등의 소개가 이루어지지 않았다.
2. 간단한 구조를 위해 Skip Connection을 사용하지 않았다는 건 단순히 Detector에 FPN구조를 사용하지 않아서 Decoder와 연결하지 않았다는 것을 말하는 걸까? Backbone으로 ResNet을 사용하였는데 만약 여기서 Skip Connection을 사용했다면 좀 더 이 내용을 디테일하게 서술해주었으면 좋았을텐데..
3. 구조가 단순한데 이전 논문들과의 차이라고 하면 ImageNet 데이터를 Pretrain한 것인 것 같다. 구조가 좋다기보다 많은 데이터를 Pretrain한 것이 중요해 보이는데 Pretrain한 데이터를 바꾸어가며 실험을 진행했다면 더 좋았을 것 같다.
세 줄 요약
1. Pose Estimation과 Tracking Task에서 간단한 구조로 좋은 성능을 내는 Simple Baseline을 제안한다.
2. Baseline 모델은 좋은 Detector(Faster/Mask RCNN) + ImageNet 데이터로 Pretrain + Deconvolution 정도의 단순한 기법으로 설계하였다.
3. 두 분야에서 모두 실험을 통해 SOTA의 성능을 기록하였으며 앞으로의 모델 성능 개선에 기여하였다.

'논문 paper 리뷰' 카테고리의 다른 글
| [Paper Review] HRNet for Human Pose Estimation 논문 이해하기 (1) | 2024.09.06 |
|---|---|
| [Paper Review] CPN 논문 이해하기 (1) | 2024.09.04 |
| [Paper Review] Stacked Hourglass 논문 이해하기 (0) | 2024.09.03 |




댓글