[ 사전 지식 ]
Fully Convolutional Networks (FCN)
: 기존 이미지 분류에서 성능이 좋은 CNN 기반 모델을 Semantic Segmentation Task를 수행할 수 있도록 변형시킨 모델
구조
1. Convolution Layer를 통해 Feature 추출
2. 1x1 Convolution Layer를 이용해 Feature map의 channel 수를 dataset 객체의 개수와 동일하게 변경 ( Heatmap 추출 )
3. 낮은 해상도의 Heatmap을 Upsampling 하여 입력 이미지와 같은 크기의 Map을 생성
4. 최종 피처 맵과 라벨 피처 맵의 차이를 이용하여 Network 학습

하지만 FCN Network에서는 입력 이미지가 convolution 과정을 거치면서 출력되는 Feature map의 크기가 작아지기 때문에 Feature map의 한 픽셀은 입력 이미지의 위치 정보를 대략적으로만 가지게 된다. 따라서 이를 Upsampling하더라도 기존 입력 이미지와 비교했을 때 디테일하지 못하다는 단점을 가진다.

이를 극복하기 위해 사용한 방법이 Skip Connection으로 Pooling과정을 거치기 전 layer를 skip layer로 연결하여 Upsample의 배율을 줄여보자는 아이디어이다.
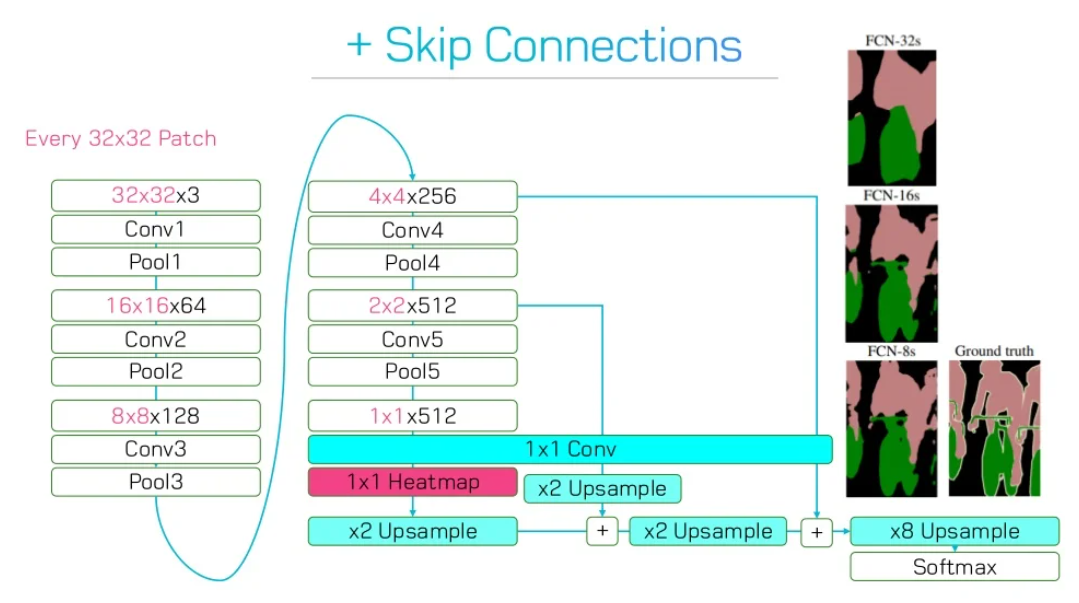
Upsample의 배율을 줄이고 Skip Connection을 사용할 경우 Ground Truth와 비교했을 때 더 비슷한 결과를 출력하는 것을 확인할 수 있다.
< 참고자료 >
https://www.youtube.com/watch?v=JiC78rUF4iI
1) FCN
FCN은 이미지 분류에서 우수한 성능을 보인 CNN 기반 모델(AlexNet, VGG16, GoogLeNet)을 Semantic Segmentation Task를 수행할 ...
wikidocs.net
『 DeepLAB : SEMANTIC IMAGE SEGMENTATION WITH DEEP CONVOLUTIONAL NETS AND FULLY CONNECTED CRFS. 2015. 』
0. Abstract
- 최근 vision task(image classification, object detection)에서 좋은 성능을 보여주는 DCNN(Deep Convolutional Neural Networks).
- DCNN은 invariance하다는 특징 때문에 최종 layer에서의 response가 object segmentation에서 충분히 localized되지 않는다는 문제가 있다. 이를 극복하기 위해 본 논문의 저자는 최종 layer의 response와 fully connected Conditional Random Field(CRF)를 결합하였다. 이러한 'DeepLab' 시스템은 segment boundary를 localize하는 데 있어 기존 방법의 정확도를 넘어섰다.
- PASCAL VOC-2012 semantic image segmentation task에서 SOTA를 기록하였고 test set에서는 71.6%의 IOU 정확도에 도달하였다.
1. Introduction
- DCNN은 Image classification, object detection등을 포함한 computer vision system의 성능을 크게 향상시켰고, end-to-end 방식으로 train되어 SIFT나 HOG 방식 같이 설계된 표현에 의존하는 시스템보다 더 좋은 결과를 보였다. DCNN에 내재된 invariance 특성이 local image 변환에서 좋은 성능을 보일 수 있는 요인이다. 하지만, 이러한 invariance는 high-level의 vision task에는 바람직하지만 공간적인 detail을 추상화하기 보다 정확한 localization을 원하는 pose estimation에서는 방해가 될 수 있다.
- Image labeling task에서 DCNN의 문제점은 signal downsampling과 spatial insensitivity(invariance)이다. 첫번째 문제는 DCNN의 모든 layer에서 max pooling과 down sampling(stride)이 반복적으로 일어나 signal resolution이 감소한다는 것으로, 본 논문에서는 atrous 알고리즘을 사용하여 discrete wavelet 변환을 효율적으로 계산하는 것으로 해결하였다.
atrous 알고리즘 ( atrous convolution )
: DCNN의 마지막 max pooling layer들에 filter upsampling을 진행해 non-zero filter에 구멍을 넣는 방식
- parameter의 개수나 연산량을 증가시키지 않더라도 field의 view를 늘릴 수 있다
- 일반적인 classification은 대상의 detail한 정보 필요 X, but semantic segmentation은 픽셀단위의 dense prediction 필요하기 때문에 그대로 classification network를 사용할 경우 feature map의 크기가 줄어들어 detail한 정보를 얻기 어렵다. 때문에 pooling layer를 없애고 atrous convolution으로 receptive field를 확장하였다
https://better-tomorrow.tistory.com/entry/Atrous-Convolution
Atrous Convolution
Atrous Convolution 1. 일반적인 convolution 2. Atrous convolution(dilated convolution) 위 두 이미지를 한 번 살펴보자 일반적인 convolution과 달리 atrous convolution의 경우 kernel 사이가 한 칸씩 띄워..
better-tomorrow.tistory.com
- 두번째 문제는 classifier에서 객체 중심의 결정을 얻으려면 공간 변환(spatial transformation)에 대한 invariance가 필요한데 이것이 DCNN의 공간 정확도(spatial accuracy)를 제한한다는 것이다. 이를 해결하기 위해 본 논문에서는 fully connected Conditional Random Field(CRF)를 사용하였다. CRF는 semantic segmentation에서 광범위하게 사용되며 class score와 낮은 수준의 정보나 superpixel(의미있는 픽셀들을 모아서 그룹화해준 것)을 결합해준다. DeepLAB에서 사용한 fully connected pairwise CRF는 모델의 효율적인 계산과 세부적인 디테일 파악을 가능케 했다. 또한 이를 DCNN 기반의 pixel-level classifier와 함께 사용했을 때 분류기의 성능이 SOTA를 기록하는 것을 확인할 수 있다.
- DeepLAB의 3가지 장점은 다음과 같다.
1. 속도(speed) : atrous 알고리즘을 사용하여 빠른 Mean Field Inference가 가능하다.
2. 정확도(accuracy) : PASCAL semantic segmentation challenge에서 SOTA를 기록했다.
3. 단순성(simplicity) : DCNN과 CRF 2개의 잘 정립된 모듈의 캐스케이드로 구성되어있다.
2. Related Work
- DCNN 기능의 연구, CRF 알고리즘 등에 관한 연구 현황 기재
3. Convolutional Neural Networks For Dense Image Labeling
3.1. Efficient Dense Sliding Window Feature Extraction With The Hole Algorithm
VGG-16 구조를 이용( V2에서는 ResNet구조를 사용 )
1. Fully Connected Layer -> Convolution Layer로 변환
2. 마지막 Max pooling layer 2개 제거
3. hole 알고리즘(atrous 알고리즘) 적용
4. Input stride를 2 pixel, 4 pixel로 사용 -> Feature map을 sparse하게 sampling ( Caffe Framework에서 구현 )

테스트 과정에서는 원본 이미지 해상도의 class score map이 필요하기 때문에 bilinear interpolation을 사용하여 resolution을 8배 증가 시켜 사용하였다.
3.2. Controlling The Receptive Field Size And Accelerating Dense Computation With Convolutional Nets
- ImageNet task에 대해 pre-trained된 network는 일반적으로 큰 receptive field 크기를 갖는다. 하지만 본 논문에서 다루는 VGG-16의 경우 receptive field가 224x224로 fully convolutional하게 변환할 경우 첫번째 fc layer는 7x7 크기의 4096개 필터를 가져 계산 병목 현상의 원인이 된다.
- 본 논문에서는 첫번째 fc layer를 4x4(or 3x3) 크기로 subsampling하여 이 문제를 해결하였다. 이는 receptive field의 크기를 128x128(zero-padding 포함), 308x308(convolution 시)으로 줄였으며 계산 시간을 2 ~ 3배 단축하였다.
4. Detailed Boundary Recovery : Fully-Connected Conditional Random Fields And Multi-Scale Prediction
4.1. Deep Convolutional Networks And The Localization Challenge
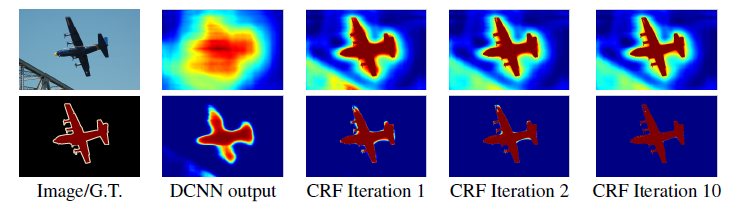
위 그림에서 볼 수 있듯이 DCNN map은 이미지에서 개체의 존재와 대략적인 위치를 예측할 수 있지만 정확한 윤곽을 가리키지는 못한다. 이 논문이 나온 시기에는 이러한 Localize 문제를 해결하기 위한 2가지 접근 방식이 존재하였는데, 우선 첫째는 객체 boundary를 더 잘 추정하기 위해 Convolution Network의 여러 계층에서 정보를 활용하는 것이다. 둘째는 Superpixel을 사용하는 것으로 본 논문에서는 DCNN과 fully connected CRF를 결합하여 이러한 Localize 문제를 해결하고 정확한 semantic segmentation 결과를 얻는데 성공하였다.
4.2. Fully-Connected Conditional Random Fields For Accurate Localization
- 본래 CRF는 noisy한 segmentation map을 부드럽게 만드는데 사용되었다. CRF에는 인접 노드를 연결하는 energy term이 존재하여 공간적으로 근접한 픽셀에 동일한 label을 할당하는 것을 선호하기 때문이다.
- short-range CRF는 약한 분류기의 spurious한 prediction을 정리하는데 사용되지만, 그림 2와 같이 Score map은 일반적으로 매끄러운 결과를 생성하기 때문에 이곳에 short-range CRF를 사용하는 것은 문제가 생길 수 있다. 본 논문 저자의 목표는 매끄럽게 만드는 것이 아닌 상세한 local 구조를 복구하는 것으로, local-range CRF와 contrast-sensitive potential을 같이 사용하면 localization을 개선할 수 있지만 여전히 얇은 구조를 놓지고 비싼 이산 최적화 문제(discrete optimization problem)을 해결해야한다는 문제가 생긴다.
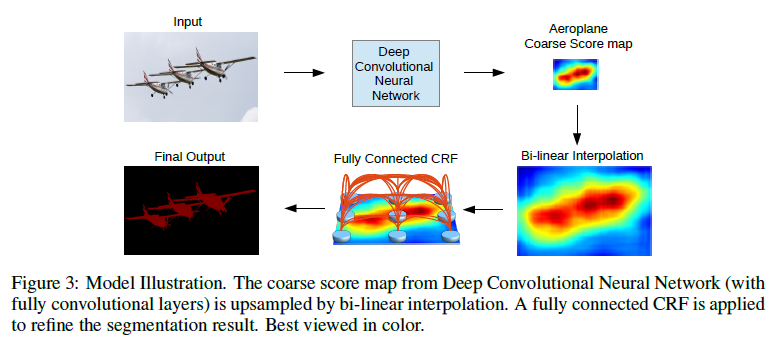
- 따라서 본 논문에서는 이러한 short-range CRF의 한계를 극복하기 위해 fully-connected CRF 모델을 시스템에 결합하였다.

Energy Function ( Minimize하는 것이 목적 -> Posterior를 Maximaize 하기 위해 )
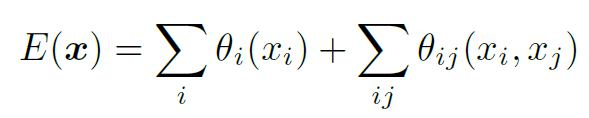
x : 해당 pixel의 label
i, j : 픽셀의 위치
Unary Term : DCNN을 통해 계산된 픽셀 i에서의 label 할당 확률
Pairwise Term : 픽셀간의 거리가 얼마이든 픽셀 i와 j쌍에 대한 pairwise term이 존재 ( fully-connected )
4.3. Multi-Scale Prediction
- bounary localization accuracy를 높이기 위해 multi-scale prediction을 사용하였다.
- Input image와 처음 4개의 max pooling layer의 output에 2-layer MLP(1st : 128 3x3 convolutional filter, 2nd : 128 1x1 convolutional filter)를 추가하였고 그 결과 softmax 계층에 입력되는 feature map은 5 x 128 = 640 channel로 향상된다.
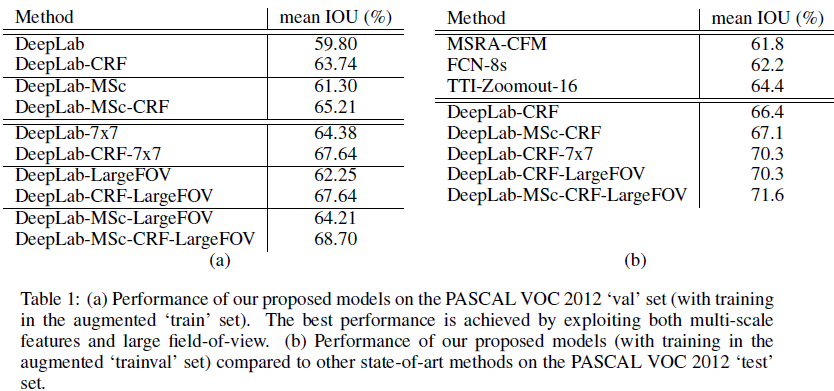
세 줄 요약
1. Semantic segmentation task에서 DCNN의 invariance한 특징을 극복하기 위해 CRF를 결합한 DeepLab 모델 제안
2. Hole 알고리즘을 적용하고 Multi-Scale 기법을 사용하여 더 높은 Accuracy를 얻음
3. 기반이 되는 모델 변경, SPP기법, Batch Normalization 등의 사용으로 버전업된 V2, V3가 존재

< 참고 자료 >
https://doubleyoo.tistory.com/3
[논문 리뷰] DeepLab V1 - SEMANTIC IMAGE SEGMENTATION WITH DEEP CONVOLUTIONAL NETS AND FULLY CONNECTED CRFs
논문 - SEMANTIC IMAGE SEGMENTATION WITH DEEP CONVOLUTIONAL NETS AND FULLY CONNECTED CRFs, Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, Alan L. Yuille (arxiv.org/abs/1412..
doubleyoo.tistory.com
https://noru-jumping-in-the-mountains.tistory.com/15
[논문 리뷰]DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRF
1. Introduction Deep Convolutional Neural Networks(DCNNs) image classification, object detection 등의 전반적인 CV 분야에서 좋은 performance를 보여주는 데에 많은 영향을 끼쳤다. DCNN은 end-to-end 및 b..
noru-jumping-in-the-mountains.tistory.com
'논문 paper 리뷰' 카테고리의 다른 글
| [X:AI] Selective Search란? (1) | 2023.03.12 |
|---|---|
| [X:AI] ASR(Automatic Speech Recognition) 이해하기 (0) | 2022.08.17 |
| [X:AI] EfficientNet 논문 이해하기 (0) | 2022.07.25 |




댓글