< 참고자료 >
https://www.youtube.com/playlist?list=PL9mhQYIlKEhdrYpsGk8X4qj3tQUuaDhrl
토크ON 75차. 딥러닝 기반 음성인식 기초 | T아카데미
www.youtube.com
https://plastic-distance-9d4.notion.site/cba5b3cdbb3e418f9a90346ec1540514
디지털신호처리 이해 (발표용)
0. Audio Task
plastic-distance-9d4.notion.site
[2주차] 딥러닝 기반 음성인식 기초
Audio Autio Tagging (음향 이벤트 인식)은 오디오 신호에서 발생하는 이벤트 종류를 찾는 문제이다. 아기의 웃음이나 기타의 소리가 동시에 있는 소리는 독특해서 즉시 인식됩니다. 하지만 전기 톱
velog.io
# DSP (Digital Signal Processing) 복습
소리는 진동으로 인한 공기의 압축으로, 압축이 얼마나 됐는지는 파동(Wave)으로 나타난다. 파동은 진동하며 공간/매질을 전파해 나가는 현상으로 질량의 이동은 없지만 에너지나 운동량의 운반은 존재한다.
소리의 운동량(물리량)
진폭(Amplitude), 주파수(Frequency), 위상(Phase)
물리 음향 : Intensity(소리 진폭의 세기), Frequency(소리 떨림의 빠르기), Tone-Color(소리 파동의 모양)
심리 음향(사람의 귀) : Loudness(소리 크기), Pitch(음정, 소리의 높낮이나 진동수), Timbre(음색, 소리감각)
Complex Wave(복합파) : 우리가 사용하는 대부분의 소리로 복수의 서로 다른 정현파들의 합으로 이루어짐
Input으로 들어오는 audio file은 대부분 amplitude만 기록됨
-> Frequency 영역을 얻기 위해 퓨리에변환(Fourier transform)을 사용
-> 주파수의 강도, 위상을 얻게됨 (Spectrum magnitude, phase spectrum)
* 퓨리에 변환 : 임의의 입력 신호를 다양한 주파수를 갖는 주기함수들의 합으로 분해하여 표현하는 것
일반적으로 Input audio를 받을경우
-> Frame 단위로 쪼개서 STFT(Short Time Fourier Transform)을 진행
-> 나오는 matrix를 인간의 가청영역에 맞도록 spectogram으로 변환하여 사용
# ASR ( Automatic Speech Recognition )
0. Audio Task & Deep Learning Review
Sound
: Speech Classification, Auto-tagging
Speech
: Speech Recognition(음성인식, STT), Speech Synthesis(음성합성, TTS), Speech Style Transfer(음성변환, STS)
딥러닝은 레고를 조립하는 것과 비슷하다!
레고 박스 : Platform ( AWS, Colab ... )
설명서(조립방법) : Frameworks ( Tensorflow, Pytorch... )
레고 : Dataset

CNN을 Audio에 적용하는 과정
- width, height, channel을 모두 커버할 수 있어서 좋다. ( Audio에는 channel이 존재하지 않음, Frequency, Time을 Input으로 사용 )
- 1-D CNN 사용시 Frequency 고정하고 Time에 따라 진행한다. 이 때 다양한 feature를 뽑고 싶다면 filter map 여러개를 concat하여 Time에 specific한 feature를 뽑아낸다.
- 2-D CNN 사용시 Frequency와 Time에 따라 진행한다. Frequency와 Time 두가지 영역에서 pattern을 찾고, 큰 dataset에 있어 1-D CNN보다 더 높은 성능을 보인다.
- Sample CNN : raw audio를 사용하는 것이 아니라 ( sampling rate가 높으면 data가 커져 연산과정이 많아지기 때문 ) padding 간격을 두며 효율적으로 convolution을 진행하는 것. phase를 날리지 않고 representation에 반영한다. ( ex. 음색 )
이외에도 MLP, RNN, LSTM, GRU, Attention을 사용한다.
1. Audio Auto Tagging & Speech Recognition
Audio Auto Tagging
- 오디오 데이터에 자동으로 태그를 지정하는 알고리즘
- 유사한 소리가 동시에 포함되어 있는 경우 모든 소리를 인식하기 어렵기 때문에 해당 오디오가 포함하는 여러 이벤트를 모두 찾을 수 있도록 Auto Tagging이 필요하다.
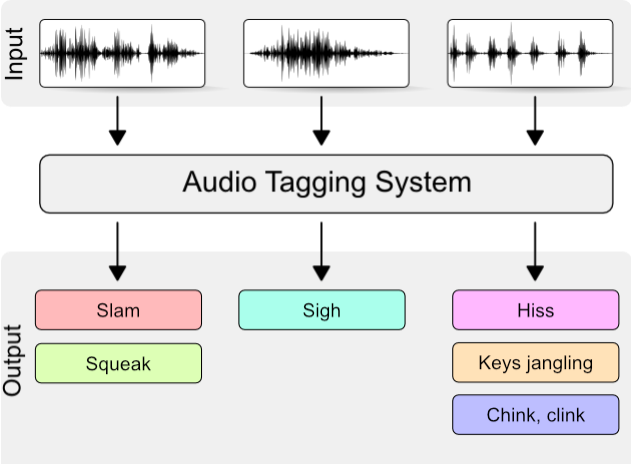
Audio Auto Tagging 평가
- Average Precision, Rank-Average Precision과 같이 Information Retrieval에서 많이 사용하는 metric을 사용
- 이 작업은 Audio의 Label을 예측하는 것으로 LRAP(Label-Weighted-Label-Ranking-Average-Precision)에서는 Label이 1인 값에 대해서만 Rank Precision을 계산한다.
https://stackoverflow.com/questions/55881642/how-to-interpret-label-ranking-average-precision-score
How to interpret: Label Ranking Average Precision Score
I am new to Array programming and found it difficult to interpret the sklearn.metrics label_ranking_average_precision_score function. Need your help to understand the way it is calculated and any
stackoverflow.com
Audio Auto Tagging 과정
Audio Representations -> Feature Extraction -> Classifier
- CNN, RNN, LSTM 등의 모델을 사용해 Feature Extraction을 진행한 후 Feature Space에서 Classifier를 학습한다. 이 때 추출된 Feature는 입력된 Input값이 잘 구분될 수록 좋은 Feature로 인식한다.

Deep Learning Block in Audio
- 베이스나 개 짖는 소리는 음색적인 특징이 다를 것!
- 리듬을 가지는 드럼의 경우 spectogram에서 절벽 형태가 보일 것 -> 1-D CNN에서 잘 보일 것이다!!
- Audio도 시계열이다보니 RNN계열의 모델을 이용해 Time적인 특징을 확인해볼 수도 있다.
2. CTC Loss ( Connectionist Temporal Classification )
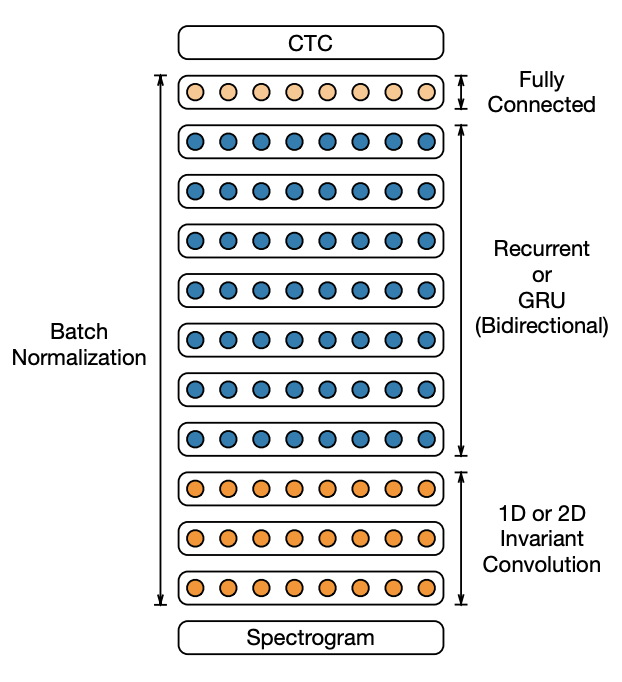
Why we use CTC?
일반적인 Speech Recognition에서는 Audio와 Transcript를 받는데 이 때 어떤 단어의 Character가 Audio와 Alignment에 맞는지 알 수 없다. 또한 사람들의 언어 사용은 각자 다르기 때문에 단일한 규칙으로 이를 정의하기 쉽지 않다.

CTC : 주어진 input과 output 사이의 가능한 모든 alignment의 가능성을 합산하여 작용한다.
( 논문 : CTC works by summing over the probability of all possible alignments between the two )
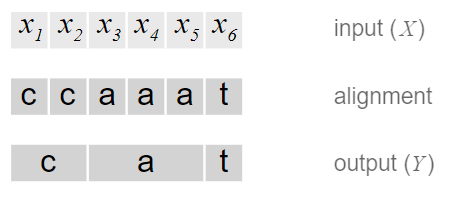
하지만 위 방법에는 2가지 문제가 존재
1. 모든 x에 y가 할당된다는 점 ( utterance에는 띄어쓰기, silence가 존재할 수 있기 때문에 말이 되지 않음 )
2. 여러 character가 연속해서 같은 output을 만들게 하기 어렵다. ( ex. [h,h,h,e,l,l,l,o] -> "helo" )
-> 이 문제를 해결하기 위해 $\epsilon$이라는 토큰을 추가
-> 가능한 모든 alignment를 고려하고 이 때 하나의 input에서 다음 input으로 진행할 때 output을 동일하게 유지하거나 다음 output으로 할당된다. ( Many to one )
-> $\epsilon$의 존재로 ll처럼 같은 문자가 2개 있을 때 이를 2개의 output으로 구분지어준다.

CTC Loss Function
CTC는 조건부 확률 분포로 ( X, Y )의 Pair dataset에 대해서 각각의 X의 input step을 따라가며 step-by-step으로 single alignment의 확률을 계산한다.

CTC에서는 Label과 Label 사이의 transition(전이)을 아래 3가지로 한정한다.
1. self-loop : 자기 자신을 반복
2. left-to-right : non-blank label을 순방향으로 하나씩 전이 ( 역방향 허용 x, 2개 이상 건너 뛰는 것 x )
3. blank : blank to non-blank, non-blank to blank의 전이
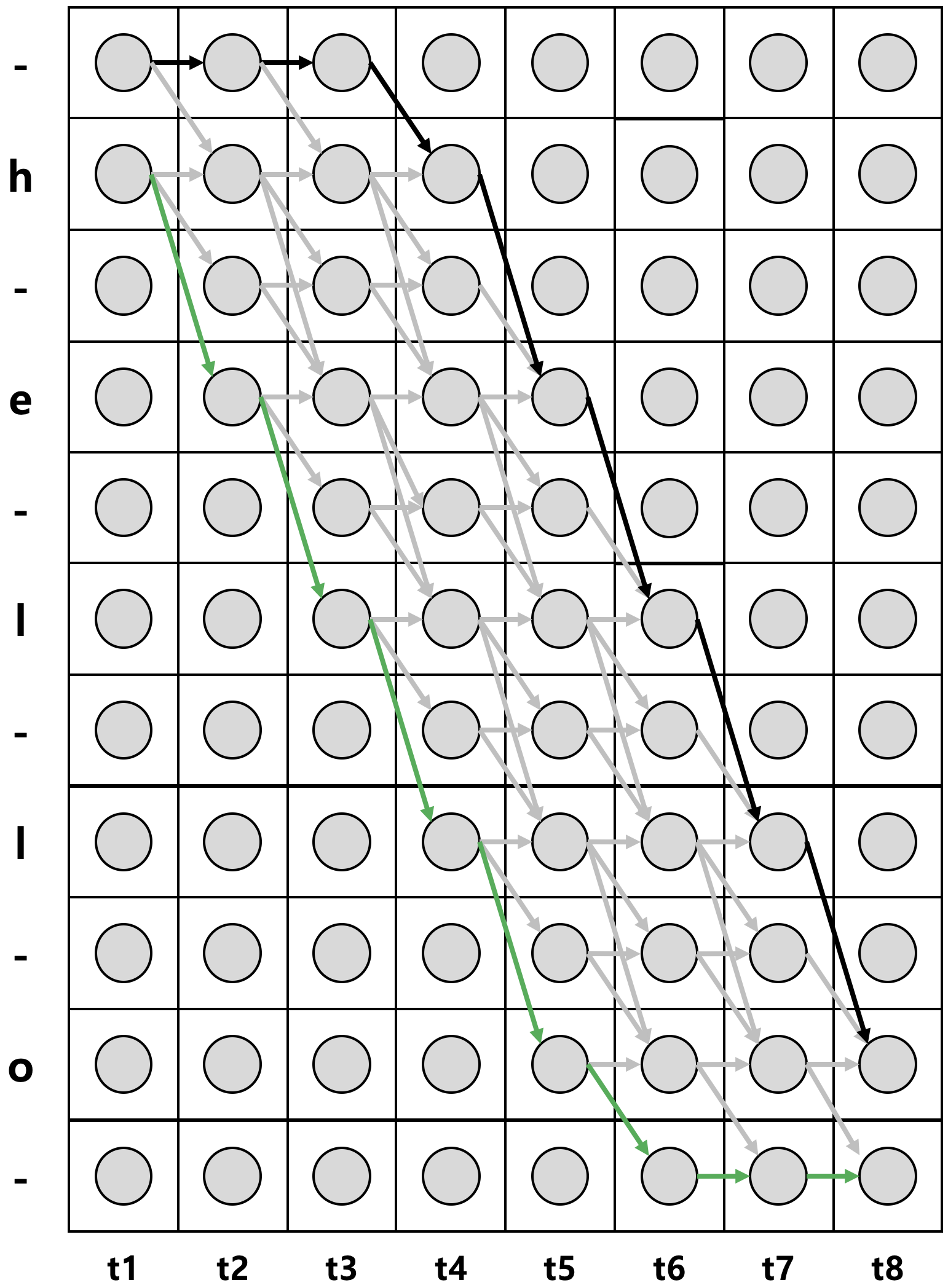
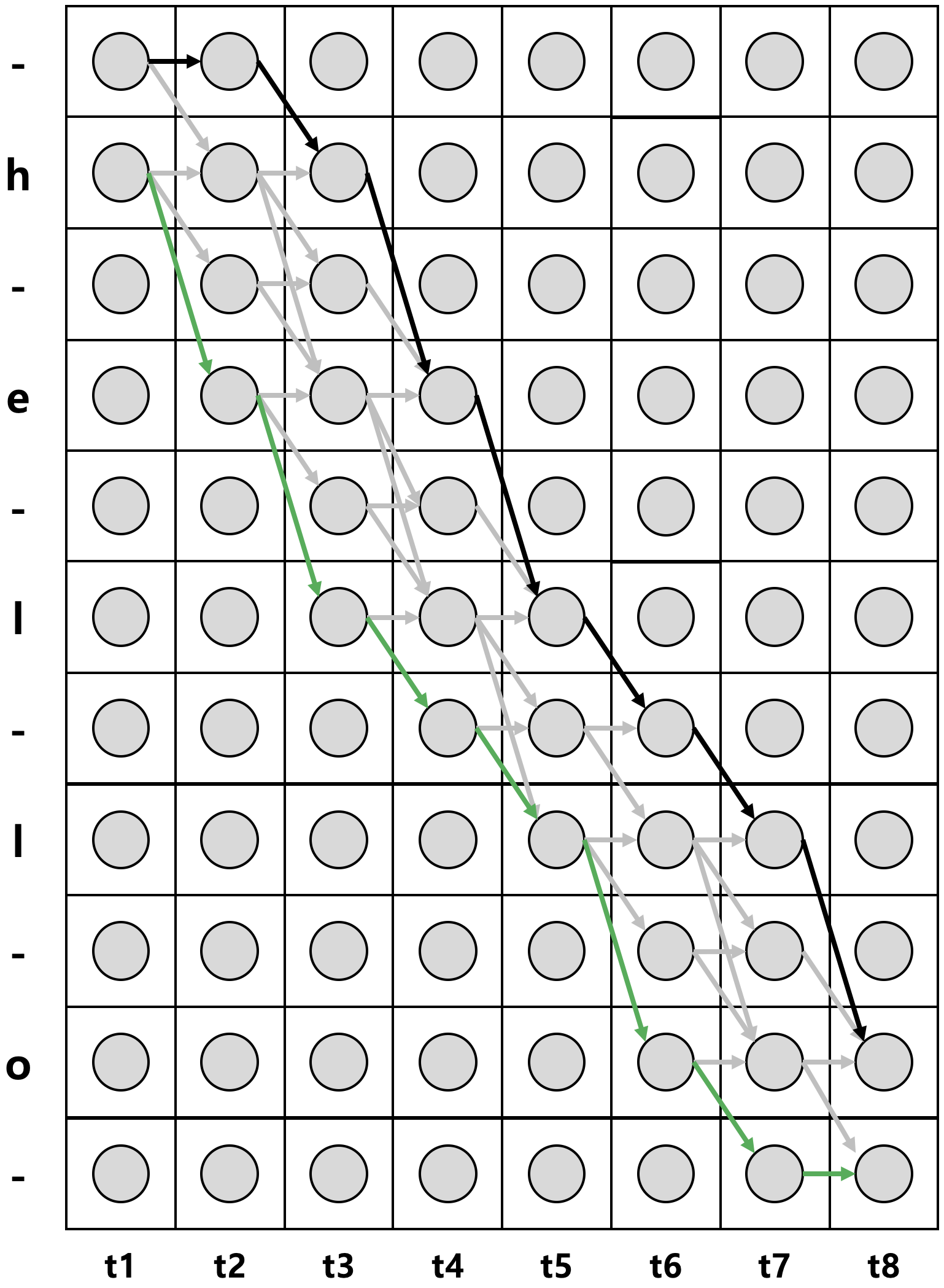
- 위 그림에서 가로축은 시간(time), 세로축은 상태(state)를 의미
- 각 세로 열은 각 시점에 해당하는 확률 벡터로 동그라미는 개별 확률 값을 의미 ( ex. 2번째 행 2번째 열의 동그라미는 t=2 시점에 상태가 h일 확률을 의미 )
- CTC 기법에서는 각 상태가 조건부 독립(conditional independence)라고 가정하기 때문에 특정 시점 t의 output은 이전/이후 상태에 영향을 받지 않는다.
- 특정 Path의 Probability : $p(\pi|x) = \prod_{t=1}^{T}y^t_{\pi_t}$
$\pi$ : 상정 가능한 모든 경로
- 전체 Path의 Probability : $p( \mathbf{l} | \mathbf{x} )=\sum _{ \pi \in { \cal{B} }^{ -1 } \left( \mathbf{l} \right) }{ p\left( \pi | \mathbf{x} \right) }$
$\mathcal{B}$ : blank와 중복된 label을 제거하는 함수 ( ex. $\mathcal{B(hheelloo)}$ = $\mathcal{B(hello)}$ )
$\mathcal{B}^{-1}(\mathbf{l})$ : 위 그림에서 회색 화살표 위를 지나는 모든 경로
위 수식에서 볼 수 있듯이 $p(\mathbf{l}|\mathbf{x})$를 구하려면 상정 가능한 모든 경로의 시점과 확률을 계산해야하기 때문에 시퀀스 길이가 길어지거나 state의 개수가 많아지면 계산량이 폭증하게 된다.
-> CTC에서는 이를 방지하기 위해 Hidden Markov Model의 Forward/Backward 알고리즘을 사용
Dynamic Programming ( 하나의 문제를 단 한번만 풀도록 )
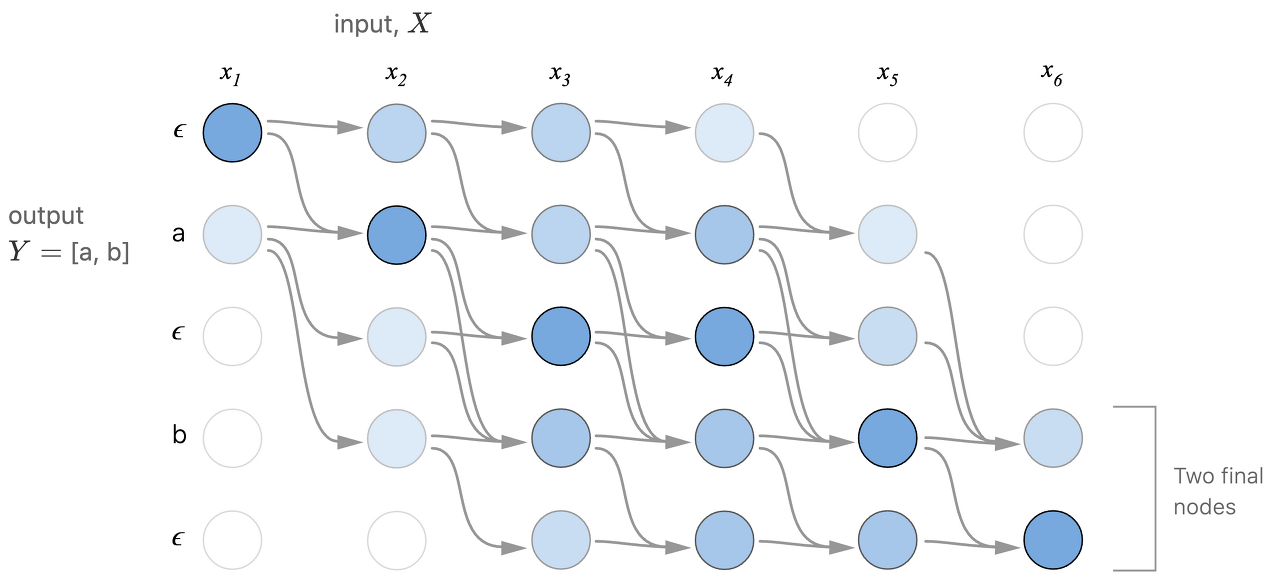
- [a,b]가 output일 때 data의 distribution상 $x_4$번일 때는 그래도 a가 등장해야 한다. (마지막에 ab으로 끝낼 수 있겠지만 이는 outlier )
- 밑에서 위로는 다시 갈 수 없다.
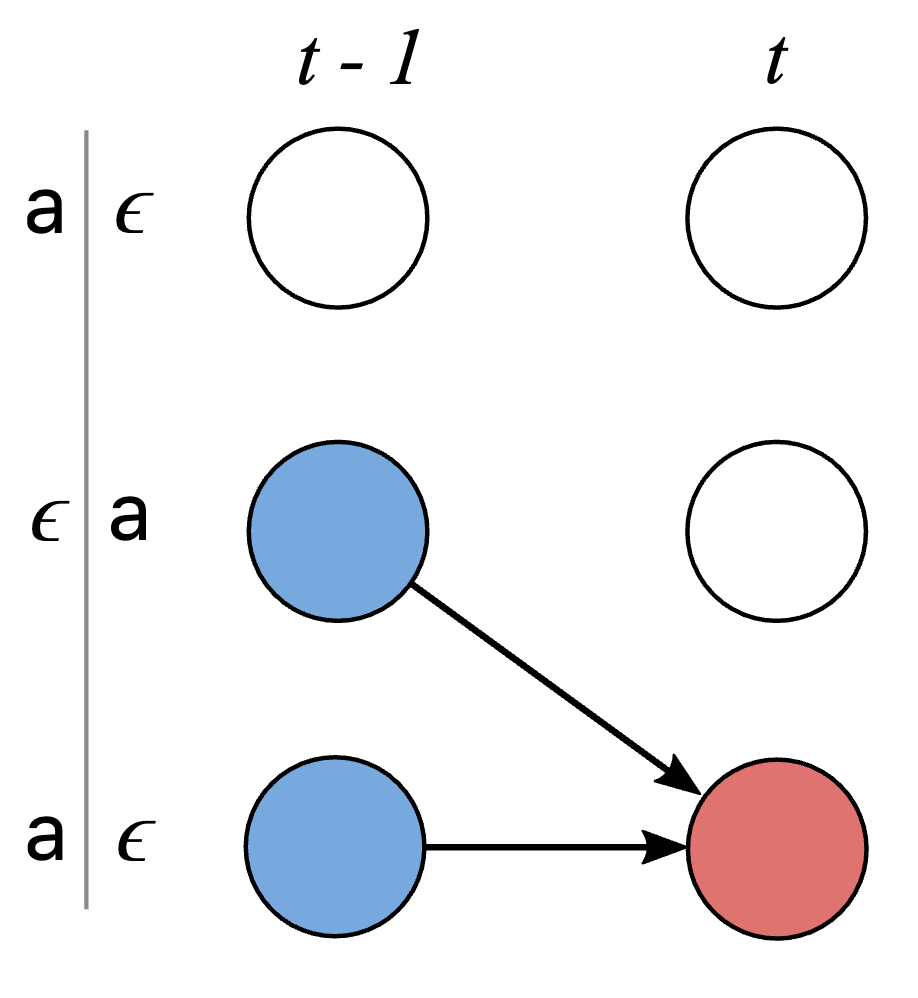
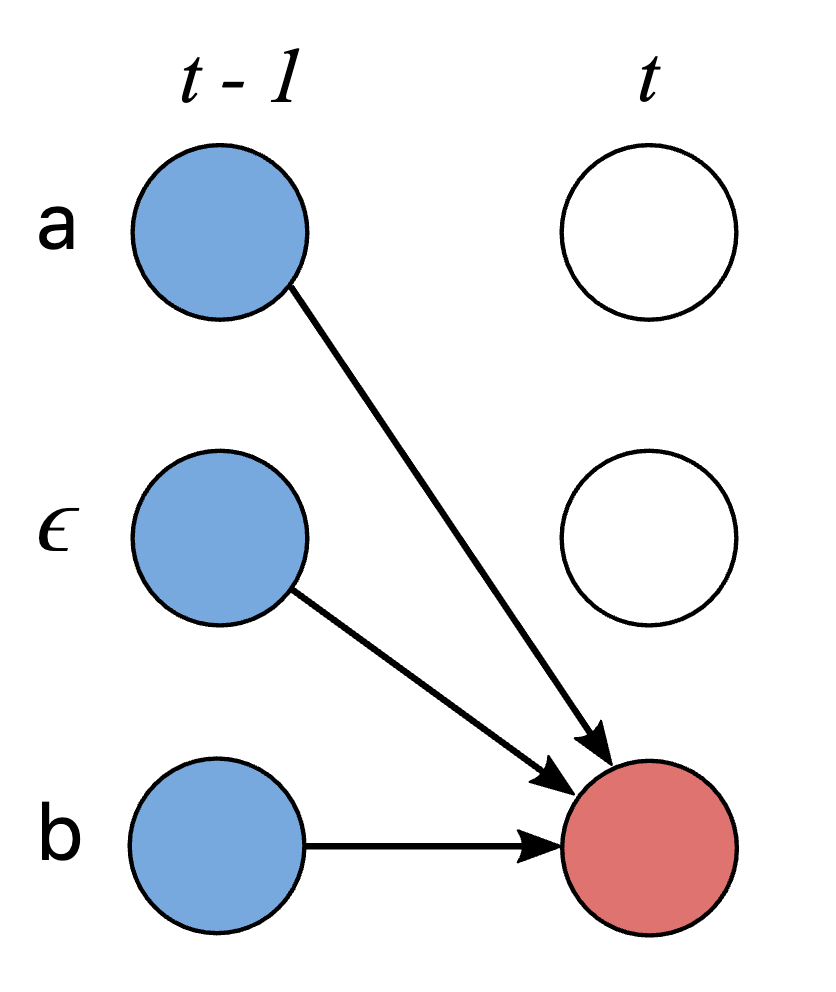
CTC Model 정리
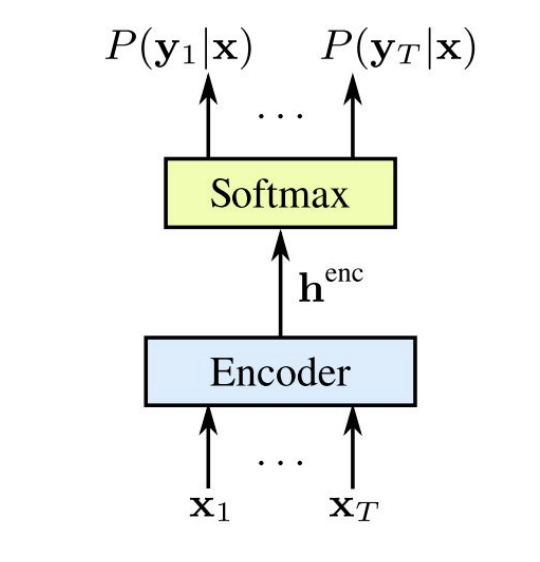
1. CNN을 쌓고, RNN을 쌓은 뒤 Encoding이 잘 된 결과를 FC layer에 통과, softmax 함수 적용
2. 그 결과 각 Time Sequence마다 Probability distribution을 얻음
3. 이를 CTC를 적용하여 relevant한 Path를 찾을 수 있다.
< 참고자료 >
Sequence Modeling with CTC
A visual guide to Connectionist Temporal Classification, an algorithm used to train deep neural networks in speech recognition, handwriting recognition and other sequence problems.
distill.pub
https://ratsgo.github.io/speechbook/docs/neuralam/ctc#motivation
Connectionist Temporal Classification
articles about speech recognition
ratsgo.github.io
https://ratsgo.github.io/speechbook/docs/am/hmm
Hidden Markov Model
articles about speech recognition
ratsgo.github.io
3. CTC vs LAS vs Online Model
LAS ( Listen & Attend & Spell ) : Google Brain에서 제안, input X와 이전 sequence를 auto-regressive방식으로 받고 그 다음 Y를 예측 ( Attention을 사용 )
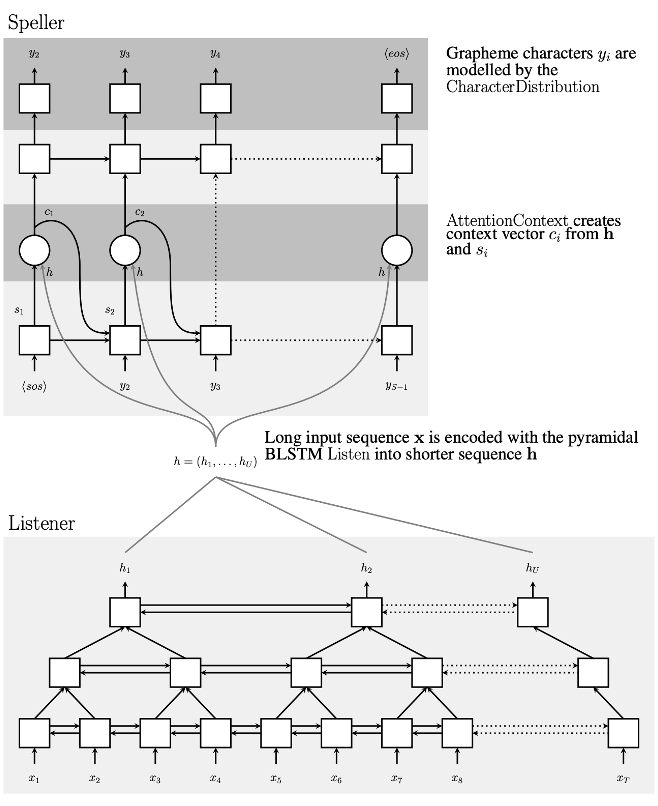
Listener : 3개의 피라미드 형식으로 구성된 bidirectional LSTM(BLSTM) Encoder로 입력 시퀀스 x에서 특징을 추출, 피라미드 형식으로 사용하는 이유는 BLSTM 피라미드 1개당 연산속도를 2배로 줄여주기 때문
Speller : attention-based 디코더 중 h와 s로부터 context vector c를 생성, 이를 기반으로 Grapheme character y를 추출
Online Models
: CTC와 LAS는 전체 sentence를 입력으로 넣고 처리하기 때문에 streaming에 적합하지 않아 이를 보완하기 위한 Online 모델 등장
ex. RNN-Transducer, NT, MoChA
< 참고자료 >
https://arxiv.org/pdf/1508.01211.pdf
https://jybaek.tistory.com/793
Towards end-to-end speech recognition
본 게시물에서 사용된 대부분의 이미지는 아래 링크로부터 첨부되었으며 해당 자료를 통해 많은 영감을 얻었습니다. http://iscslp2018.org/images/T4_Towards%20end-to-end%20speech%20recognition.pdf 하루가 멀..
jybaek.tistory.com
세 줄 요약
1. ASR 성능 향상을 위해 적절한 metric을 사용한 Audio Auto Tagging으로 Feature를 추출해야한다.
2. ASR의 대표적인 CTC 모델은 BRNN(BLSTM)을 여러층 쌓고 Encoder로 들어오는 데이터를 softmax에 통과시키는 방식이다.
3. CTC 알고리즘 외에도 ASR의 대표주자인 LAS 모델이 있다.

'논문 paper 리뷰' 카테고리의 다른 글
| [X:AI] DeepLAB V1 논문 이해하기 (0) | 2022.08.29 |
|---|---|
| [X:AI] EfficientNet 논문 이해하기 (0) | 2022.07.25 |
| [X:AI] YOLO 논문 이해하기 (0) | 2022.07.19 |




댓글