『 EfficientNet : Rethinking Model Scaling for Convolutional Neural Networks. 2019. 』
0. Abstract
- Convolution Neural Network에서는 일반적으로 더 많은 자원을 사용할 수 있을 때, 더 좋은 정확도를 위해 스케일을 키운다.
- 본 연구에서는 주로 Network의 깊이(Depth), 폭(Width), 해상도(Resolution)가 균형을 이룰 때 더 좋은 성능을 보인다는 것을 알아냈고, 따라서 이 3가지에 대한 관찰을 바탕으로 본 논문은 단순하지만 효과적으로 depth, width, resolution의 모든 차원을 균일하게 scaling하는 새로운 방법을 제안한다.
- Neural architecture 검색을 사용하여 새로운 baseline network를 설계하고, scale up하여 이전 ConvNet보다 더 높은 정확성과 효율성을 보이는 EfficientNet Model을 만들었다.
1. Introduction
- ConvNet의 scale up은 정확도를 높이기 위해 널리 사용된다. 예를들어 ResNet에서는 더 많은 계층을 사용하여 ResNet-18에서 확장한 ResNet-200이 있고, 최근에는 baseline model을 4배 scale up 하여 ImageNet top-1 accuracy를 달성한 GPipe 모델도 존재한다.
- 하지만 ConvNet을 scale up하는 과정은 잘 이해되지 않고, 현재 scale up을 하는 많은 방법들이 존재한다. 그 중 가장 일반적인 방법은 ConvNet의 depth나 width로 scale up하는 것이다. 이전의 연구에서는 일반적으로 3가지 차원(depth, width, resolution) 중 하나만을 scaling 하였는데, 2차원 또는 3차원을 임의로 scale up할 경우 많은 수동 조정이 필요하며 여전히 정확성과 효율성이 떨어지는 경우가 많기 때문이다.
- 본 논문에서는 ConvNet을 scale up하는 방법을 다시 생각해보았다 : 더 좋은 정확도와 효율성을 얻기 위해 ConvNet을 scale up하는 원초적인 방법이 무엇일까?
- 경험적 연구를 진행해본 결과 network에 존재하는 depth, width, resolution의 모든 차원을 균형있게 조정한다면 더 높은 정확도와 효율성을 얻을 수 있고, 이러한 균형은 단순히 각각의 차원을 일정 비율로 scaling 하는 것만으로 달성할 수 있다는 사실을 알아내었다. 이러한 관찰을 바탕으로 본 논문에서는 효과적인 scaling 기법인 Compound scaling method를 제안한다.
- Compound scaling method는 기존의 임의적인 scaling 기법과는 달리 고정 scaling coefficient를 사용하여 network의 depth, width, resolution을 균일하게 scaling해주는 방식이다.
- 예를들어 $2^N$배의 computational resource를 사용하고 싶다면, 기존의 depth $\alpha$, width $\beta$, image size $\gamma$를 각각 $\alpha^N, \beta^N, \gamma^N$으로 늘려주면 된다는 것이다.
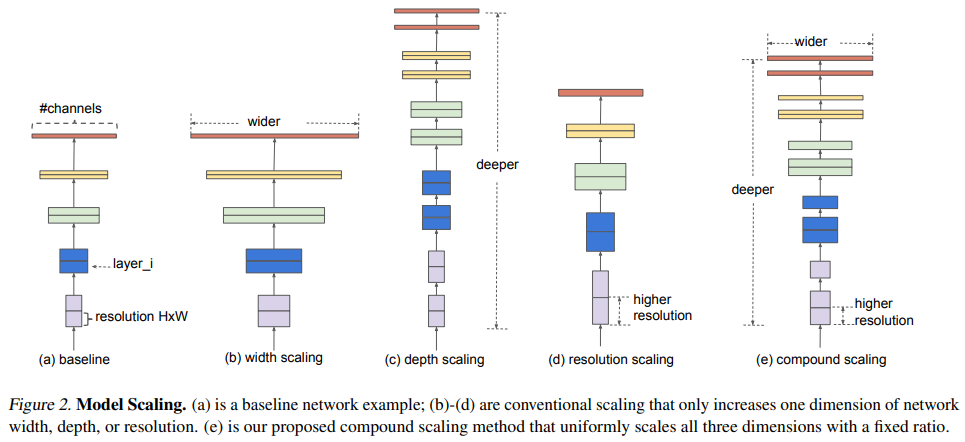
(a) : baseline network 예시
(b) ~ (d) : 각각 width, depth, resolution 한가지 씩만 scale up한 예시 ( 1차원씩만 증가시킨 scaling )
(e) : compound scaling
- compound scaling 방법은 입력 이미지가 클수록 network에서는 receptive field를 증가시키기 위한 더 많은 layer와 큰 이미지에서의 fine-grained 패턴을 찾아내기 위한 더 많은 channel을 필요로한다.
* fine-grained : 하나의 작업을 작은 단위의 프로세스로 나눈 뒤, 다수의 호출을 통해, 작업 결과를 생성해내는 방식
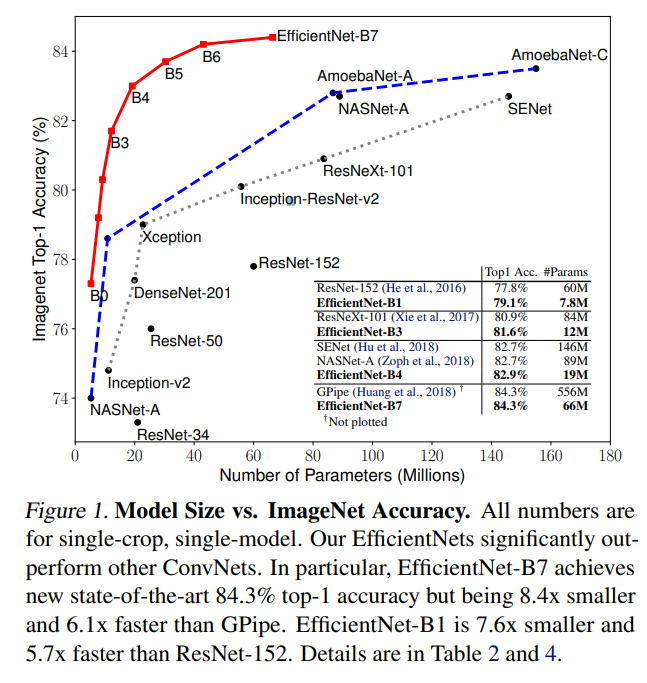
- Scaling 방법이 MobileNet과 ResNet에서 잘 작동하는 것을 확인할 수 있었다. Figure 1에서 볼 수 있듯이 EfficientNet이 다른 ConvNet 모델보다 성능을 크게 능가하고, 이 때 사용되는 parameter도 훨씬 적은 것을 확인할 수 있다.
2. Related Work
ConvNet Accuracy
- AlexNet이 2012년 ImageNet competition에서 우승한 뒤로 ConvNet의 정확도는 더욱 높아지고 있다. 하지만 이 모델들은 ImageNet 분류를 위해서만 디자인 되었고 크기가 크다.
- 최근의 연구들은 다양한 전이 학습과 object detection에서도 좋은 성능을 나타내고있지만 hardware memory limit에 다다랐기 때문에 효율성이 필요한 시점이다.
전이학습( Transfer Learning ) : 한 분야의 문제를 해결하기 위해서 얻은 지식과 정보를 다른 문제를 푸는데 사용하는 방식
딥러닝에서는 '이미지 분류'문제를 해결하는데 사용했던 네트워크를 다른 데이터셋이나 다른 task에 적용시켜 푸는 것을 의미한다. 네트워크는 일반적으로 다양한 이미지를 학습하는데, low layer에서는 low-level feature를, high layer에서는 high-level feature를 학습한다. 이렇게 이미 학습된 pre-trained 구조 뒤에 분류를 위한 Fully-connected layer를 붙여 학습시키는 것을 전이학습이라고 한다.
전이학습시 학습을 빠르게 수행할 수 있고, 작은 데이터를 학습할시 발생하는 과적합 문제를 방지할 수 있다.
전이학습(Transfer Learning)이란?
dacon.io
ConvNet Efficiency
- Model compression는 정확성을 줄이고 효율성을 높이는 일반적인 방법으로 최근 효율적인 모바일 크기의 ConvNet을 설계하기 위해 인기를 얻고있는 방법이다. 하지만 크기가 크고 튜닝 비용이 비싼 대형 모델에 이러한 기술을 적용하기가 힘든데, 본 논문에서는 Model Scaling을 통해 초대형 ConvNet의 모델 효율성을 연구하는 것을 목표로 한다.
Model Scaling
- ConvNet을 확장할 수 있는 방법에는 여러가지가 있다.
1. ResNet으로 네트워크 깊이(depth)를 조정하여 축소하거나 확장하는 방법
2. WideResNet, MobileNet으로 네트워크 폭(width)에 따라 확장하는 방법
3. 입력 이미지를 키우는 방법
- ConvNet의 표현력에 network의 깊이(depth)와 폭(width)가 중요하다는 것은 밝혀졌지만, 효율성과 정확성을 높이기 위해 ConvNet을 효과적으로 확장하는 방법은 아직 알려지지 않았다. 따라서 본 논문에서는 network의 깊이, 폭, 해상도 3차원 모두에 대한 Scaling을 통해 체계적이고 경험적으로 연구를 진행한다.
3. Compound Model Scaling
3.1. Problem Formulation
- ConvNet Layer $i$는 함수로 정의할 수 있다 : $Y_i = \mathcal{F}_i(X_i)$
$\mathcal{F}_i$ : 연산자
$Y_i$ : output tensor
$X_i$ : input tensor ( shape는 <$H_i, W_i, C_i$> )
- $H_i, W_i$ : spatial dimension
- $C_i$ : channel dimension
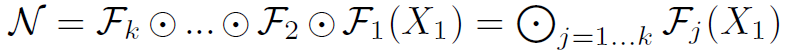
ConvNet의 여러개의 stage로 분할되고 각 stage의 layer들은 같은 architecture를 가진다. 따라서 전체 ConvNet은 아래와 같이 정의할 수 있다.
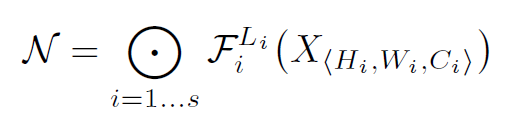
$\mathcal{F}^{L_i}_{i}$ : $\mathcal{F}_i$가 $i$단계에서 $L_i$번 반복되는 것
<$H_i, W_i, C_i$> : $i$층의 input tensor $X$의 형태
ex. 초기 input shape (224, 224, 3) -> 마지막 output shape (7, 7, 512) 까지 spatial dimension은 점차 축소되지만 channel dimension은 확장된다.
- 일반적인 ConvNet은 best layer architecture인 $\mathcal{F}_i$를 찾고자 하지만, model scaling은 기본 network에서 미리 정의된 $\mathcal{F}_i$를 변경하지 않고 network의 Length($L_i$), width($C_i$), resolution($H_i, W_i$)을 확장하려 한다. 이 때 모든 layer는 일정한 비율로 균일하게 scaling되어야한다. 결국 본 연구자들의 목표는 최적화문제로 공식화될 수 있는 주어진 제약에서 모델 정확도를 극대화하는 것이다.
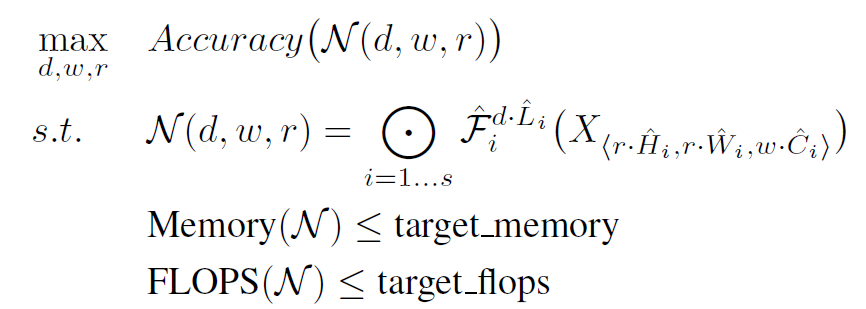
3.2. Scaling Dimensions
- 위 Problem은 최적의 d, w, r이 서로 의존하며 다른 제약 조건 아래서 값이 바뀐다는 문제점을 가진다. 이로인해 기존 방법들은 대부분 3가지 중 한 가지 차원만을 scaling하여 ConvNet을 확장하였다.
* FLOP (Floating Point OPerationS) : 딥러닝 모델이 얼마나 빠르게 동작하는지 계산하는 지표
FLOPS (FLoating point OPerationS) - 플롭스
개발한 딥러닝 모델은 얼마나 빠를까요? 특히, 모바일 같은 저사양 디바이스에서의 딥 뉴럴 네트워크에서는 성능보다는 해당 사양에서 원활히 돌아가는지가 서비스 측면에서 매우 중요합니다.
hongl.tistory.com
Depth(d)
- 네트워크 깊이를 확장하는 것은 ConvNet에서 일반적으로 사용하는 방법이다. 깊이가 깊을수록 더 풍부하고 복잡한 feature를 추출할 수 있어 일반화하기 좋다.
- 하지만 gradient vanishing 문제가 발생하기 때문에 학습에 어려움이 있다. ( gradient vanishing 문제를 해결하기 위한 skip connection, batch normalization 등의 해결 방법이 있지만, 매우 깊은 network에서는 잘 작용하지 않는다 )
Width(w)
- width를 scaling하는 방법은 주로 소형 모델에 사용된다.
- 넓은 network에서는 보다 fine-grained feature를 잘 찾아낼 수 있고 train하기 쉽다.
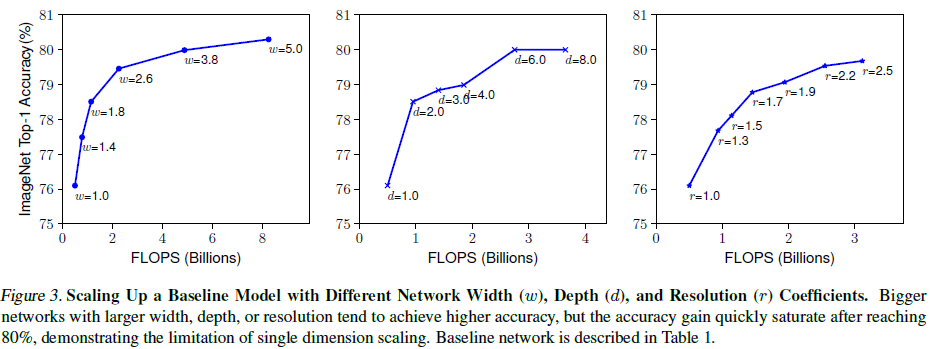
- 하지만 매우 넓지만 얇은 network에서는 high level feature를 찾기 어렵다. 위의 Figure 3의 왼쪽 width 실험 결과를 보면 w가 클수록 network가 훨씬 넓어지면 accuracy가 빠르게 saturate되는 것을 확인할 수 있다.
Resolution(r)
- ConvNet은 고해상도 input image를 받을 때 더 fine-grained한 패턴을 포착할 수 있다. 최근에는 GPipe에서 480x480 해상도로 SOTA ImageNet accuracy를 달성하기도 했다.
- 하지만 Figure 3의 오른쪽 resolution 실험 결과를 보면 고해상도에서 정확도가 향상하지만, 매우 높은 해상도에서는 accuracy gain이 떨어지는 것을 확인할 수 있다.
Observation 1
: network의 width, depth, resoluton의 모든 차원을 확대하면 accuracy가 향상되지만, 모델이 클수록 정확도가 낮아진다.
3.3. Compound Scaling
- 본 논문의 저자들은 다른 scaling dimension들이 독립적이지 않다는 것을 경험적으로 관찰하였다.
- 직관적으로 봤을 때 resolution이 높아지면 큰 receptive field가 큰 이미지 안에서 더 많은 픽셀을 포함하는 비슷한 feature들을 포착하는데 도움이 될만큼 network의 depth를 늘려야 한다.
* receptive field : 출력 레이어의 뉴런 하나에 영향을 미치는 입력 뉴런들의 공간 크기
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=sogangori&logNo=220952339643
receptive field(수용영역, 수용장)과 dilated convolution(팽창된 컨볼루션)
receptive field 는 출력 레이어의 뉴런 하나에 영향을 미치는 입력 뉴런들의 공간 크기이다. 그림 1) 일반...
blog.naver.com
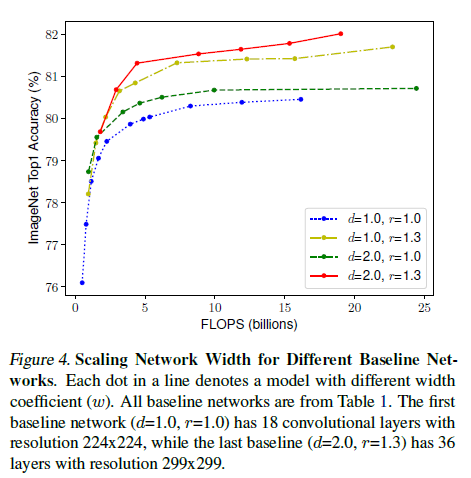
- depth = 1, resolution = 1을 변경하지 않고 width만 scaling할 경우 accuracy가 빠르게 saturate된다. 더 깊고(d=2), 더 해상도가 높은(r=2) 상태에서의 width scaling은 동일한 FLOPS에서 더 좋은 accuracy를 달성한다.
Observation 2
: Scaling을 할 때 정확성과 효율성을 높이기 위해서는 network의 width, depth, resolution의 모든 dimension을 균형하게 조정해야한다.
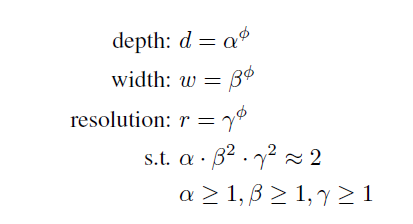
$\phi$ : user-specified coefficient ( 모델 scaling에 사용되는 resource의 수를 제어 )
$\alpha, \beta, \gamma$ : 각각 depth, width, resolution의 extra resource
일반적인 convolution FLOPS는 $d$, $w^2$, $r^2$에 비례한다. 즉, 네트워크의 depth를 2배할 경우 FLOPS가 2배로 증가하지만, width나 resolution을 2배할 경우 FLOPS는 4배로 증가한다.
FLOPS는 $(\alpha\cdot\beta^2\cdot\gamma^2)^\phi$로 표현할 수 있고 본 논문에서는 $\alpha\cdot\beta^2\cdot\gamma^2$를 2에 가깝도록 만들었다.
4. EfficientNet Architecture
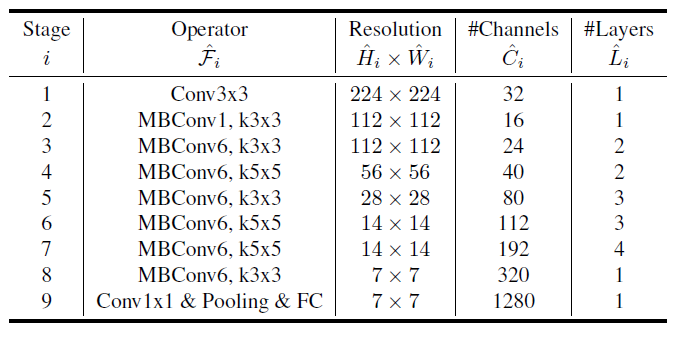
- $\mathcal{F}_i$를 바꾸지 않기 때문에 좋은 성능의 baseline network를 만드는 것이 중요하다.
- MBConv는 Mobilenet v2에서 제안된 inverted residual block이다. (숫자는 expand ratio)
* inverted residual block : 일반적인 residual block과 반대로 skip connection을 진행하여 메모리 사용량을 줄이는 방법
https://gaussian37.github.io/dl-concept-mobilenet_v2/
MobileNetV2(모바일넷 v2), Inverted Residuals and Linear Bottlenecks
gaussian37's blog
gaussian37.github.io
- ImageNet의 size인 224x224를 input size로 사용
- Activation function으로 Swish를 사용, Swish는 깊은 neural network에서 ReLU보다 높은 정확도를 보인다.
- Squeeze-and-Excitation optimization도 사용
문제 해결 단계
- 큰 모델에서 직접 $\alpha, \beta, \gamma$를 찾으면 더 좋은 성능을 얻을 수 있지만, 검색 비용이 매우 비싸다.
step 1. $\phi$=1로 고정, 2배 더 많은 resource를 사용할 수 있다고 가정, equation 2와 3를 이용해 소규모 grid search 방식으로 $\alpha, \beta, \gamma$를 찾음. 이렇게 찾은 best value는 $\alpha$ = 1.2, $\beta$ = 1.1, $\gamma$ = 1.15이다.
(search once on the small vaseline network)
step2. 다음으로 $\alpha, \beta, \gamma$를 상수로 고정하고 equation 3를 이용해 $\phi$를 바꿔가며 baseline network를 scale up함 ( EfficientNet B1 ~ B7 )
( use the same scaling coefficients for all other models )
5. Experiments
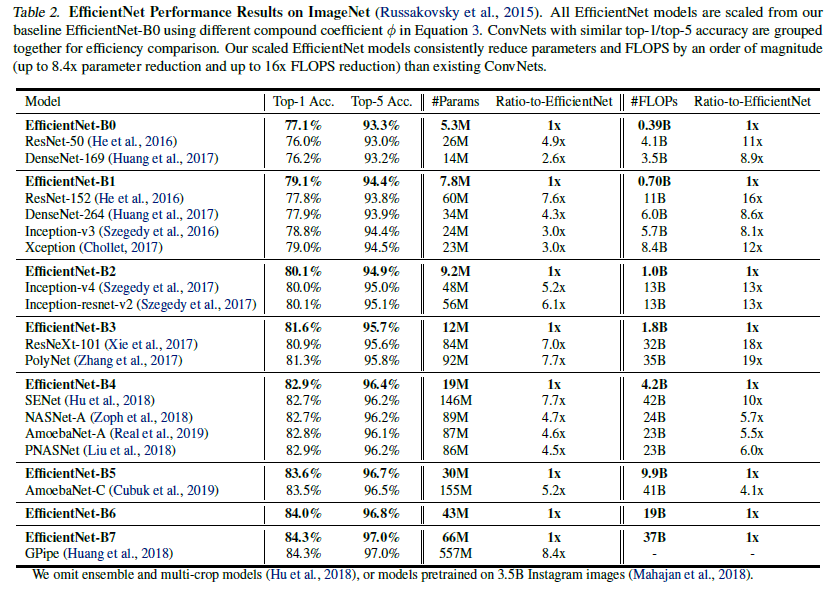
- EfficientNet B0 ~ B7의 ImageNet data 성능 ( 비슷한 성능을 가지는 모델 대비 parameter의 수가 적고 FLOPs가 적다 )
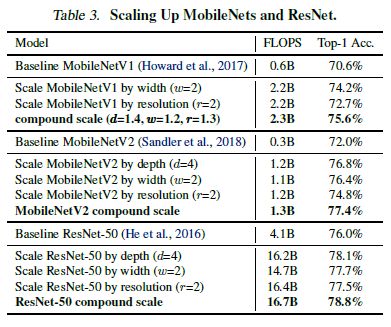
- MobileNet과 ResNet에 적용시켜 보았을 때 단일 dimension scaling보다 compound scaling의 효과가 좋았다.
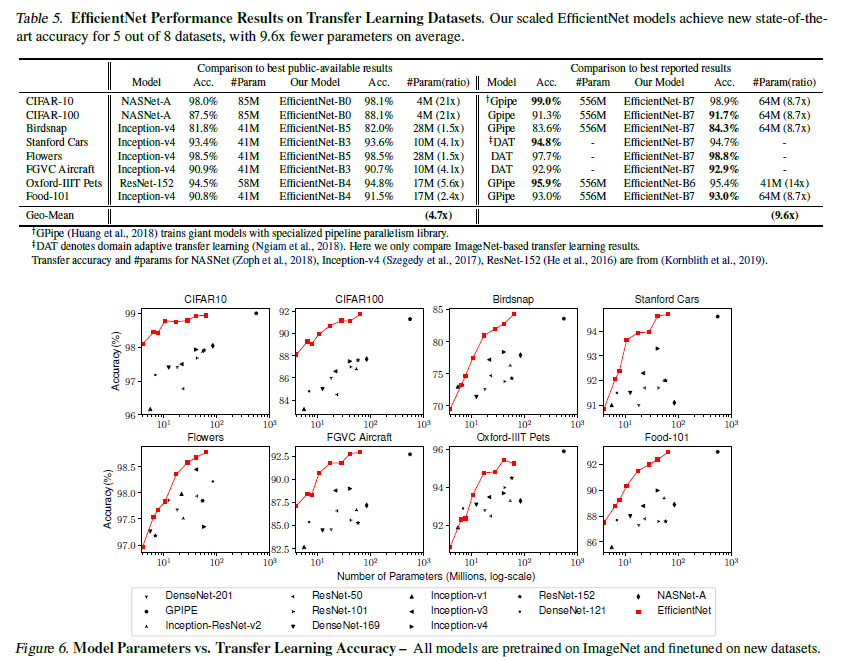
- 더 적은 parameter로 5개의 dataset에서 accuracy SOTA를 기록했으며 전이학습에서도 좋은 성능을 보인다.
6. Discussion
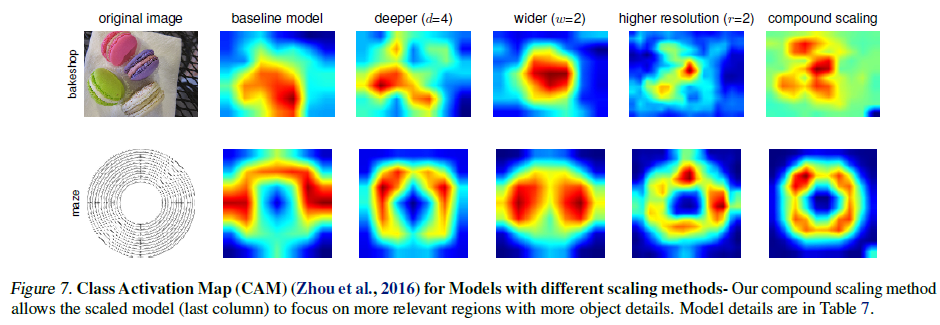
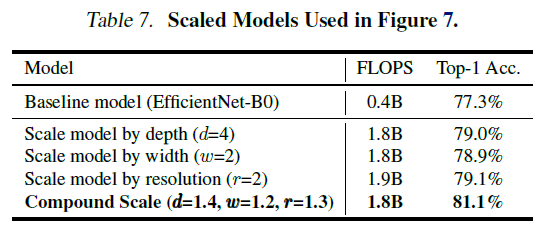
- compound scaling을 적용한 모델이 object detail을 가지는 relevant region을 더 잘 표현한다.
- compound scaling의 중요성 시사
< 참고자료 >
https://wandukong.tistory.com/20
[논문 리뷰] EfficientNet 논문 리뷰 (Rethinking Model Scaling for Convolutional Neural Networks)
Transformer에 이어 ViT를 리뷰하려고 했으나,, 인턴 때 사용해보았던 Efficient Net이 급 궁금해져서 읽어보았습니다. EfficientNet : Rethinking Model Scaling for Convolutional Neural Networks (2020) 논문..
wandukong.tistory.com
https://visionhong.tistory.com/19
[논문리뷰] EfficientNet
이번 포스팅에서는 Google Brain에서 2019년에 발표한 EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks(Image Classfication) 논문에 대해 리뷰하려고 한다. 1. Introduction 본 논문..
visionhong.tistory.com
세 줄 요약
1. ConvNet에서 더 높은 정확도와 효율성을 얻기 위한 EfficientNet 제안
2. 주어진 Equation에 따라 적절한 Depth, Width, Resolution을 구해 Compound Scaling 수행
3. 여러 data에서 SOTA를 기록했으며 전이학습에서도 좋은 성능을 보임

'논문 paper 리뷰' 카테고리의 다른 글
| [X:AI] ASR(Automatic Speech Recognition) 이해하기 (0) | 2022.08.17 |
|---|---|
| [X:AI] YOLO 논문 이해하기 (0) | 2022.07.19 |
| [X:AI] MobileNet 논문 이해하기 (0) | 2022.07.18 |




댓글