# 본 프로젝트는 '2023 6th D&A AI BigData Conference'에서 발표한 프로젝트임을 명시합니다.
( 2023.06.26 ~ 2023.12.01 )

주제
한국 농인을 위한 수어 통역 시스템 구축
팀원
수어 사운드 스쿼드 (류병하, 이동근, 주민지, 천예은)
배경
현재 대한민국에는 청각/언어 장애인의 수보다 수어 통역사가 부족하여 청각/언어 장애인의 사회 참여와 생활 편의에 많은 어려움이 존재한다. 또한 새롭게 수어 공부를 하는데 있어 정형화된 수어 사전이 없어 동작 하나하나를 찾거나 물어가며 공부해야 하는 실정이다. 따라서 본 프로젝트에서는 한국의 청각/언어 장애인의 의사소통을 돕기 위한 수어 통역 시스템을 구축하는 것에 목표를 둔다.
(본래 실시간 시스템을 구축하는 것을 목표로 하였으나 모델의 Inference 속도를 개선하지 못하여 추후 개선 과제로 남겨 두었다.)
방법
1. 수어 영상 자세 추정(Pose Estimation)
- 학습 데이터 수집 및 가공 : AI Hub 수어 영상 데이터
- 활용 모델 : OpenPose
2. 관절 데이터 인공지능 모델 학습
- 데이터 전처리 : Normalization, Padding 등 (참고 논문 : Openpose와 GRU 결합을 활용한 수어 단어 인식)
- 모델링 : Bi-LSTM + Attention
3. 조사 예측 및 문장 생성
- 활용 모델 : KLUE-BERT base
4. TTS 음성 출력
- 활용 모델 : gTTS
5. UI Demo 시연
- 테스트 데이터 수집 및 가공 : 전문 수어 통역사 + 팀원들이 직접 촬영하여 수집
- UI 구현 : PySide6
6. 결론
코드 정리
https://github.com/Rahites/Hands_Sound_Squad
GitHub - Rahites/Hands_Sound_Squad
Contribute to Rahites/Hands_Sound_Squad development by creating an account on GitHub.
github.com
1. 수어 영상 자세 추정 (Pose Estimation)
1.1. 학습 데이터 수집 및 가공
활용 데이터 : AI Hub 수어 영상 데이터

- 지숫자, 지문자의 데이터 영상 생성을 통해 길찾기, 교통, 주소 등과 관련된 한국수어 인식 인공지능 기술 및 서비스 개발에 활용 가능한 총 536,000개의 영상 데이터
- 하나의 단어에 대해 18명의 수어 원본 영상과 keypoint json 파일 등으로 구성
- 본 프로젝트에서는 16명분의 데이터를 학습, 2명분의 데이터를 테스트에 활용하였고 정면에서만 찍은 영상만을 사용
1.2. 활용 모델
활용 모델 : OpenPose

- Face : 70개, Pose : 25개, LeftHand : 21개, RightHand : 21개로 총 137개의 관절 좌표 추출
- AI Hub 데이터 또한 OpenPose를 우선적으로 사용해서 KeyPoint를 뽑고 사람이 수정함
- 수어에는 수지 신호뿐만 아니라 비수지 신호 또한 중요하기 때문에 한번에 Face Detection까지 가능한 OpenPose 모델을 선정
2. 관절 데이터 인공지능 모델 학습
2.1. 데이터 전처리
- AI Hub 수어 영상 데이터를 활용한 기존 연구를 참고하여 데이터 전처리 수행
(참고 논문 : OpenPose와 GRU 결합을 활용한 수어 단어 인식)
- 단어는 모든 단어가 아닌 국립 국어원의 한국수어사전에 등록되어 있는, 즉 자주 쓰이는 단어만으로 선정
- 이미지 사이즈에 맞추기 위한 정규화, 영상 별 Frame 수를 맞추기 위한 Padding 진행
2.2. 모델링

3개의 Bi-LSTM + Attention Layer를 통과시킨 결과를 합친 후 Residual Block을 이용하여 FC Layer를 통과시키는 모델 구조
Bi-LSTM : 영상마다 Frame이 동작의 연속으로 이루어져 있어 데이터의 시계열적인 면을 분석하기 위해 사용
Attention : LSTM 모델의 모든 Step의 결과를 활용해 분석을 하기 위해 사용
실험 결과
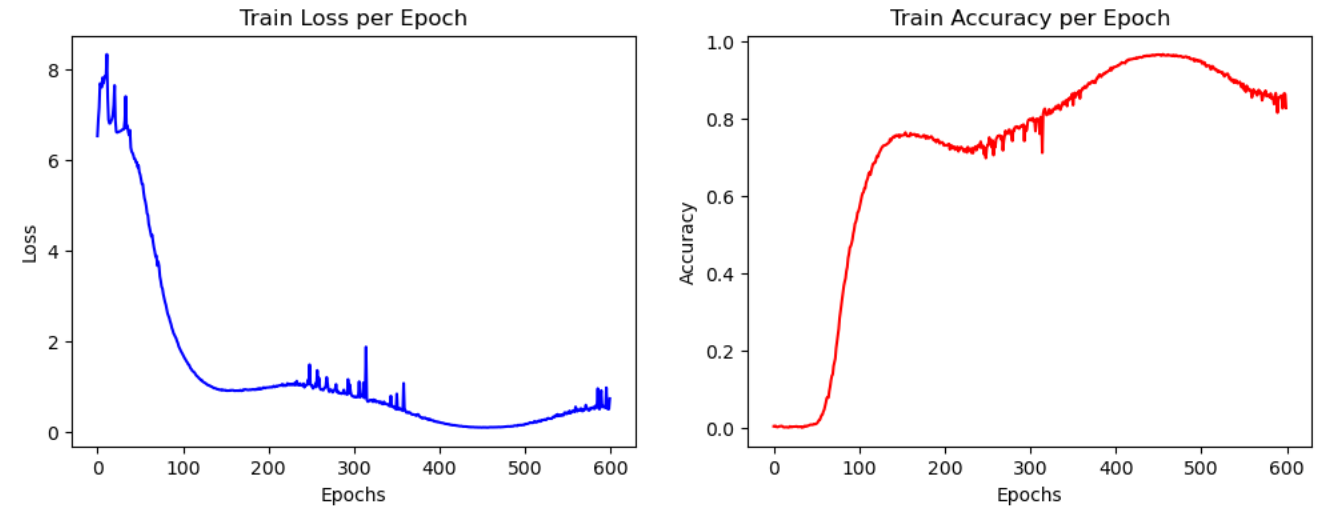
최고의 성능을 찾아내기 위해 다양한 아키텍처의 모델 실험을 진행하였으며, 최종적으로는 AdamW, CosineAnnealingLR을 활용한 위 아키텍처 구조에서 가장 좋은 성능을 보임 (Accuracy : 90.59%)
3. 조사 예측 및 문장 생성
활용 모델 : KLUE-BERT base
매커니즘
- 단어를 순서대로 입력
- KLUE-BERT base 기반 함수 적용
- 단어 집합의 집합으로 예측한 문장 출력

위와 같이 진행한 이유
: 우선 문장 단위로 영상 학습을 하기에는 컴퓨팅 파워가 마땅치 않았고, 수어에는 조사가 없는 단어의 집합이기 때문에 수어를 모르는 사람에게 어색하지 않은 문장으로 들려주기 위한 조사 예측이 필요함
4. TTS 음성 출력
활용 모델 : gTTS

5. UI Demo 시연
5.1. 테스트 데이터 수집 및 가공
데이터 수집 방법 : 전문 수어 통역사께 부탁 + 팀 내부에서 직접 촬영


5.2. UI 구현
활용 패키지 : PySide6
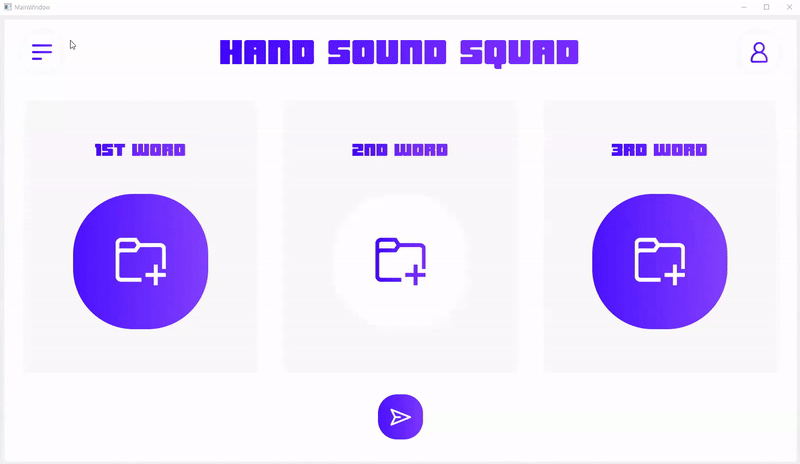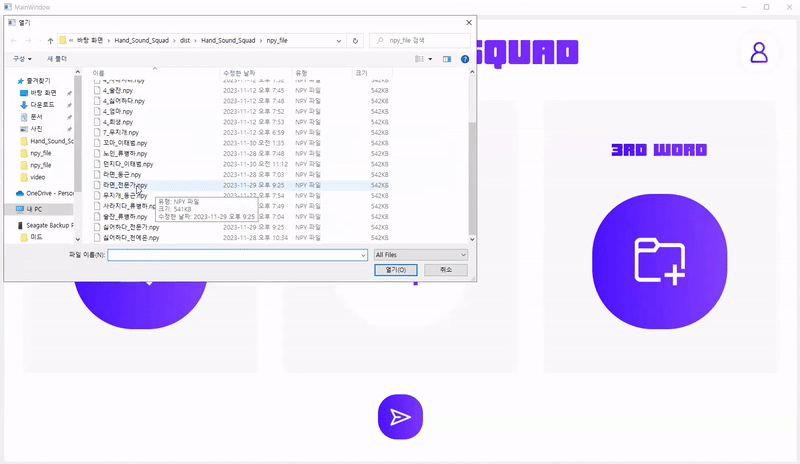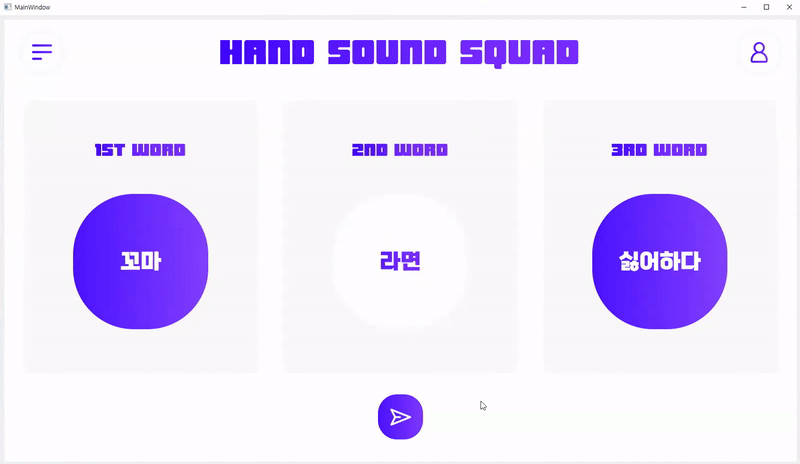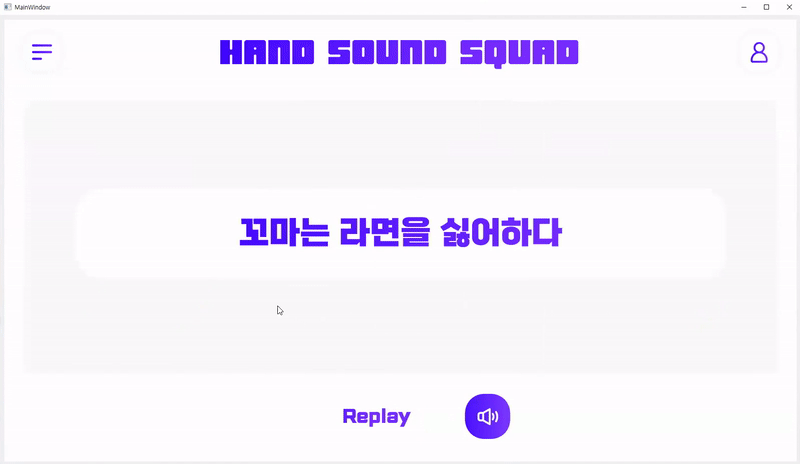
6. 결론
본 프로젝트를 처음 시작했을 때 기획했던 "실시간 수어 번역"은 아니지만, 영상이 들어왔을 때 단어를 잘 예측 할 수 있도록 Flow를 구성
(1) OpenPose 모델로 Keypoint를 뽑아내고
(2) 뽑아낸 Keypoint를 가지고 전처리를 진행
(3) 전처리가 완료된 npy 파일을 학습된 모델에 넣어 단어 예측
이후에는
(4) 모델이 예측한 단어들을 <MASK>로 이어 조사 예측 진행
(5) 예측한 조사로 문장을 만들고 TTS로 mp3 파일 생성
Contribution
- 비수지 신호 반영 : OpenPose 모델을 활용하여 수어의 주요 구성 요소인 비수지 신호 반영
- 수어 단어의 문장화 : 수어의 조사 부재로 인한 소통의 어려움 해소에 도움
- UI 기반 서비스화 : 수어 통역사 부족으로 인한 사회 문제에 도움
- 국내 연구 기여 : 한국 수어에 특화된 모델을 구축하여 관련된 국내 연구에 기여
한계점 및 발전 방향
- 처음 기획했던 "실시간"을 이루어내지 못함 : 추후 컴퓨팅 파워 및 코드 개선으로 실현 가능
- Voice Conversion 발전 방향 : 현재 gTTS를 통해 단일 음성 지원, 추후에 다양한 음성으로 제작 가능
- 한정된 데이터 셋을 넘어 모델 성능 고도화 : 일반화 성능 향상 및 다양한 상황에 적용 가능
후기
뜨거운 여름부터 날이 추워지기 시작한 겨울의 초입까지, 같이 노력한 팀원들 덕분에 마지막 발표까지 잘 끝마칠 수 있었습니다. 작년 D&A Conference 때에는 막내 학번으로 참여해 선배들의 도움을 많이 받은 만큼 이번에는 조장으로서 팀원들과 같이 이번 프로젝트를 마무리하고 싶어 더 열심히 참여했던 프로젝트였던 것 같습니다.
물론 시작은 순탄치 않았습니다. "실시간 수어 번역"이라는 프로젝트 주제는 깔끔하게 잡아두었지만, 본래 목표로 하였던 "실시간"을 구현하기가 어려웠고 "수어"라는 언어가 생각보다 체계가 복잡하여 "번역이라는 게 가능할까?"라는 원초적인 질문까지 들 정도로 프로젝트 발전 방향을 잡기가 어려웠습니다.
하지만 여름방학부터 매주 줌으로, 대면으로 이어왔던 회의 덕분에 금세 프로젝트의 방향성을 수립할 수 있었고 팀원들이 각자 맡은 역할을 잘 수행해 주었기 때문에 단어 예측 모델링부터 조사 예측, UI 구현, TTS까지 다양한 기능들을 구현할 수 있었습니다. 이번 프로젝트는 작년에 진행했던 "실시간 지화 번역 프로젝트"에서 발전시킨 주제로 스스로 너무나도 하고 싶었던 주제였고 팀원분의 가족 중에 전문 수어 통역사가 계셨던 점 또한 프로젝트를 디테일하게 마무리할 수 있었던 원동력이 되었습니다.
졸업을 앞둔 지금, 이번 프로젝트가 제 대학 생활에서의 마지막 장기 프로젝트라고 생각합니다. 주제가 어렵기도 하고 다들 시간이 바쁘실 텐데도 저를 믿고 따라와 주신 팀원분들께 정말 감사드리고, 이번 프로젝트 경험이 팀원분들에게 많은 도움이 되었으면 좋겠습니다.

'프로젝트' 카테고리의 다른 글
| [캡스톤디자인] 시각장애인을 위한 한국어 시각 정보 질의응답 연구 (0) | 2023.12.31 |
|---|---|
| [프로젝트] 내가 이모티콘이 된다면 (0) | 2023.02.04 |
| [프로젝트] 서울시 대기오염의 주범은? (0) | 2023.01.24 |




댓글