# 본 프로젝트는 '2022-2 다변량 통계 분석 수업' 과제로 제출한 프로젝트임을 명시합니다.
( 2022.11.09 ~ 2022.12.16 )
주제
대기오염에 따른 서울시 지역 군집화
팀원
최준용, 한윤지
방법
1. 데이터 수집
: 서울시 대기오염 측정소 50곳의 3개년 일별 대기오염 Data 수집
2. 데이터 전처리
: 시계열 Data의 특성을 없애는 방향으로 전처리 진행 (Time Series -> 월별, 계절별... 등등)
3. 데이터 분석
: Linkage Method, Clustering, 요인 분석 등의 군집화 기법을 활용하여 지역 군집화
4. 결론 및 군집화 결과 시각화
: folium 모듈을 사용해 실제 측정소의 위치 및 주변 도로 지도 시각화
https://github.com/Rahites/Clustering_Seoul_from_Air_Pollution
GitHub - Rahites/Clustering_Seoul_from_Air_Pollution
Contribute to Rahites/Clustering_Seoul_from_Air_Pollution development by creating an account on GitHub.
github.com
1. 데이터 수집
- 서울시 대기오염 측정소 50곳의 3개년 일별 대기오염 Data 수집

- 서울시 일별 평균 대기오염도 정보 (2020 ~ 2022)
: 이산화질소, 오존, 일산화탄소, 아황산가스, 미세먼지, 초미세먼지 6개의 Column
https://data.seoul.go.kr/dataList/OA-2218/S/1/datasetView.do#AXexec
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr
2. 데이터 전처리
(1) 결측치 처리
(2) 시계열 데이터의 특징 지우기 (Time Series -> 일별, 월별, 계절별...)
(3) Feature 생성 (169 columns)
3. 데이터 분석
3.1. 군집분석
- Linkage Method 활용 (군집화가 잘 이루어진 Ward 방법 채택)

- 적절한 군집 개수를 파악하기 위해 Elbow Method 활용

- Ward Method을 활용해 6개 군집으로 군집화 진행
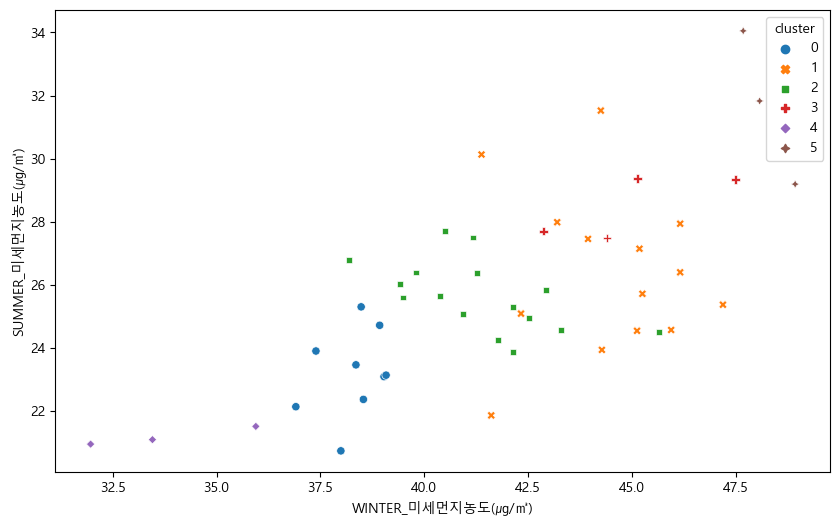
3.2. PCA
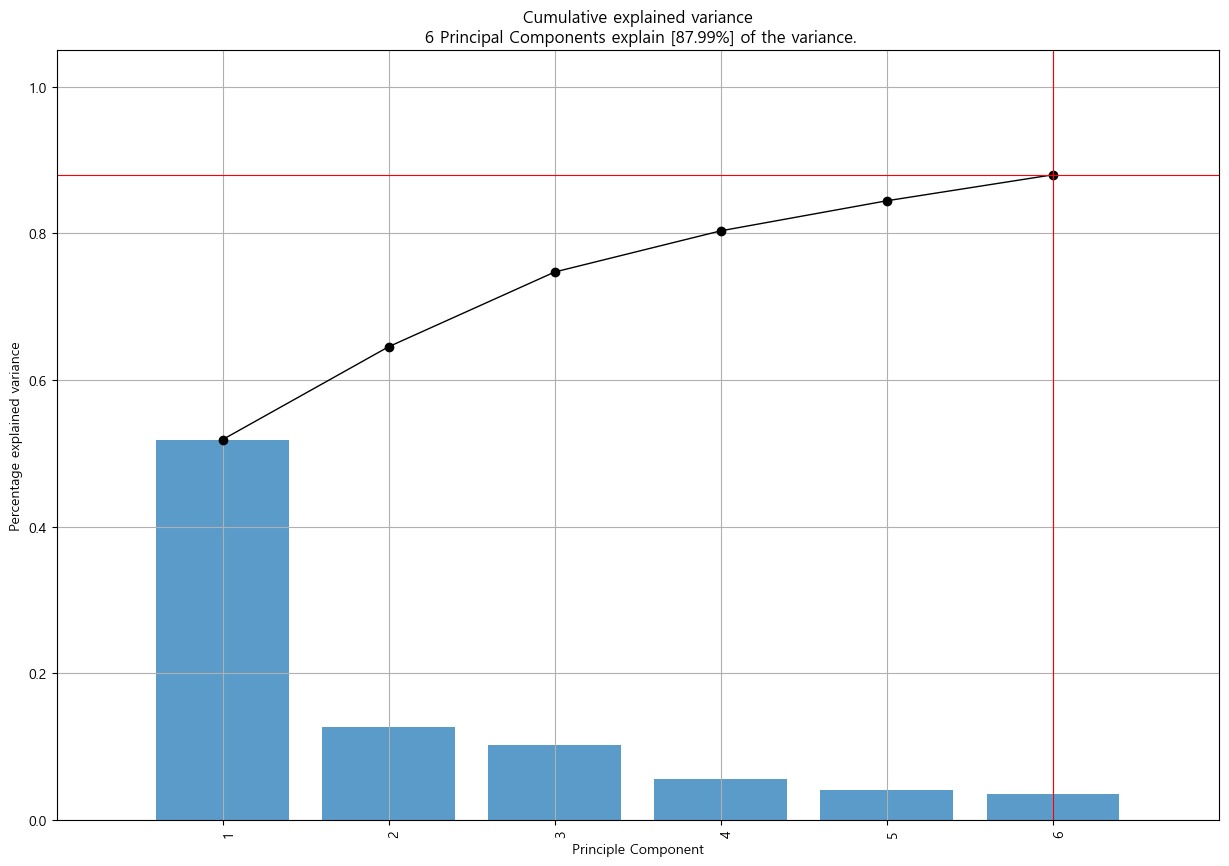
- 특성파악을 위해 주성분 분석
- Biplot 시각화
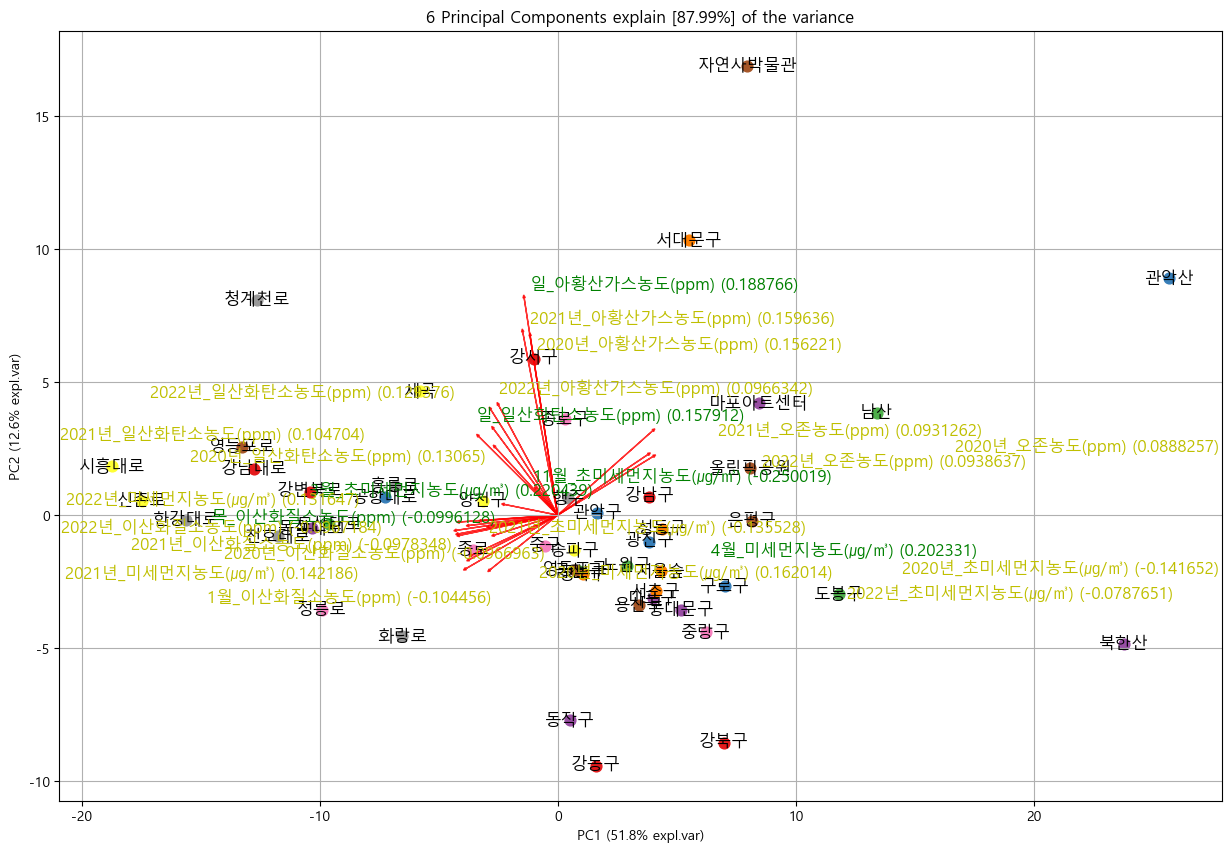
: 직관적으로 보았을 때 PC1이 0일 때를 기준으로 왼쪽은 차가 많이 다니는 곳 (ex. 대로변들, 다 끝에 '로'가 붙어있음)
오른쪽은 깨끗한 지역 (ex. 산, 박물관, 공원)
3.3. 요인분석
- Factor Analyzer 분석

- Factor_1
- 미세먼지농도, 초미세먼지농도에 대한 factor loading 값이 큼
- "미세먼지오염"이라고 명명
- Factor_2
- 이산화질소농도, 일산화탄소농도, 아황산가스농도에 대한 factor loading 값이 큼
- 자동차의 배기가스에서는 질산화물질(NOx), 일산화탄소(CO), 탄화수소(HC), 총먼지(TSP : Total Solid Particlate), 아황산가스(SO2) 등 대기를 오염시키는 주요 물질 배출
- 따라서 "자동차환경오염"이라고 명명
- Factor_3
- 오존농도에 대한 factor loading 값이 큼
- "오존오염"이라고 명명
4. 결론 및 군집화 결과 시각화
- 분석한 결과 점수화
- 군집별 특징 분석 결과
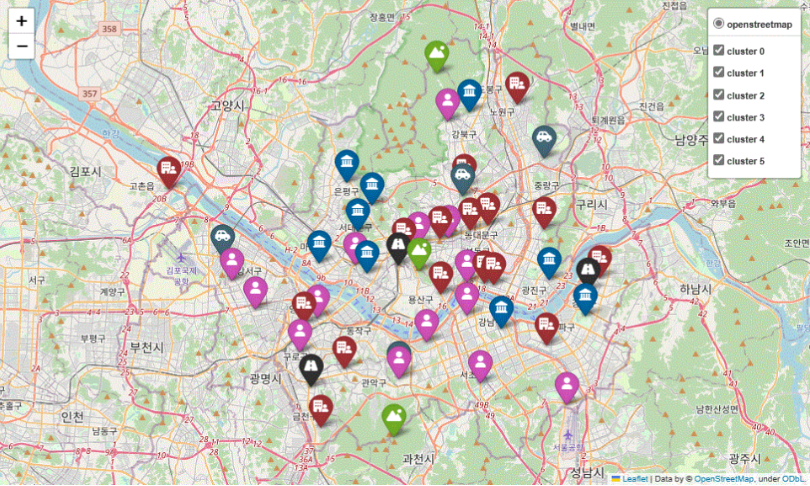
- cluster 0 : 비교적 최근 교통량이 적고, 강남구, 광진구, 마포구, 서대문구, 은평구 등으로 군집화되었다.
- cluster 1 : 강북구, 강서구와 같이 비교적 조용한 지역과 청계천, 종로 등의 지역으로 군집화되었다.
- cluster 2 : 관악구, 강동구, 서울숲같이 유동인구는 많지만 거주하는 인구는 상대적으로 적은 지역으로 군집화되었다.
- cluster 3 : 공항대로, 동작대로, 정릉로, 화랑로같이 도로 위주로 군집화되었다.
- cluster 4 : 산에 있는 측정소로 군집화되었다. 미세먼지가 제일 적고 자동차 오염이 제일 적으며, 오존 오염정도가 가장 높다는 특징을 지닌다.
- cluster 5 : 미세먼지점수가 제일 안좋은 시흥대로, 천호대로, 한강대로로 대로변 위주로 군집화되었다.
- 군집별 foilum 시각화
- 문제해결 방법 제안
1. 도로 청소 경로 지정
- 군집별로 미세먼지가 많은 시간을 예측해서 시행하는 것이 매일 청소를 진행하는 것보다 효율적
- 현재는 일별 데이터 분석만을 진행하였지만 시간대별 데이터를 분석하여 미세먼지가 심한 시간대에 해당 Cluster의 도로 Map을 보고 도로 청소 경로를 지정 (ex. 심한 군집은 2회, 심하지 않은 군집은 1회)
2. 군집별 대기 환경 정책
- 대기 환경 요인을 파악하여 군집화된 지역별로 다른 환경정책을 실시하여 대기오염 정도를 최소화 시킬 수 있음
'프로젝트' 카테고리의 다른 글
| [프로젝트] 내가 이모티콘이 된다면 (0) | 2023.02.04 |
|---|---|
| [프로젝트] 실시간 수어 번역 인식 모듈 생성 (0) | 2023.01.02 |
| [프로젝트] 얼굴인식으로 영상 합성하기 (0) | 2022.08.22 |




댓글