[Paper Review] Stacked Hourglass 논문 이해하기
『 Stacked Hourglass Networks for Human Pose Estimation. ECCV. 2016. 』
이번에 소개할 논문은 Human Pose Estimation에서 성능을 높일 수 있는 방법론을 소개한 Stacked Hourglass Network 논문이다. 본 논문에서는 Pooling과 Upsampling을 통해 원하는 Joint Location의 Heatmap을 예측하는 모델을 소개한다. 언뜻보면 U-Net의 방법론과 비슷하며 AutoEncoder, VAE 등 무언가 정보를 잘 집약하고 다시 풀어주는 형태의 연구가 해당 시기에 많이 이루어진 것으로 보인다.
Paperswithcode
https://paperswithcode.com/paper/stacked-hourglass-networks-for-human-pose
Papers with Code - Stacked Hourglass Networks for Human Pose Estimation
🏆 SOTA for Pose Estimation on FLIC Wrists (PCK@0.2 metric)
paperswithcode.com
0. Abstract
본 논문에서는 Intermediate Supervision과 함께 반복되는 Bottom-Up, Top-Down이 네트워크 성능을 향상시키는데에 얼마나 도움이 되는지를 보여준다. 이러한 아키텍처를 Stacked Hourglass Network라고 부르며 이 네트워크는 다양한 Scale에서 나타나는 특징들을 통합하여 Spatial Relationship을 잘 포착할 수 있다.
Bottom-Up : 이미지의 낮은 수준의 특징에서 시작하여 점점 더 높은 수준의 특징을 추출하는 방법. 이미지의 해상도를 점차 낮추며 Pooling을 통해 더 추상적이고 전역적인 정보를 얻는다.
Top-Down : Bottom-Up에서 추출한 높은 수준의 정보를 바탕으로 해상도를 다시 높여가며(Upsampling) 세부적인 예측을 진행하는 방법. 국소적인 디테일을 찾는데에 중요한 역할을 한다.
Up과 Down이라고 쓰여있다 해서 해상도를 점차 올리고, 낮추지 않는다는 점을 기억하자!!
1. Introduction

Pose Estimation은 단일 RGB 이미지가 주어졌을 때, 정확한 픽셀 위치를 찾고자 하고 이 때 옷이나 조명과 같은 외부 요인에 Robust해야할 필요성이 존재한다.
초기 연구들은 국소적으로는 Robust한 이미지 Feature를, 전체적으로는 정교한 구조적인 예측을 통해 이러한 문제들을 극복하였지만, Convolution Network의 등장 이후 파이프라인이 많이 바뀌게 되었다. 그 중 하나의 방법으로 본 논문에서는 Stacked Hourglass 네트워크를 제안한다.
Figure 1에서 볼 수 있듯이 최종 Network 출력을 얻기 위해 사용되는 Pooling-Upsampling 단계를 Hourglass(모래시계)라고 부른다. Hourglass 네트워크는 매우 낮은 해상도까지 Pooling을 진행하고, 다중 해상도에서의 Feature를 Upsampling하고 결합한다. Hourglass 모듈 여러개를 연속적으로 결합하는 것으로 여러 Scale에 걸친 반복적인 Bottom-Up, Top-Down Inference가 가능하다.
Intermediate Supervision과 사용되는 반복되는 Bidirectional Inference는 네트워크의 최종 성능에 큰 영향을 미친다. 이에 FLIC와 MPII Human Pose 데이터에서 좋은 성능을 보였다.
여기서 Hourglass 모듈을 Bidirectional하다고 표현하는 이유는 Bottom-Up과 Top-Down 과정이 반복적으로 수행되며 모델이 상호 보완적으로 작동하기 때문이다. 모델의 흐름이 Bidirectional LSTM처럼 정말로 양방향으로 흐르는 것이 아닌 두 가지 방식의 상호작용을 통해 양방향적인 정보 흐름이 생겨난다고 보는 것이다.
여기까지만 읽고 드는 생각 : Hourglass.... AutoEncoder 구조를 이름만 바꾼거 아니야??
2. Related Work
Deep Learning과 Pose Estimation을 처음 결합한 DeepPose 모델은 네트워크를 통해 관절의 x, y 좌표를 직접 Regression하였다. 하지만, 최근 이미지를 여러 해상도, 다양한 Scale을 통해 특징을 포착하여 Heatmap을 생성하는 연구들이 등장하고 있다. 본 논문 또한 Heatmap을 기반으로 여러 Scale에서 정보를 포착하고 다양한 해상도에서 특징을 결합하는 방법을 연구하였다.
기존 Heatmap 기반의 연구들은 Graphic 기반의 모델링이나 신체에 대한 모델링을 진행하였지만, 본 논문에서는 이러한 모델링 없이도 좋은 성능을 달성하였다. 또한 기존의 Iterative Error Feedback, Multi-stage pose machine 방법론들과 달리 본 논문에서는 Intermediate Supervision을 사용한다.
이전 연구들 중에는 Fully Convolution Network를 기반으로 Part Segmentation을 진행하는 연구도 있었지만, Hourglass 모듈은 RGB 이미지에서 한 사람의 Keypoint를 정확하게 추정하는 것에 집중하고 있다. 또한 Fully Convolution Network와 연결되어 Bottom-Up에 치중을 둔 기존 연구와 달리 Hourglass에서는 Bottom-Up과 Top-Down에 용량을 대칭적으로 분배하고 있다.
다른 Convolution-Deconvolution 기반의 Encoder-Decoder 아키텍처 연구들도 비슷한 연구들이 존재하기는 했지만 본 논문에서는 Unpooling이나 Deconvolution을 사용하지 않으며 대신 Nearest Neighbor Upsampling과 Skip Connection을 사용한 Top-Down을 수행한다. 또한 여러개의 Hourglass를 Stacking하여 반복적인 Bottom-Up, Top-Down을 수행한다는 점에서도 차이가 존재한다.
여기까지 읽고 나니 생각 : Hourglass 모듈이 Encoder-Decoder 구조와 비슷하지만 다른 점이 있구나
3. Network Architecture

3.1. Hourglass Design
얼굴, 손과 같은 특징에는 Local Evidence가 필요하지만, 최종적인 Pose Estimation을 위해서는 몸 전체에 대한 정보 또한 중요하다. 따라서 Hourglass 모듈은 모든 Scale에 존재하는 정보를 포착한다. 다양한 Scale에서 인식할 수 있는 특징들을 포착하고 결합하여 픽셀 단위의 예측을 가능케 만든다.
Hourglass에서는 매 해상도마다 공간적인 정보를 보전하기 위해 Skip Layer를 사용한 Single Pipeline을 사용하였다. 네트워크가 줄어드는 해상도의 가장 작은 크기는 4x4 pixel이며 이 때 전체 이미지에서 Feature를 비교할 수 있는 작은 공간 필터가 적용된다.
여기서 말하는 공간필터란? -> 뒤에서 나오는 3x3 크기의 Kernel을 의미(Inception 구조)
Hourglass 구조를 정리하면 다음과 같다(Figure 3 참고).
1) Bottom-Up 처리
Convolutional Layer와 Max Pooling Layer를 사용하여 Feature를 매우 낮은 해상도까지 처리한다. 각 Max Pooling 단계에서 네트워크가 분기하여 Pooling 이전의 해상도에서 추가적인 Convolution을 적용한다.
2) Top-Down 처리
가장 낮은 해상도에 도달했다면 이제 Top-Down 시퀀스를 실행한다. 여기서 Top-Down 시퀀스는 Upsampling과 Scale에 걸친 Feature 결합을 말한다. 인접한 두 해상도의 정보를 결합하기 위해 낮은 해상도의 Feature를 Nearest Neighbor Upsampling하고 두 Feature 집합을 Element별로 더한다.
3) 대칭적 구조
Hourglass 모듈은 대칭적이기 때문에 내려가는(해상도가 작아지는) Layer에 대응되는 올라가는 Layer가 존재한다.
4) 최종 출력
네트워크의 Output 해상도에 도달했다면, 두번의 연속적인 1x1 Convolution을 적용하여 최종 예측을 생성한다. 네트워크의 출력은 Heatmap Set으로 하나의 Heatmap은 하나의 관절에 대한 픽셀별 존재 확률을 의미한다.
3.2. Layer Implementation

네트워크의 큰 틀은 Hourglass를 유지하면서 세부적인 Layer의 구성은 유연하게 바꿀 수 있었다. 따라서 본 논문에서는 여러 Layer 디자인 옵션을 탐구하였는데, 특히 해당 시기에 인기있었던 Residual Block이나 Inception(5x5 필터-> 3x3 필터2개) 기반의 테스트를 진행하였다.
그 결과 가장 성능이 좋았던 방법이 Residual 모듈을 광범위하게 사용하고, 3x3보다 큰 필터는 사용하지 않는 것이었다. 네트워크에 사용한 모듈은 Figure 4에 나타나 있으며 Figure 3에 나타나있는 각 상자는 단일 Residual 모듈을 나타낸다. 전체 네트워크는 Stride 2를 가진 7x7 Convolution Layer로 시작하며 Maxpooling으로 해상도를 256에서 64로 줄인다. Figure 3에 나타나는 Hourglass 전에 2개의 Residual 모듈이 추가로 적용되며 Hourglass 전체에서 모든 Residual 모듈은 256개의 Feature를 출력한다.
3.3. Stacked Hourglass with Intermediate Supervision
네트워크 아키텍처를 발전시키기 위해 여러개의 Hourglass 모듈을 쌓아 하나의 Hourglass의 출력이 다음 모듈의 Input으로 사용되도록 설계하였다. 이를 통해 반복적인 Bottom-Up, Top-Down Inference 매커니즘이 작동하여 초기 추정치와 이미지 전체의 특징을 여러번 평가할 수 있게 만든다. 이 방법의 핵심은 중간 단계(Intermediate)의 Heatmap 예측을 기반으로 Loss를 적용할 수 있다는 점이다.
하나의 Hourglass 모듈을 통과하면 예측이 생성되기 때문에 이 때마다 네트워크는 지역적이고 전역적인 Context에서 Feature를 처리할 수 있는 기회를 얻게 된다. 또한 네트워크가 진행되며 더욱 고차원적인 Feature를 처리하여 더 높은 수준의 Spatial Relationship을 평가할 수 있다.
Hourglass 모듈을 1개만 사용한다면 초기 예측을 생성하기 위해 Upsampling이 끝난 후 Supervision을 받아야 하는데 이 경우 더 큰 전역적인 Context에서 Feature들끼리 평가를 진행하기 어렵다. 또한 그렇다고 Pooling 이전에 Supervision을 제공할 경우 아직 전역적인 Context를 알지 못한 상태여서 좋지 못하다. 따라서 지역적인 정보, 전역적인 정보가 모두 중요하기 때문에 이러한 문제를 완화할 수 있도록 본 논문에서는 Bottom-Up, Top-Down 방법을 반복적으로 사용하였다.
Bottom-Up, Top-Down을 반복적으로 사용하여 각 Hourglass 모듈 내에서 지역적, 전역적 정보들을 통합시킬 수 있고 예측을 생성할 수 있다. 또한 Figure 4에서 볼 수 있듯이 Intermediate Prediction을 추가적인 1x1 Convolution을 통해 더 많은 Channel 수로 매핑한 후 Feature Space에 통합한다. 이러한 Prediction은 이전 Hourglass의 출력 Feature와 함께 Hourglass의 Intermediate Feature에 추가되어 다음 Hourglass의 Input으로 사용된다.
전체 네트워크에는 8개의 Hourglass가 사용되며 Hourglass 간에는 가중치가 공유되지 않고 각 Hourglass의 예측은 동일한 Ground Truth 와의 Loss 계산이 이루어진다.
3.4. Training Details
본 논문에서는 FLIC과 MPII Human Pose 데이터 셋을 실험에 활용하였다. FLIC은 5003개의 이미지, MPII Human Pose는 약 25000장의 이미지를 가지며 MPII의 경우 테스트 Annotation이 제공되지 않기 때문에 일부 학습 이미지를 가지고 학습을 진행하고 3000개의 이미지를 홀드아웃 검증 세트로 평가한다.
구체적인 데이터 셋 Preprocessing 방법이나 디테일한 학습 방법에 대해서는 논문을 참고.
4. Results
4.1. Evaluation
평가에는 PCK(Percentage of Correct Keypoints) Metric을 사용하였다. PCK는 탐지된 관절이 Ground Truth로부터 정규화된 거리 내에 포함되는 비율을 나타낸다. FLIC 데이터 셋에서는 상체 기준으로 정규화가 이루어지고, MPII 데이터 셋에서는 머리 크기의 일부로 정규화가 이루어진다.

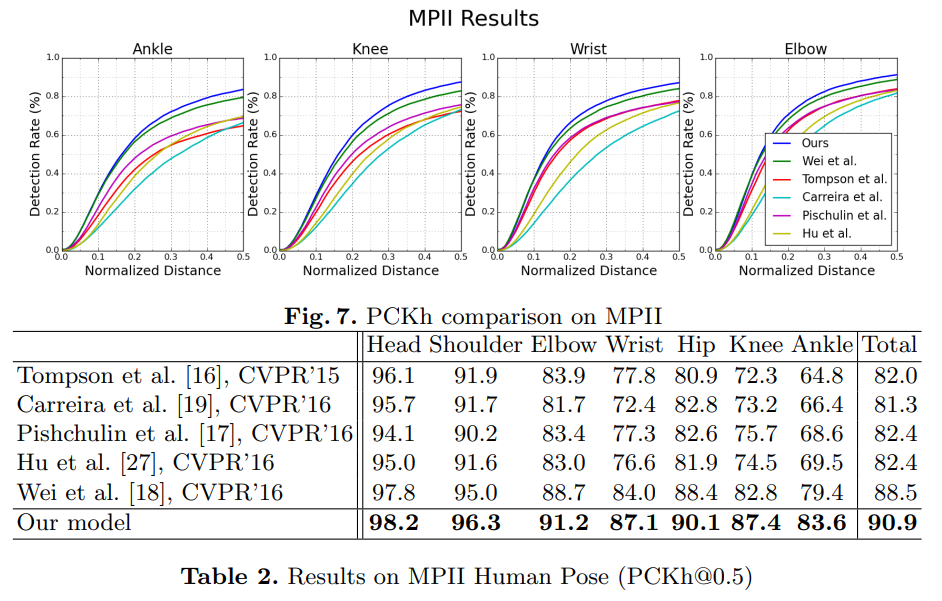
위에서 볼 수 있듯이 Stacked Hourglass 모델은 FLIC와 MPII 데이터 셋에서 모두 좋은 성능을 보였다.
4.2. Ablation Experiments
본 논문에서 제안하는 모델 디자인의 주요한 점은 (1) Hourglass 모듈을 여러개 쌓는 것과 (2) Intermediate Supervision의 영향력이다.
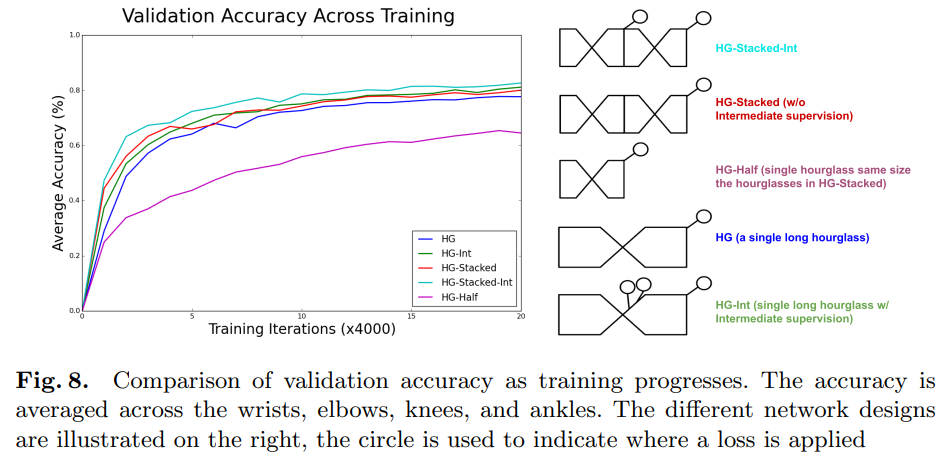
중요한 2가지를 가지고 Ablation Study를 진행한 결과 Hourglass를 쌓고 Intermediate Supervision을 적용하였을 때의 성능이 가장 좋은 것을 확인할 수 있다.
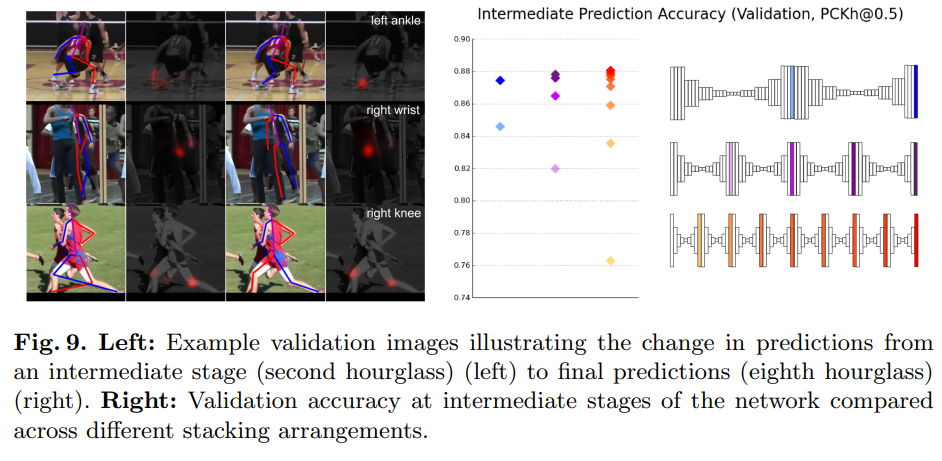
Figure 9를 보면 Stack을 2개 쌓을 때, 4개 쌓을 때, 8개 쌓을 때에 성능 향상을 확인할 수 있으며 Stack이 많을 수록 중간 단계의 오류를 나중에 수정하여 더 좋은 성능을 보이는 것을 알 수 있다.
Stacked Hourglass 모델의 핵심적인 부분은 Bottom-Up과 Top-Down을 여러번 반복하여 전역적이고 지역적인 정보를 잘 통합하여 Pose Estimation을 수행했다는 점이다. 전체적인 구조로는 Residual Block과 Inception의 3x3 Kernel이 사용되었으며 여러개의 Hourglass 모듈을 활용하여 Intermediate Heatmap을 Supervision에 사용하였다.
세 줄 요약
1. 높고 낮은 수준의 특징을 모두 파악하기 위한 Bottom-Up, Top-Down 접근을 반복하는 Stacked Hourglass 모듈을 제안하였다.
2. 모든 해상도에서의 정보를 보존하고 지역적, 전역적인 정보를 활용하기 위해 Residual Block, Intermediate Supervision 기법을 사용하였다.
3. 실험을 통해 Hourglass 모듈을 여러겹 쌓는 것, Intermediate Supervision의 효과를 입증하였고 FLIC, MPII 데이터 셋이서 좋은 성능을 보였다.
