[Paper Review] Stable Diffusion 논문 이해하기
『High-Resolution Image Synthesis with Latent Diffusion Models. CVPR. 2022. 』
이번에 정리할 논문은 Stable Diffusion이다. Stable Diffusion 모델이 공개된 후 생성 모델에 대한 대중적인 관심도가 급속도로 높아졌으며 지금은 LLM에 대한 관심도에 살짝 밀린 감이 있지만, 생성 이미지를 만들어내는 Task에 큰 기여를 한 모델이다.
실제로 HuggingFace 라이브러리를 활용해 모델을 사용해보면 원하는 이미지가 잘 만들어지는 것을 확인할 수 있고 이후 후속 연구들 또한 많이 등장하고 있다.

Github
https://github.com/CompVis/stable-diffusion
GitHub - CompVis/stable-diffusion: A latent text-to-image diffusion model
A latent text-to-image diffusion model. Contribute to CompVis/stable-diffusion development by creating an account on GitHub.
github.com
0. Abstract
기존에 존재하던 Diffusion 모델들은 pixel 단위에서 작동하기 때문에 GPU 소요량이 엄청나게 많았다. 이러한 단점을 극복하기 위해 본 연구에서는 VAE에 나온 Latent Space 개념을 활용하였다. 이를 통해 Complexity를 감소시키고 디테일한 정보를 보존하였다.
👉 Pixel이 아닌 Latent Space에서 Diffusion Process를 작동하여 Complexity를 감소시키고 연산량을 줄임.
1. Introduction
본 논문에서는 Diffusion 모델을 설명하기 전 이전까지 생성 모델 Task에서 인기있었던 GAN 모델에 대해 먼저 이야기한다. 특히 GAN 모델이 가지고 있던 문제점에 대해 이야기 하며 Diffusion 기반의 모델이기에 기존에 GAN 모델이 가지고 있던 Mode Collapse나 Training instability와 같은 문제가 발생하지 않는다는 점을 이야기한다.
[GAN 모델의 문제점에 대해서는 다음의 링크를 참고]
Democratizing High-Resolution Image Synthesis

본 연구에서는 Latent Space를 사용하여 기존 Diffusion 모델이 가지는 많은 계산량 문제를 극복하였다. Diffusion 모델은 Likelihood 기반의 모델이기에 Perceptual Compression을 찾는 단계와 실제로 생성 모델이 데이터의 Semantic, Conceptual Composition 정보를 학습하는 단계로 나뉜다. 본 연구에서는 지각적으로 명확하면서 계산이 쉬운 Space를 찾고 싶어했다.
여기서 말하는 Perceptual 정보와 Semantic 정보는 각각 Low-level, High-level 정보로 이해할 수 있다. Perceptual 정보란 말 그대로 지각적인 정보를 뜻하며 우리가 이미지에서 쉽게 찾을 수 있는 색상, 명암 등을 의미하며 우리가 한눈에 알아차릴 수 있는 정보이기에 Low-level로 볼 수 있다. 한편 Semantic 정보는 추상적인 개념이 포함되어 유사성 등을 의미한다. 예를 들어 종이 다른 두 고양이 이미지를 보았을 때, 고양이의 색상이나 생김새가 다르다 해도 우리는 두 이미지가 모두 고양이임을 알 수 있다. 그렇기에 Semantic 정보는 High-level의 정보로 이해할 수 있다.
그렇기에 본 연구에서는 저차원의 Latent Space를 제공하는 AutoEncoder를 학습하였다. 여기서의 Latent Space는 Perceptually Equivalent하며 학습된 Latent Space에서 Diffusion을 수행하기 때문에 많은 Spatial Compression이 필요하지 않다(효율적). 또한 전체적인 AutoEncoder를 한번만 학습하고 여러 Diffusion 모델 학습에 대해 해당 Latent Space를 다시 활용할 수도 있다는 장점을 가진다.
이러한 모델을 Latent Diffusion Model(LDM)이라고 이름 붙였으며 나중을 위해 Transformer를 Diffusion 모델 U-Net의 backbone으로 사용할 수 있게 아키텍처를 구상하였다.
본 연구에서 정리한 Contribution은 다음과 같다.
- 전체적인 구조를 모두 Transformer로 구성한 모델들과 달리 고차원의 데이터에 대해서도 잘 적용된다.
- Unconditional Image Synthesis, Inpainting, Stochastic Super-Resolution 등 여러 Task에서 좋은 성능을 냈다.
- Score-based 모델과는 다르게 Reconstruction에 대한 Delicate Weighting이나 Generative Ability가 필요하지 않다.
- 1024x1024 pixel을 가지는 큰 이미지에 적용할 수 있다.
2. Related Work
Generative Models for Image Synthesis
앞서서 설명한대로 GAN 모델은 최적화 수렴이 어렵고 Full Data Distribution을 포착하기 어렵다. 반대로 Likelihood-based 방법들은 좋은 Density Estimation을 가지는데 대표적인 방법인 VAE와 Flow-based 모델들은 효율적으로 고해상도 이미지 합성이 가능하다. 본 연구에서는 이러한 장단점을 고려하여 계산량이 적고 Inference 속도는 빠르지만 합성 품질이 감소하지 않는 LDM 모델을 만들고자 하였다.
Two-Stage Image Synthesis
최근 2-Stage 모델 구조로의 접근 방식이 많이 제안되었다.
- VQ-VAE
- 이전 Latent Space를 충분히 학습시키기 위해 AutoRegressive model을 사용함
- VQ-GAN
- AutoRegressive Transformers를 큰 이미지에 적용시키기 위해 Adversarial & Perceptual Objective를 첫번째 단계에 사용하였다.
이런 모델들의 경우 Encoder와 Decoder를 (1) 같이 학습하거나 (2) 따로 학습하게 되는데, 같이 학습하는 경우 Reconstruction과 Generative Capability 사이에 Weighting이 필요하기 때문에 따로 학습하는 방식이 주목받고 있다고 한다.
3. Method
Diffusion 모델은 고해상도 이미지 처리를 위해 관련없는 사항들을 무시하도록 설계되었다. 그럼에도 아직까지 많은 계산량을 자랑하고 있는데, 이러한 결점을 극복하기 위해 본 연구에서는 학습 단계에서 Compressive(압축 정보)를 명시적으로 분리해준다. 이러한 접근 방법에는 아래와 같은 장점이 존재한다.
- Efficient : 저차원 공간에서 샘플링이 이루어진다.
- High Inductive Bias : U-Net 구조를 사용하여 Compression이 잘 이루어지기 때문에 높은 Inductive Bias를 가진다.
[Inductive Bias에 대한 설명은 링크를 참고] - General-Purpose : Latent Space를 사용하여 한번의 학습으로 만들어진 Compression Model을 여러 Downstream task에 활용할 수 있다.
3.1. Perceptual Image Compression
여기서 말하는 Perceptual Compression이란 우리가 일반적으로 알고 있는 Autoencoder에서 Latent space를 학습하는 것을 말한다. 이 때 Latent Space의 분산이 크면 Latent Space가 가지고 있는 정보가 이질적이므로 작은 분산을 가지도록 Regularization을 가지고 실험을 진행하였다.
Regularization의 종류
- KL-reg : 학습된 Latent에 약간의 KL-penalty를 줌
- VQ-reg : Decoder안에 Vector Quantization을 사용함
본 연구에서 사용한 Diffusion 모델은 Latent Space를 2차원 구조로 설계하여 Latent Space가 1차원인 모델보다 Compression과 Reconstruction 성능이 좋았다.
3.2. Latent Diffusion Models
Diffusion Model은 점진적으로 Denoising을 해가며 $p(x)$의 데이터 분포를 학습하도록 디자인된 확률 모델이다(고정된 길이의 Marcov Chain reverse process 학습). 이미지 합성에서 성능이 좋은 대부분의 모델들은 $p(x)$에 대한 ELBO(변분 하한;Variational Lower Bound)를 재가중치하여 변형하여 사용하였으며 이는 Denoising score-matching과 유사하다. 결국 이 모델들은 동일한 가중치를 가지는 Denoising AutoEncoder의 시퀀스로 해석될 수 있으며 이는 $\epsilon_{\theta}(x_t, t)$로 표현된다. 해당 목적함수는 다음과 같다.
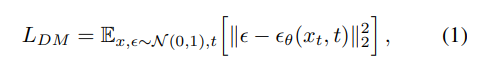
여기서 $x_t$는 Input x의 noise가 추가된 버전이다.
Generative Modeling of Latent Representations
학습된 Perceptual Compression 모델을 사용하면 눈에 띄지 않는 디테일들이 효율적이고 저차원인 Latent Space에 접근할 수 있다. 고차원인 Pixel Space와 대비하여 Latent Space를 사용하는 것은 (1) 데이터의 중요하고 Semantic한 정보에 더 초점을 맞출 수 있으며, (2) 저차원에서 학습을 진행하기 때문에 계산이 더 효율적이라는 장점을 가진다.
이러한 구조는 Time-conditional U-Net을 Backbone으로 사용하여 기존 AutoRegressive나 Attention-based Transformer 구조보다 더 풍부한 Inductive Bias를 가지게 만든다.

3.3. Conditioning Mechanisms
본 연구에서는 U-Net Backnone과 Cross-Attention 매커니즘을 활용하여 Diffusion Model을 더 유연하게 조건을 줄 수 있는 Generator로 만들었다.

도메인 별로 조건을 줄 수 있는 $\tau_{\theta}$를 사용하였고, 이미지-조건 쌍에 기반하여 아래의 목적함수가 만들어진다.

4. Experiments



Stable Diffusion 모델은 기존 Diffusion 모델, 생성 모델들 대비 좋은 성능을 내었으며 여러 Task에서 좋은 성능을 보였다.
- 고해상도 이미지 생성에 더 적은 자원과 시간
- 여러 조건, 데이터 셋에 대한 모델 유연성 평가
5. Limitations & Societal Impact
Limitations
- Latent Space 기반의 방법을 사용하여 Pixel 기반 방법론 보다는 빠르지만 Sampling Process가 아직 GAN보다 느리다.
- LDM모델은 높은 Precision이 요구되는 작업에서 적합하지 않을 수 있다.
Societal Impact
이미지 생성 Task에 있어 Train, Inference 비용을 절감하여 기술 접근성을 높임. 하지만, 그만큼 조작된 데이터를 쉽게 배포할 수 있다는 문제가 존재함. 또한 데이터에 대한 윤리적인 문제가 존재함
6. Conclusion
논문에서는 Latent Diffusion Models(LDMs)를 제안하며 Denoising Diffusion 모델의 학습과 Sampling 효율성을 크게 개선한 방법을 소개한다. 이 방법론과 Cross-Attention Conditioning 매커니즘을 기반으로 좋은 성능을 얻은 것을 보였다.
모델 진행 순서
1. Input이 VAE의 Encoder를 통과하여 Latent Vector를 생성
2. U-Net을 N번 반복. Latent Vector에서 noise를 주며 DDPM의 방법론을 활용하여 학습(Diffusion Process)
3. U-Net의 결과로 만들어진 Vector를 가지고 VAE의 Decoder를 통과하여 이미지를 생성
세 줄 요약
1. 기존에 존재하는 생성 모델(GAN/Diffusion)들은 각각 학습이 잘 이루어지지 않는 문제나 계산량이 많다는 문제점을 가짐
2. 본 논문에서는 Latent Space에서 Noise를 주고 이를 복원하는 과정을 학습하는 방법론(+Cross Attention)을 활용(이미지 원본에 Noise를 주고 이를 그대로 복원하는 과정을 학습하는 방법론은 DDPM에서 제안)
3. 좋은 퀄리티의 생성 이미지를 적은 계산량으로 만들 수 있는 Latent Diffusion Model을 제안하며 여러 Task에서 높은 성능을 보임
