[X:AI] DINO 논문 이해하기
『 Emerging Properties in Self-Supervised Vision Transformers. ICCV. 2021 』
DINO(Self-Distilation with no Labels)는 Facebook에서 발표한 Self-Supervised Learning 논문이다.
0. Abstract
본 논문은 ViT(Vision Transformer)에 Self-Supervised Learning을 적용하여 그 효과를 확인하였다. 이 때 단순히 성능이 높을뿐만 아니라 두가지 이점이 존재한다.
- Self-Supervised ViT는 이미지의 Semantic Segmentation에 대한 명시적인 정보를 담고있다. (이는 Supervised ViT나 Convolution Network에서 나타나지 않음)
- Self-Supervised ViT의 Feature들은 K-NN Classifier를 사용할 때 우수한 성능을 보이며 ImageNet에서 78.3% Top-1 Accuracy를 달성했다.
이러한 Self-Supervised 방법을 DINO라고 칭하며 ViT-Base에 DINO를 결합한 방법으로 좋은 시너지를 낼 수 있었다.
※Self-Supervised Learning
https://sanghyu.tistory.com/184
Self-supervised learning (자기지도학습)과 Contrastive learning (대조학습): 개념과 방법론 톺아보기
** 본 포스팅은 NeurIPS2021의 self-supervised learning 튜토리얼에 필자의 소소한 설명을 덧붙인 글입니다. Supervision을 위한 대량의 labelled data 특히 high-quality의 labelled data를 얻는 것은 비용이 많이 든다. u
sanghyu.tistory.com
1. Introduction

최근 Transformer는 컴퓨터 비전 태스크에서 Convolution Network의 대안으로 부상하였다. ViT로 대표되는 이 방법은 많은 데이터를 사용한 Pretrain, Fine Tuning 방법과 엮어져 어느정도의 성능을 내었지만, 아직 Convolution에 비해 명확한 이점을 제시하지 못하였다.
본 논문에서는 NLP의 성공을 BERT와 GPT에서 사용한 Self-Supervised Pretraining이라고 이야기 한다. 이 방법을 통해 더 풍부한 Learning Signal을 전달할 수 있었고 이러한 방법에서 영감을 받아 본 연구에서는 Self-Supervised Pretraining이 ViT에 미치는 영향을 분석한다. 그 결과 흥미로운 2가지 특징을 찾을 수 있었고 이는 초록에 적어둔 특징과 같다.
본 연구에서 발견한 이러한 특징은 레이블이 없는 Knowledge Distillation의 한 형태로 해석될 수 있는 간단한 Self-Supervised 방법으로 설계하도록 만들었다. 그 결과 DINO라는 프레임워크를 만들었고 표준 Cross Entropy Loss를 활용하여 Momentum Encoder로 만들어진 Teacher Network의 출력을 직접 예측하도록 Self-Supervised Training을 단순화하였다.
※ Knowledge Distillation
: Pretrained 된 큰 모델(Teacher)을 활용하여 작은 모델(Student)에서도 큰 모델과 비슷한 성능을 낼 수 있도록 지식을 전달하는 방법
https://light-tree.tistory.com/196
딥러닝 용어 정리, Knowledge distillation 설명과 이해
이 글은 제가 공부한 내용을 정리하는 글입니다. 따라서 잘못된 내용이 있을 수도 있습니다. 잘못된 내용을 발견하신다면 리플로 알려주시길 부탁드립니다. 감사합니다. Knowledge distillation 이란?
light-tree.tistory.com
또한 DINO Framework는 유연하기 때문에 아키텍처를 수정하거나 내부 정규화를 수정할 필요 없이 Convolution Network와 ViT 모두 작동한다. ImageNet Benchmark를 통해 DINO와 ViT간의 시너지를 검증하였고 최신 Convolution Network와도 함께 작동하여 그 여부를 확인하였다.
2. Related Work
Self-Supervised Learning
: 본 논문에서는 BYOL의 방법론을 사용하지만, Loss가 다르고 동일한 구조의 Teacher, Student Network를 사용한다는 점의 차이가 있다.
Self-Training and Knowledge Distillation
: 이전에 Self-Supervised Learning과 Knowledge Distillation 방법을 결합한 연구가 많지만, 본 논문에서는 Pretrain된 Teacher Network를 사용하지 않는다는 차이가 있다.
3. Approach
3.1. SSL with Knowledge Distillation
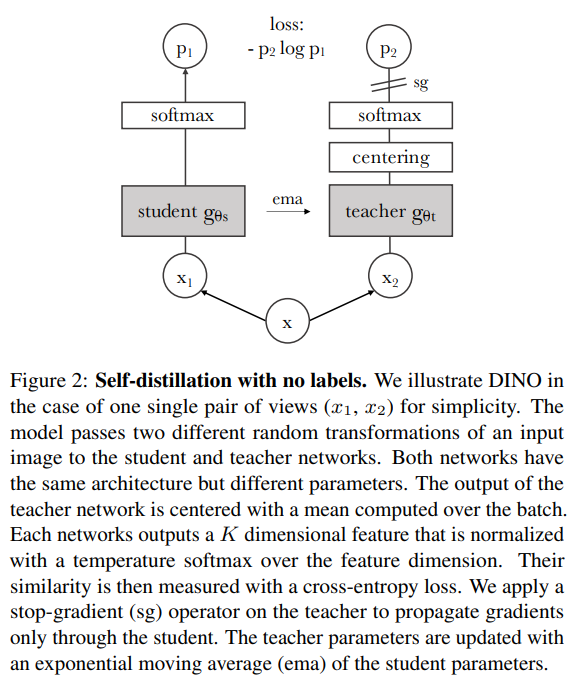
DINO의 전체 구조를 살펴보면 Self-Supervised로 이루어져 있으며 Knowledge Distillation의 형태를 띈다. Figure 2에서 볼 수 있듯이 Student Network를 학습할 때 그 output을 Teacher Network의 output과 일치시킨다.
1. 이미지가 주어졌을 때 Teacher, Student Network 모두 $K$차원의 확률 분포 $P_s$와 $P_t$를 출력한다. 이 때 확률 분포는 네트워크 $g$의 출력을 softmax function으로 정규화하여 얻어낸다.
(여기서 $\tau$는 Temperature Parameter로 출력 분포의 첨도를 조절한다.)
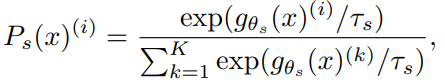
2. 두 확률 분포의 Cross Entropy Loss를 최소화 하여 두 신경망의 출력 분포를 일치 시킨다. 성능이 좋은 Teacher Network의 결과를 Student가 사용할 수 있도록!!
(여기서 $H(a, b) = -alogb$)
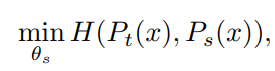
3. Self-Supervised Learning에 적용하는 부분. 우선 Multi-Crop Strategy(이후 설명)을 활용하여 다양한 이미지 셋 $V$를 만든다. 이 때 Local View와 Global View를 포함하고 아래와 같은 Loss를 최소화한다.
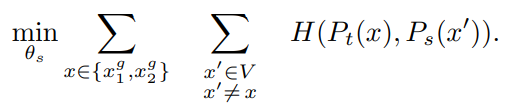

Pytorch Pseudo Code는 위와 같고 이미지에 각각 다른 Augmentation을 적용하고 Loss로는 Cross Entropy를 사용한다.
Teacher network
DINO는 Knowledge Distillation과 다르게 Pretrain을 통해 Teacher Network를 가지지 않는다. 따라서 Iteration의 구성을 Student Network 이전으로 구성하였고, 여러 업데이트 규칙을 실험해본 결과 Student의 가중치에 EMA 방식을 사용하는 Momentum Encoder가 좋았다고 한다.
※ EMA(Exponentially Weighted Averages, 지수 가중 평균)
: 데이터의 이동 평균을 구할 때 오래된 데이터가 미치는 영향을 지수적으로 감쇠하도록 만들어주는 방법
Network architecture
Network $g$는 ResNet Backbone인 $f$와 Projection Head인 $h$로 이루어져 있다. Projection Head에는 3개의 MLP Layer, L2 Norm이 적용되었다. ViT에 DINO를 적용할 때에는 Projection Head에서 BatchNorm을 제거하여 사용하였다.
Avoiding collapse
Self-Supervised를 사용한 방법마다 Contrastive Loss(InfoNCE), Clustering Constraints(SwAV), predictor(BYOL), Batch Norm 등 다양한 방법으로 Collapse를 피하려고 한다. DINO든 대신 Teacher Network에 대한 Centering, Sharpening 만으로 Collapse를 피했다.
※ Collapse
: 모든 입력에 대해 동일한 Embedding을 출력하는 현상. 본 논문에서는 Teacher Network와 Student Network가 균형있게 학습되지 못하는 것을 의미한다. (Collapse가 일어나면 계속해서 같은 결과만을 출력)
※ Centering
영상을 처리할 때 모든 값에서 중간 값을 빼는 것으로 이 경우에는 중간 값을 중심으로 값들이 설명된다. 예를들어 [1, 2, 3, 4, 5] 라면 Centering을 수행하고나면 [-2, -1, 0, 1, 2] 가 된다.
※ Sharpening
영상 처리에서 영상의 선명도를 향상시키는 과정. Frequency가 높은 영상의 경계부분을 강화하거나 강조하는 작업을 통해 영상의 경계와 선이 더 뚜렷해진다.
$$ g_t(x) \leftarrow g_t(x) + c$$
Centering을 수행하면 한 차원(Batch를 의미하는 듯..?)이 지배하는 것을 방지할 수 있지만, 균일한 분포가 만들어 질 수 있어 Sharpening을 같이 사용한다. 여기서 Sharpening은 Centering과 반대의 효과를 얻는다. Centering을 사용하여 Batch에 대한 의존도를 낮추는 과정은 위의 식과 같이Teacher Network에 bias 항을 추가하는 것으로 해석할 수 있다.
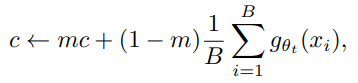
C는 EMA 방식으로 업데이트 되며 Batch size가 다르더라도 잘 적용된다. 또한 Sharpening 과정은 Teacher Softmax Normalization의 $\tau_t$를 낮은 값으로 두어 진행할 수 있다.
$m$ : rate parameter (>0)
$B$ : Batch size
3.2. Implementation and evaluation protocols
Vision Transformer
본 논문에서는 DeiT의 Implementation(구현)을 사용하였다.
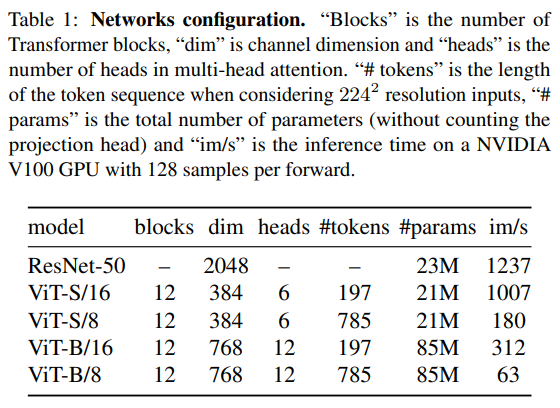
Implementation details
실험 구현에 대한 내용으로 자세한 내용은 논문을 참고
Evaluation protocols
사용한 Augmentation, Evaluation과 관련된 내용 기술. 자세한 내용은 논문을 참고
4. Main Results
4.1. Comparing with SSL frameworks on ImageNet
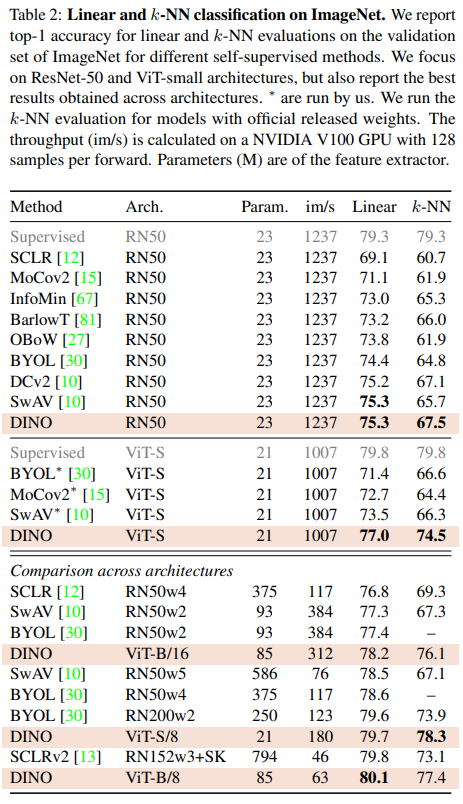
ImageNet에 대해 다양한 Self-Supervised 방법을 비교. 여러 Architecture에서 DINO의 성능을 비교하였는데 ResNet에서는 근소한 차이로 좋은 성능을 보였지만 ViT 방법에서는 다른 방법보다 좋은 성능을 보였다.
4. 2. Properties of ViT trained with SSL
4.2.1. Nearest neighbor retrieval with DINO ViT
Image Retrieval
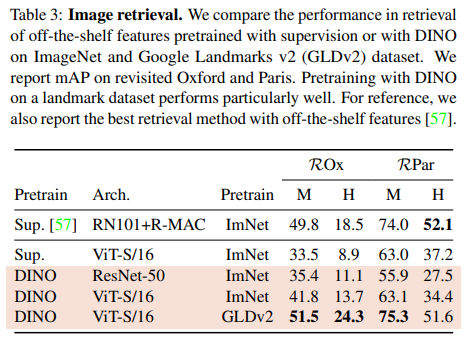
Copy detection
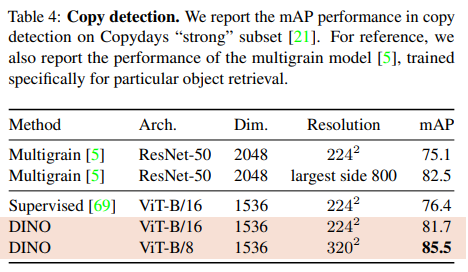
두 Task에서 모두 기존 방법들보다 좋은 성능을 보였다.
4.2.2. Discovering the semantic layout of scenes
Video instance segmentation
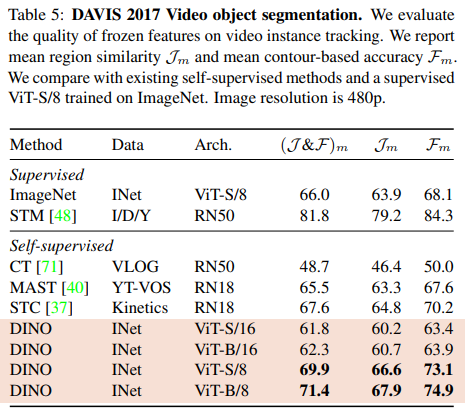
Probing the self-attention map


서로 다른 Semantic Region을 잘 파악하고 있고 Supervised 방식보다 DINO 방식의 Attention이 더 잘 작동하는 것을 확인할 수 있다.
4.2.3. Transfer learning on downstream tasks
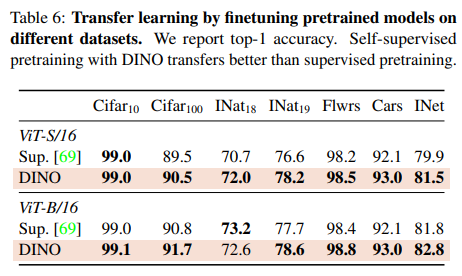
5. Ablation Study of DINO
5.1. Importance of the Different Component
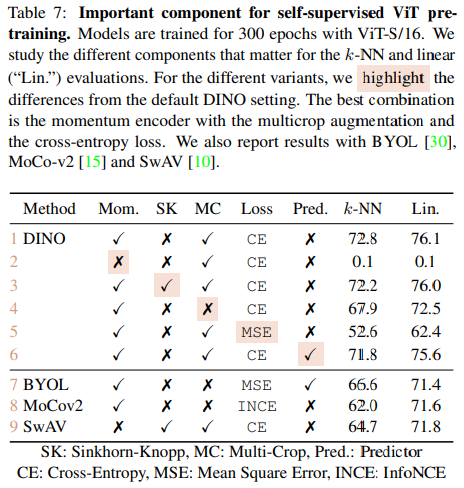
- Momentum이 없을 때 아예 Framework가 동작하지 않고 Sinkhorn-Knopp(SwAV에서 사용된 알고리즘)은 Collapse를 피하기 위해 필요하지만, Momentum과 같이 쓸 경우 효과가 낮음.
- Multi-Crop과 Cross Entropy가 성능 향상에 중요한 것을 확인하였다. (Line 4, 5)
- BYOL에서는 Student Network에 Predictor를 추가하는 것이 중요했지만, DINO에서는 중요하지 않음 (Line 6)
Importance of the patch size
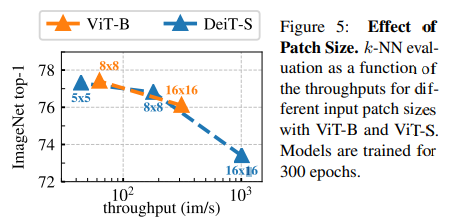
Patch Size에 따른 K-NN 성능. Patch Size가 작아질 수록 성능이 크게 향상된다.
5.2. Impact of the choice of Teacher Network
Building different teachers from the student

Analyzing the training dynamic
Figure 6의 왼쪽 그림은 DINO에서 Momentum Teacher Network 성능이 왜 좋았는지 Dynamic Graph를 그려본 것인데, 학습하는 동안 Teacher Network의 성능이 Student Network의 성능보다 좋은 것을확인할 수 있었다. Polyak-Ruppert Averaging with Exponential Decay를 사용해서 그렇다고 해석함.
5.3. Avoiding collapse
Collapse에는 2가지 종류가 있다. 첫 번째는 모든 결과가 Uniform한 것, 두 번째는 하나의 결과로만 출력되는 것. 따라서 Entropy를 증가시키는 Centering과 그 반대의 효과를 가지는 Sharpening을 같이 사용한다.
Centering을 쓰면 Entropy가 증가할까?
: Entropy는 확률 분포의 불확실성을 측정하는 척도로 확률 분포가 Uniform할 때 최대가 된다. Centering을 적용하면 확률 분포의 중심이 이동하게 되는데 이 때 데이터의 분포가 평균 주위에 뭉쳐지게 되어 Entropy가 높아진다. 반면 [1, 2, 3, 4, 100] 과 같이 애초에 치우쳐 있는 확률 분포의 경우에는 Centering을 적용하더라도 [-2, -1, 0, 1, 97] 로 평균 주위에 뭉쳐지지 않기 때문에 Entropy가 감소한다.
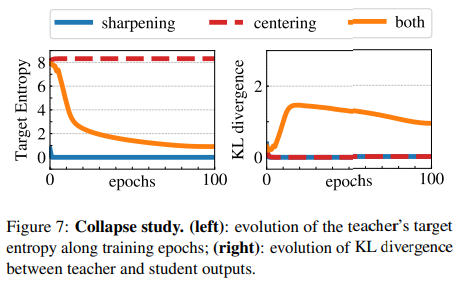
Sharpening과 Centering 중 하나만 쓸 경우는 모두 KL Divergence 값이 0으로 Collapse (오른쪽 그림)
5.4. Compute requirements
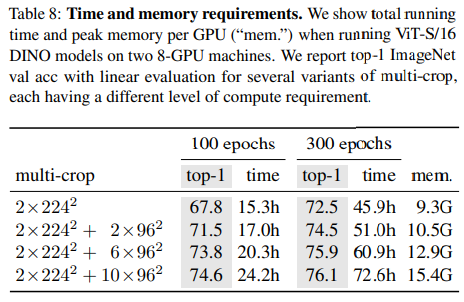
Multi-Crop에 따라 Accuracy는 높아지지만, 시간도 오래 걸림
5.5. Training with small batches
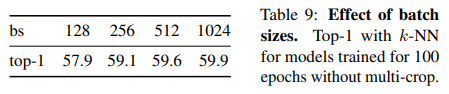
Batch Size가 작을수록 좋았다.
6. Conclusion
본 논문에서는 ViT 모델에 Self-Supervised Pretrain 기법을 적용하여 현재 성능이 좋은 Convolution 기법과도 비슷한 성능을 낼 수 있는 가능성을 확인하였다. 이 때 K-NN Classifier를 사용하여 그 잠재력을 확인하였으며, Self-Supervised Learning 기법을 통해 ViT를 기반으로 BERT와 같은 모델을 추후에 개발할 수 있을 것이라고 말한다.
<참고자료>
Emerging Properties in Self-Supervised Vision Transformers (DINO) 논문 해석
arXiv:2104.14294v2 [cs.CV] 24 May 2021 0. Abstract 본 논문은 "Vision Transformer(ViT)에 self-supervised learning를 적용하여 CNN에 버금가는 새로운 properties를 추출할 수 있을까?"라는 가설을 검증하고자 함. self-supervised
sysyn.tistory.com
https://kimjy99.github.io/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0/dino/
[논문리뷰] Emerging Properties in Self-Supervised Vision Transformers (DINO)
DINO 논문 리뷰
kimjy99.github.io
세 줄 요약
1. ViT에 Self-Supervised Learning 기법을 적용한 DINO 제안
2. BYOL 방법론을 차용하여 SSL기법에 Knowledge Distillation 방법을 더해 성능을 높임
3. Collapse를 방지하는 Centering, Sharpening을 사용하였고 ViT가 Convolution 방법과 비슷한 성능을 낼 수 있는 가능성을 확인
