[X:AI] StarGAN 논문 이해하기
『 StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation. 2018. 』
StarGAN은 우리나라에서 나온 논문으로 다양한 Domain에 대해 Image-to-Image Translation을 사용할 수 있는 방법을 제안하였다. 이전에 제안된 모델들을 GAN - Conditional GAN - Pix2Pix - CycleGAN 순서로 이해한 뒤 공부를 하면 조금 더 편하게 이해할 수 있다.
https://github.com/yunjey/stargan
GitHub - yunjey/stargan: StarGAN - Official PyTorch Implementation (CVPR 2018)
StarGAN - Official PyTorch Implementation (CVPR 2018) - GitHub - yunjey/stargan: StarGAN - Official PyTorch Implementation (CVPR 2018)
github.com
0. Abstract
현재 Image-to-Image Translation 분야에서는 2가지 도메인에 대해 놀라운 성과를 보여주었지만, 아직까지 모든 이미지 도메인 Pair에 대해 서로 다른 모델을 독립적으로 구축해야한다는 단점이 있다. 이러한 모델 구조는 여러 도메인을 처리하는데 있어 Scalability와 Robustness를 제한한다.
따라서 본 논문에서는 여러 도메인에 대해 Image-to-Image Translation을 수행할 수 있는 Novel하고 Scalability한 StarGAN 모델을 제안한다. StarGAN 모델을 통해 단일 네트워크 내에서 서로 다른 도메인을 가진 여러 데이터 셋을 동시에 학습시킬 수 있다.
결국 StarGAN은 기존 모델에 비해 Translated Image의 품질을 향상시키고 입력 이미지를 원하는 타겟 도메인으로 유연하게 변환할 수 있다. (Ex. Facial Attribute Transfer, Facial Expression Synthesis)
1. Introduction

Figure 1의 첫 5 column은 RaFD 데이터 셋으로 학습한 모델을 CelebA 데이터 셋으로 Transfer Learning하여 CelebA 이미지가 'blond hair', 'gender', 'aged', 'pale skin' 4가지의 도메인에 따라 어떻게 Translation되는지를 보여준다.
Image-to-Image Translation은 주어진 이미지의 특정 측면을 다른 것으로 변환하는 것으로 GAN의 등장 이후 이와 관련된 분야는 상당히 발전되어 왔다. 지금까지 두 개의 서로 다른 도메인의 Training 데이터가 주어지면 모델은 한 도메인에서 다른 도메인으로 이미지를 Translation 하는 방법을 학습했다. (Ex. Pix2Pix, CycleGAN 등..)
※ 도메인(Domain)
같은 속성을 가지는 이미지 셋을 의미한다. 여기서 말하는 속성이란 머리 색, 성별 또는 나이와 같이 이미지 안에 내재되어 있는 의미있는 특징을 말하고, 속성은 속성의 특정 값으로 표현한다.
(Ex. 머리색은 검정/금발/갈색으로, 성별은 남성/여성으로 표현)
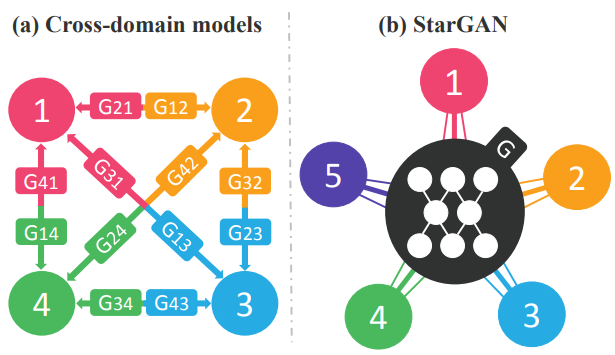
기존 Image-to-Image 모델들은 2가지 도메인에 대해서만 Translation이 가능했기 때문에 K개의 도메인 간의 모든 매핑을 학습하려면 K x (K-1)개의 Generator를 활용해야 해 매우 비효율적이었다. 예를 들어, 위 그림처럼 4개의 다른 도메인 간 Image Translation을 수행하기 위해 기존에는 12(4x3)개의 Generator를 활용해야 했다.
따라서 본 논문에서는 여러 도메인 간의 매핑을 학습할 수 있는 Novel하고 Scalable한 StarGAN을 제안한다. Figure 2 (b) 그림에서 볼 수 있듯이 이 모델은 여러 도메인의 학습 데이터를 가져와 하나의 Generator를 사용하여 사용 가능한 모든 도메인 간의 매핑을 학습한다.
여기에 사용된 아이디어는 기존에 모델이 [흑발 -> 금발]과 같이 고정된 Translation을 학습하는 대신 이미지와 도메인 정보를 모두 입력으로 사용하여 이미지를 해당 도메인으로 Translation하는 방법을 학습하는 것이다.
따라서 본 논문의 Contribution은 다음과 같다
- 하나의 Generator와 Discriminator를 사용하여 여러 도메인 간의 매핑을 학습하고 모든 도메인의 이미지에서 효과적으로 학습하는 새로운 StarGAN 모델을 제안
- 모든 도메인의 Label들을 control할 수 있도록 Mask Vector를 이용하여 여러 도메인 간의 Image Translation을 가능케 함
- Facial Attribute Transfer & Facial Expression Synthesis task에서 좋은 성능을 보임
2. Related Work
관련 연구로는 GAN, Conditional GAN, Image-to-Image Translation에 대한 설명을 소개하고 있다. GAN은 워낙 유명하기 때문에 다들 알 것이라고 가정하고 Conditional GAN과 Image-to-Image Translation의 대표 모델 들을 간단히 설명하고 넘어가겠다.
2.1. Conditional GAN
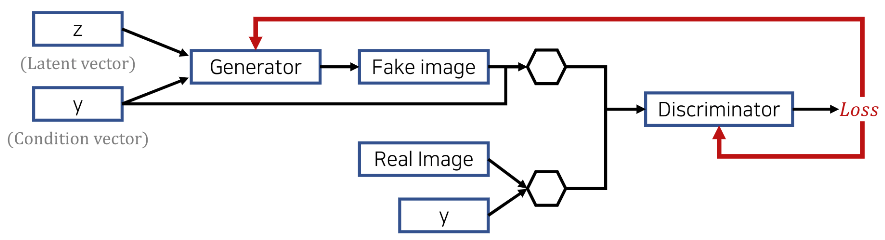
데이터를 내가 원하는대로 생성할 수 있도록 입력값을 줄 때 Condition을 같이 주는 방법이다.
Conditional GAN을 활용함으로Tj Latent Vector를 각 Label 마다 더 Discriminative하게 만들 수 있다.
이 때 들어가는 Condition vector y의 형태는 데이터의 형태에 따라 달라진다!
Latent Vector z가 vector 형태라면 y가 [1, 0, 0 ... ] 같이 one-hot-encoding 된 vector 형태로 들어가 z와 concat 되겠지만, 이미지 형태일 경우 이미지의 모든 픽셀 뒤에 해당 vector가 붙게 된다.
2.2. Image-to-Image Translation
pix2pix
입력 데이터와 함께 Condition을 같이 넣어주는 Conditional GAN의 아이디어를 가져와서 Condition 자체를 이미지로 넣어주자 아이디어를 제안한 모델이다.
서로 다른 두 도메인의 X, Y 데이터를 Pair로 묶어 학습을 진행하는데, 이 점이 Cost가 많이 드는 단점으로 꼽힌다.
CycleGAN
위와 같은 pix2pix 모델의 문제점을 해결하기 위해 CycleGAN이 등장하였다. CycleGAN에서는 Cycle Loss를 사용하여 두 도메인 간의 Translation시 Generator가 다시 원본 이미지로 Reconstruct 될 수 있도록 모델을 구성한다. 즉, 원본 이미지의 Structure 정보는 가져가면서 변하려는 도메인의 Translation만 이루어질 수 있도록 만드는 것이다.
하지만, CycleGAN은 이와 같은 성능 구현을 위해 2개의 Generator를 사용한다는 단점을 가진다.
3. Star Generative Adversarial Networks
3.1. Multi-Domain Image-to-Image Translation
StarGAN의 목표는 여러 도메인 간의 매핑을 학습하는 단일 Generator를 Train하는 것이다. 이를 위해 Generator가 입력 이미지 x와 해당 도메인의 Label c를 Conditional GAN처럼 학습하게 만든다. 또한, 하나의 Discriminator가 여러 도메인을 control 할 수 있도록 Auxiliary Classifier를 사용한다. (ACGAN 처럼)
즉, Discriminator는 원천 데이터와 도메인 Label에 대한 Probability Distribution을 생성한다.
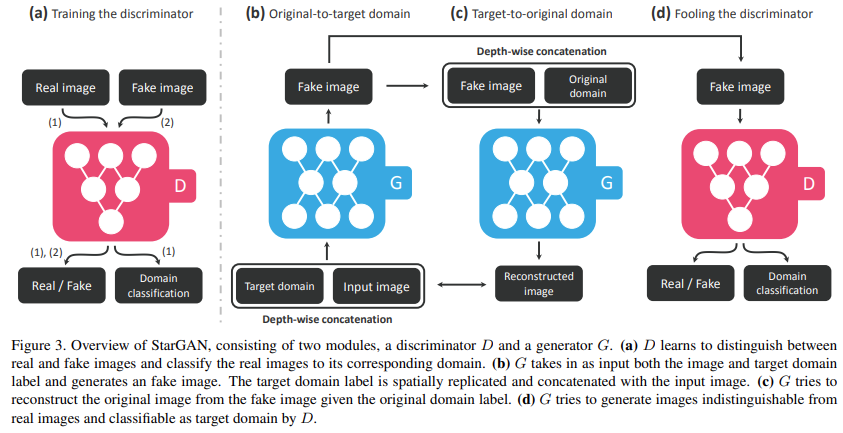
자세한 모델 개요는 위 그림과 같다.
(a) : Discriminator는 Real 이미지와 Fake 이미지를 구별하고, Real 이미지를 해당 도메인으로 분류하는 방법을 학습한다.
(b) : Generator는 이미지와 타겟 도메인 Label을 Input으로 받아 가짜 이미지를 만들고 타겟 도메인 Label은 공간적으로 복제되어 Input 이미지와 합쳐진다. 이 때 타겟 도메인의 Label은 다른 이미지를 Flexible하게 생성할 수 있도록 랜덤하게 생성한다.
(Conditional GAN의 Input에 이미지가 들어갈 때 각 픽셀마다 one-hot-encoding 된 vector가 붙는 것을 의미하는 거 같다!)
(c) : Generator는 Fake 이미지와 원본 도메인 Label이 합쳐진 값으로 원본 이미지를 Reconstruct하도록 노력한다.
(CycleGAN의 형태!!)
(d) : Generator는 Real 이미지와 구별할 수 없고 타겟 도메인으로 분류될 수 있는 Fake 이미지를 생성하려 한다.
Adversarial Loss
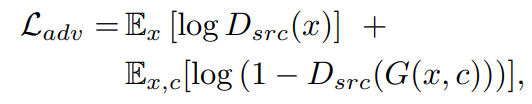
Generator는 위의 목적함수를 Minimize하는 방향으로, Discriminator는 Maximize하는 방향으로 학습을 진행한다. 타겟 도메인의 Label C만이 추가된 형태이다.
Domain Classification Loss
Input 이미지 x를 정답 도메인으로 잘 분류하는데 사용하는 Loss로 Generator, Discriminator에 따로 존재한다.
(1) Discriminator 학습시 (Real 이미지 x가 원래 도메인 $c'$로 분류)
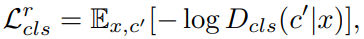
(2) Generator 학습시 (Generated 이미지가 타겟 도메인 $c$로 분류)

Reconstruction Loss
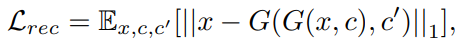
CycleGAN에서 사용한 Cycle Loss를 사용한다. CycleGAN과 다른점은 하나의 Generator를 사용한다는 것으로 특성을 변화시킬 때 원본 이미지의 특성을 최대한 유지하도록 한다. Metric으로는 L1 Norm을 사용하였다.
Full Objective
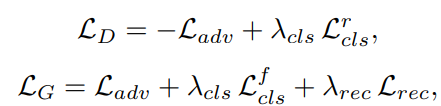
최종적인 목적함수는 다음과 같다. $\lambda_{cls}$와 $\lambda_{rec}$은 각각 Domain Classification Loss와 Reconstruction Loss의 상대적인 중요도를 의미한다.
본 논문의 실험에서는 $\lambda_{cls}$ = 1, $\lambda_{rec}$ = 10을 사용하였다. (CycleGAN과 유사)
3.2. Training with Multiple Datasets
StarGAN의 장점은 다른 유형의 Label을 포함하는 여러 데이터 셋을 동시에 통합하여 사용할 수 있다는 것이다. 여러 데이터 셋을 사용하면 당연히 성능이 좋아지지만, 특정 Label에 대한 정보는 일부 데이터 셋에만 존재하기 때문에 이미지를 복원하는 과정에서 문제가 생긴다.
예를 들어, CelebA는 머리색, 성별과 같은 외형적인 Attribute를 가지고 있고 RaFD는 행복, 화남과 같이 감정과 관련한 Attribute를 가지고 있어 해당 Label이 없는 Input 이미지를 복원하는데 문제가 생긴다.
Mask Vector
위와 같은 문제를 해결하기 위해 본 논문에서는 Mask Vector를 사용했다. Mask Vector는 StarGAN이 지정되지 않은 Label을 무시하고 특정 데이터 셋에서 제공하는 Label에 집중할 수 있도록 한다.
예를 들어, CelebA는 ["black", "blond", "man", "woman", "young"] attribute를 가지고, RaFD는 ["angry", "fearful", "happy", "sad", "disgusted"]를 가지고 있다. 이 때 금발의 젊은 여성의 이미지를 input으로 준다고 하면, ground truth label은 CelebA label: [0, 1, 0, 1, 1] + RaFD label: [0, 0, 0, 0, 0] + mask vector: [1, 0]이 된다. 여기서 +는 concat이고, 0과 1은 각 속성의 on/off를 나타내며 mask vector의 속성은 ["celebA", "RaFD"]라고 생각하면 된다.
Training Strategy
Discriminator는 CelebA와 RaFD 데이터 셋을 번갈아가며 학습하여 두 데이터 셋의 Feature들을 고루 학습하였다.
4. Implementation
Improved GAN Training
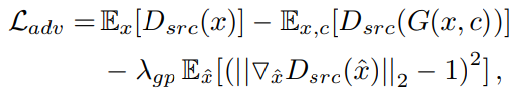
학습 과정을 안정화하고 더 높은 품질의 이미지를 만들기 위해 Wasserstein GAN의 objective function을 사용하였다.
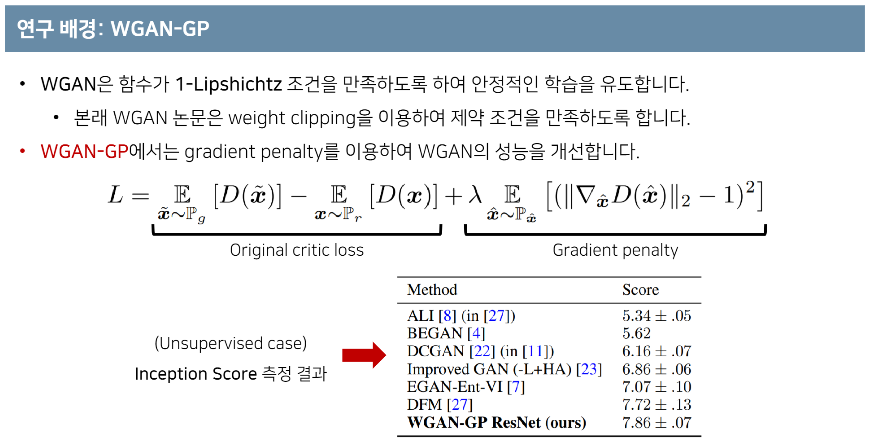
<Wasserstein GAN>
https://jonathan-hui.medium.com/gan-wasserstein-gan-wgan-gp-6a1a2aa1b490
GAN — Wasserstein GAN & WGAN-GP
Training GAN is hard. Models may never converge and mode collapses are common. To move forward, we can make incremental improvements or…
jonathan-hui.medium.com
Network Architecture
CycleGAN의 아키텍처를 Baseline으로 사용하였다.
5. Experiments
5.1. Baseline Models
DIAT, CycleGAN, IcGAN 모델의 결과와 실험 결과를 비교하였다.
5.2. Datasets
사용한 데이터 셋으로는 CelebA, RaFD 데이터 셋을 사용하였다.
- CelebA : 40개의 Label(머리색, 성별, 나이 등의 facial attribute와 관련된 정보)
- RaFD : 8개의 Label(happy, sad, angry 등의 facial expression과 관련된 정보)
5.3. Training
학습에 사용한 하이퍼 파라미터를 소개하고 있다. 자세한 수치는 논문 참고
5.4. Experimental Results on CelebA

StarGAN은 Flexible한 Translation으로 화질도 좋고 Feature도 더 잘 적용된다.
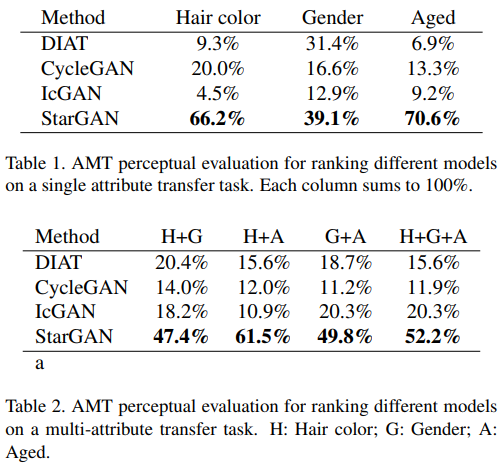
Amazon Mechanical Turk(AMT)로 정성적 평가를 받아보았는데 결과가 더 좋았다.
5.5. Experimental Results on RaFD

StarGAN은 Input 이미지의 Personal Identity과 Facial Expression을 적절하게 유지하면서 가장 자연스러워 보이는 표현을 명확하게 생성한다.
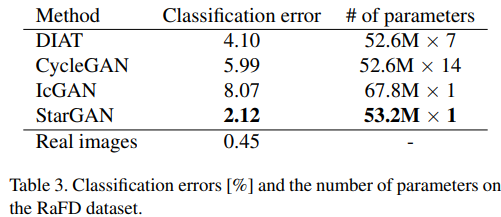
다른 모델들보다 Parameter도 더 적다.
5.6. Experimental Results on CelebA + RaFD

위는 StarGAN을 RaFD 데이터 셋에만 학습, 아래는 RaFD와 CelebA 데이터 셋을 같이 학습시킨 결과로 아래의 케이스가 더 Detail한 Feature를 잘 표현하는 것을 확인할 수 있다.

위는 적절한 Mask Vector를 사용한 결과를, 아래는 잘못된 Mask Vector를 사용한 결과를 보여준다. 위의 결과가 좋은 것을 확인할 수 있다.
6. Conclusion
본 논문에서는 하나의 Generator와 Discriminator로 여러 도메인 간의 Image-to-Image Translation이 가능한 StarGAN 모델을 제안하였다. StarGAN은 Scalability라는 장점 외에도 높은 품질의 이미지를 생성한다는 장점을 가지고, Mask Vector를 사용해서 서로 다른 도메인을 가진 여러 데이터 셋에서 효과적으로 Label을 처리할 수 있다.
<참고자료>
https://happy-jihye.github.io/gan/gan-12/
[Paper Review] StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation 논문 분석
하나의 Generator와 discriminator로 다양한 dataset에 대해 image-to-image translation을 하는 StarGAN model에 대해 알아본다.
happy-jihye.github.io
https://aistudy9314.tistory.com/52
[논문리뷰] StarGAN
이번에는 한국에서 낸 유명한 GAN논문인 StarGAN을 리뷰할 것이다. https://arxiv.org/abs/1711.09020 StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation Recent studies have shown remarkable success
aistudy9314.tistory.com
세 줄 요약
1. 하나의 모델로 다른 도메인을 가진 여러 데이터 셋간의 Image-to-Image Translation을 가능하게 만든 StarGAN 모델 제안
2. 이전까지 연구된 ACGAN, CycleGAN 등의 구조를 활용하였고 MASK Vector를 사용하여 특정 데이터 셋의 Label에만 집중할 수 있게 하였다.
3. Scalability, High Quality의 장점을 가지고 정량적, 정성적 평가 모두에서 이전보다 좋은 성능을 보였다
