[Paper Review] GLocal-K 논문 이해하기
『 GLocal-K: Global and Local Kernels for Recommender Systems. 2021. 』
이번 논문은 추천 시스템 캡스톤 발표를 위해 읽은 GLocal-K 논문이다. 이 논문에서 소개한 GLocal-K 모델은 Sparse Rating Matrix의 중요한 feature를 잡아내는 것에 집중하여 Side Information을 사용하지 않고도 SOTA를 기록하였다. AutoEncoder 구조, Convolution, Kernel Trick 등 여러 기법을 혼합하여 모델의 성능을 높였다.
이번 논문을 읽기 전 2가지 개념을 짚고 넘어가겠다.
벡터의 내적
두 벡터가 얼마나 비슷한 방향을 향하고 있는지를 측정하는 것으로 내적 값이 양수이면 두 벡터는 서로 유사한 방향, 음수인 경우 반대 방향, 0인 경우 수직으로 상관관계가 없다.
RBF(Radial Basis Function) Kernel
RBF Kernel은 SVM Classifier에서 많이 사용되는 Kernel Function이다.
$$k(x, y) = exp(-\gamma\left\|x-y\right\|^2)$$
x, y : 데이터 값
$\gamma$ : Kernel Function의 하이퍼파라미터(양의 실수)
$\left\| x-y \right\|$ : x와 y사이의 유클리드 거리
RBF Kernel은 x와 y 간의 유클리드 거리로 Kernel 값을 계산하는데, 이 때 제곱을 하는 이유는 계산의 편리성과 거리가 가까울수록 큰 값을 가지고, 멀어질수록 작은 값을 갖기 위해서이다. (데이터가 유사한 패턴을 가질 때 높은 값을 반환)
RBF Kernel을 거쳐 나온 결과는 Scalar이고 SVM 모델은 이 값을 기반으로 분류를 수행하여 Decision Boundary를 찾는다. 예를 들어 Scalar 값이 높으면 두 데이터 간의 유사도가 높다고 판단한다. 이와 같이 RBF Kernel은 비선형 문제에 효과적으로 사용할 수 있다.
※ 논문이 호주에서 쓰여져서 Kernelised, realise와 같이 영국식 영어 표현이 사용되었다.
0. Abstract
추천 시스템은 주로 Sparsity가 크고 차원이 높은 Rating Matrix 상에서 계산이 이루어진다. 본 논문에서는 GLocal-K라는 Global-Local Kernel 기반의 Matrix Completion Framework를 제안하여 Sparsity가 크고 차원이 높은 Rating Matrix를 저차원으로 일반화하고 표현하는 것을 목표로 한다.
GLocal-K는 2단계로 구성되어 있다. 1단계는 2d-RBF Kernel을 사용하여 데이터를 one space에서 feature space로 변환하는 Local Kernelized Weight Matrix를 사용하여 AutoEncoder를 Pretrain한다. 여기서는 본래 무한 차원인 RBF Kernel을 2차원으로 사용한 점을 확인할 수 있다. 2단계에서는 Convolution based Global Kernel로 Rating Matrix를 만들고 이 Matrix를 기반으로 Pretrain된 AutoEncoder를 Fine Tuning한다. 이 때 Global Kernel은 각각의 Item의 특징을 잡아낸다.
Side Information을 사용하지 않고 User-Item Rating Matrix 만을 포함하는 Extreme Low Resource Setting에서 GLocal-K 모델은 좋은 성능을 보여주었다.
1. Introduction
Collaborative Filtering 기반의 추천시스템 모델은 다른 많은 사용자들의 선호도를 수집하여 사용자의 관심을 예측하는 것이 목표이다. 하지만, Collaborative Filtering에 사용하는 Matrix는 일반적으로 너무 Sparse하다.
AutoEncoder 모델을 사용하는 기존의 모델들은 Sparse Matrix를 저차원의 Feature map으로 일반화하는데, 이 방식은 비선형적인 User-Item 관계를 효율적으로 학습하고 추상적인 표현을 데이터 표현으로 인코딩하여 시스템이 User-Item의 관계를 더 잘 이해할 수 있도록 돕는다.
추천시스템 AutoEncoder 모델
1) I-AutoRec
- Item based AE 모델을 디자인하여 고차원 Matrix를 저차원의 Latent Hidden Space로 투영하고 Output Space에서 개체를 재구성하여 비어있는 평점을 예측
https://supkoon.tistory.com/36
[추천시스템][paper review][구현] AutoRec : Auto-encoders Meet Collaborative Filtering
2015년에 발표된 본 논문은 Auto Encoder를 활용하여 협업필터링을 진행하는 모델인 AutoRec에 대하여 소개하고 있습니다. Collaborative filtering 컨텐츠 기반(content-based) 방법과 더불어 추천시스템의 한가
supkoon.tistory.com
2) SparseFC
- Finite Support Kernel을 사용하여 Weight Matrix가 Sparse한 AE 모델을 사용
3) GC-MC
- SparseFC에서 영감을 받아 Bipartite Interaction Graph(양방향 상호작용 그래프)에 전달되는 메시지의 형태를 통해 Item-User Latent Feature를 만드는 Graph기반의 AE 모델 제안
- 이렇게 만들어진 Item-User Latent Feature(Representation)은 Bilinear Decoder를 통해 Rating Link를 재구성하는데 사용
- Side Information을 추가로 사용하여 Bipartite Graph의 Rating Link 예측 성능을 높임
이와 같이 최근 연구들은 Side Information을 활용하여 성능을 높이려 하지만, 실제 세상에는 User에 대해 사용할 수 있는 Side Information이 충분하지 않다!!
따라서 본 논문에서는 Side Information 대신 고차원의 User-Item Rating Matrix를 저차원의 Latent Feature Space로 추출하는 성능을 높이는데 집중하였다. 이를 위해 Feature Extraction에 2가지 Kernel을 사용하였는데 1번 Kernel은 Local Kernel로 고차원 공간에서 데이터 변환을 수행함으로써 Optimal Separating Surfaces(최적의 분리 표면)를 제공하였고 2번 Kernel은 Global Kernel로 CNN 구조에서 비롯되어 깊은 Depth를 가질수록 Feature Ability가 높아지는 특징을 가진다.
이 2가지 Kernel을 사용하여 저차원의 Feature Space를 잘 추출할 수 있고, 이를 바탕으로 GLocal-K Framework를 제안한다.
- Pretraining the AE using a local kernelized weight matrix
- Fine-Tuning with the global kernel-based rating matrix
Main Research Contribution
- User와 Item의 Latent Feature를 추출하는데 집중한 Global & Local Kernel 기반의 AE 모델 제안
- 추천시스템에서 Pretrain과 Fine Tuning을 통합하는 새로운 방법 제안
- Side Information을 사용하지 않고도 SOTA를 기록
2. GLOCAL-K
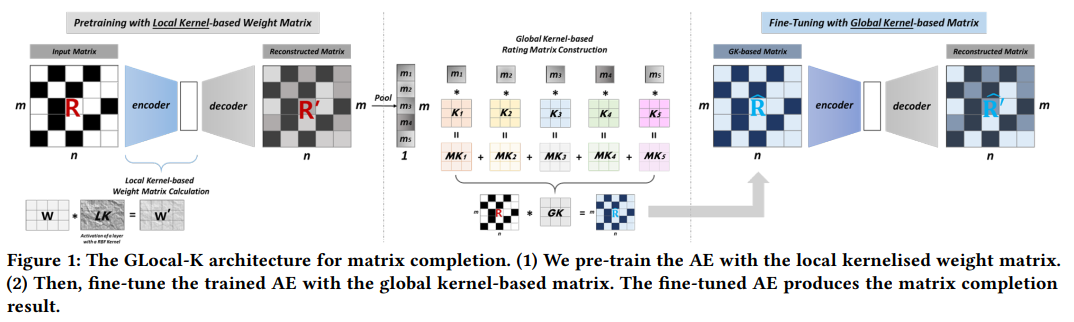
GLocal-K 모델은 두 가지 유형의 Kernel을 두 단계에 각각 적용한다. Pretrain 단계에서는 Local Kernelized Weight Matrix를, Fine Tuning 단계에서는 Global Kernelized Weight Matrix를 사용한다.
또한 2차원의 Finite Support Kernel을 사용했기 때문에 Dense한 Connection은 더 Dense하게, Sparse한 Connection은 더 Sparse하게 만들 수 있었다. 여기서 Rating Matrix는 데이터 차원을 줄이고 적지만 중요한 Feature를 만드는 Convolution Kernel에 의해 만들어졌다.
2.1. Pre-training with Local Kernel
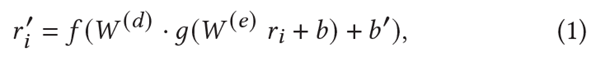
$W^{(d)}, W^{(e)}$ : 가중치 행렬(decoder, encoder)
$b, b'$ : bias vector
$f, g$ : 비선형 활성화 함수
AutoEncoder 모델은 각 항목 벡터 $r_i$를 입력받은 후 누락된 평점을 예측하기 위해 재구성된 벡터 $r'$를 출력한다. 이 때 가중치 행렬 W의 Dense, Sparse Connection을 강조하기 위해 RBF Kernel을 사용해 Weight를 Reparameterize한다.
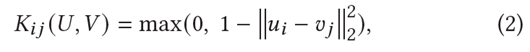
$u_i, v_j$ : U(User)에 속한 벡터, V(Item)에 속한 벡터(둘 사이의 거리가 멀어질수록 0, 동일하면 1)
※ 커널 트릭(Kernel Trick)
머신러닝 - 2. 서포트 벡터 머신 (SVM) 개념
서포트 벡터 머신(SVM, Support Vector Machine)이란 주어진 데이터가 어느 카테고리에 속할지 판단하는 이진 선형 분류 모델입니다. (Reference1) 본 포스트는 Udacity의 SVM 챕터를 정리한 것입니다. 아래 그
bkshin.tistory.com
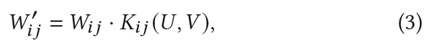
$W'$는 기존의 가중치와 Kernel Matrix 간의 Hadamard Product로 계산된다. Kernel을 거치며 관련이 없는 User-Item 간의 유사도는 0으로 계산되기 때문에 Hadamard Product의 결과 Sparse한 Weight Matrix를 얻을 수 있다.
※ Hadamard Product(아다마르 곱)
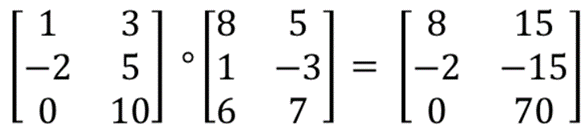
위 그림과 같이 같은 크기의 두 Matrix에서 같은 위치에 있는 값들끼리 곱을 하는 것을 의미한다.
2.2. Fine-tuning with Global Kernel
Pretrain된 AutoEncoder를 Global Convolutional Kernel로 만들어진 Rating Matrix를 이용하여 Fine Tuning한다.
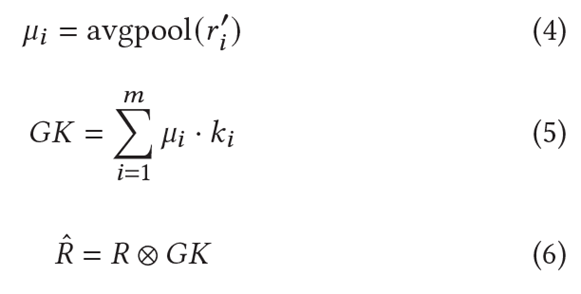
Figure 1처럼 Pretrain 모델의 Decoder를 거친 후 초기 예측에 없었던 항목을 포함한 Matrix가 Pooling layer로 전달된다. 이 때 Item-based Average Pooling을 사용하여 Rating Matrix에서 각 Item 정보를 요약한다. (Equation (4))
Pooling을 거쳐 나온 $M = {\mu1, \mu2, ... , \mu m}$은 다중 Kernel의 가중치 역할을 한다. 여기서 다중 Kernel은 $K = {k1, k2, ... , km}$으로 표현하고 Equation (5)처럼 두 Matrix는 내적을 통해 집계된다. 이 때 집계된 값은 다른 Weight나 Rating Matrix에 따라 동적으로 결정되기 때문에 Rating-Dependent Mechanism으로 볼 수 있다.
이렇게 계산된 Kernel은 Global Convolution Kernel로 사용되어 User-Item Rating Matrix와의 Convolution 연산을 수행한다. 이를 통해 Global Kernel 기반의 Feature를 추출할 수 있다.
이후 Fine Tuning의 과정은 Pretrain된 AutoEncoder 모델의 Parameter를 사용하고 위에서 만들어진 Matrix를 기반으로 모델을 Fine Tuning한다. 이렇게 계산한 결과가 최종 예측 평점이 된다.
3. Experiments
3.1. Dataset
MovieLens-100K, MovieLens-1M, Douban 데이터를 사용
3.2. Baselines
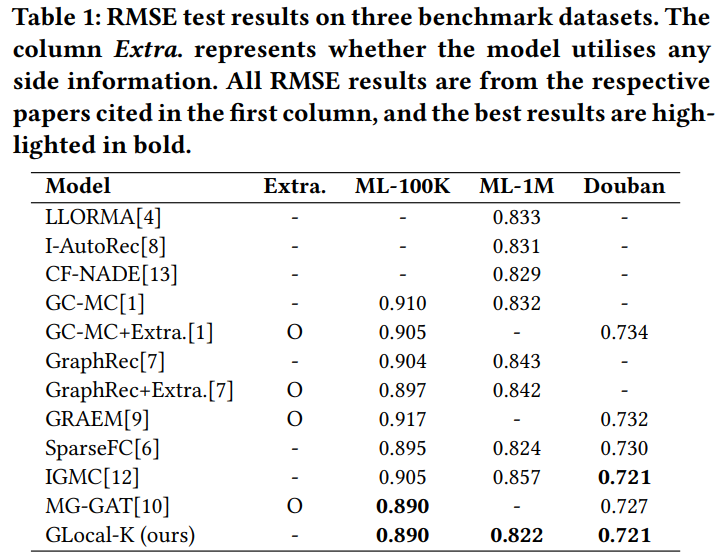
11개의 추천 시스템 모델을 RMSE 평가지표를 기준으로 비교
3.3. Experimental Setup
AutoEncoder에는 500차원인 2개의 hidden layer를 사용하였고 RBF Kernel에 대해서는 5차원짜리 벡터 $u_i, v_j$를 사용하였다. Global Convolution에는 3x3 크기의 Kernel을 가진 단일 Convolution Layer를 사용했으며 Optimizer로는 L-BFGS-B를 사용하였다.
※ L-BFGS-B (Limited-memory Broyden-Fletcher-Goldfarb-Shanno with Bounds)
제한 조건이 있는 최적화 문제를 효율적으로 풀기 위해, 제한 조건이 있는 최적화 문제를 조건이 없는 문제로 변환한 후 L-BFGS 알고리즘을 적용하는 방식이다. BFGS 알고리즘은 수치적인 안정성과 높은 수렴 속도를 가지고 있지만, 메모리 사용량이 많다는 것이 단점이었다. L-BFGS 알고리즘은 이러한 메모리 사용량 문제를 극복하여 계산 비용이 높을 때 유용하게 사용할 수 있게 한다.
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=sw4r&logNo=221475376608
[기계학습] L-BFGS-B 란?
Optimization 알고리즘 중에 하나인 L-BFGS-B 방법에 대해서 알아보겠다. BFGS 방법은 가장 인...
blog.naver.com
4. Results
4.1. Overall Performance
GC-MC, GraphRec 모델 모두 Side Information 추가시 성능이 개선된다. 하지만, 논문에서 제안한 GLocal-K 모델은 Side Information이 없음에도 좋은 성능을 보인다.
4.2. Cold-start Recommendation
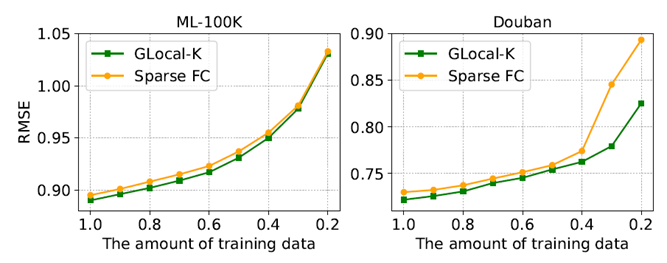
학습 크기가 감소함에 따라 오류율이 증가하는 것은 일반적으로 예상할 수 있는 결과이지만, GLocal-K 모델은 학습 크기가 줄어들 때(Cold-Start) 다른 모델보다 성능이 좋은 것을 확인할 수 있다. Figure 2를 보면, 특히 Douban 데이터에서 0.4 -> 0.2로 학습크기가 줄어들 때 Sparse FC 모델은 오류율이 급격히 증가하는데 반해 GLocal-K는 안정적으로 상승한다.
이를 통해 Global Kernel이 Feature Extraction으로 Scarce한 데이터를 잘 처리한다는 것을 알 수 있다.
4.3. Effect of Pre-training
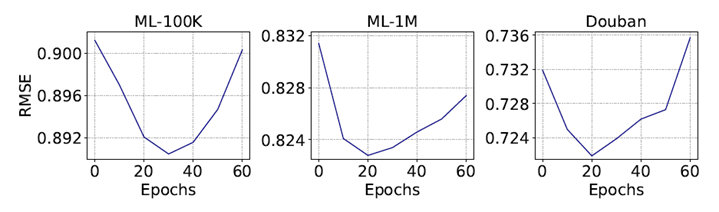
ML-100K Dataset은 30 Epoch, 나머지 Dataset에서는 20 Epoch일 때 가장 높은 성능을 보인다. ML-100K 보다 Density가 낮고 Item 개수가 많은 ML-1M, Douban Dataset에서 적은 Epoch가 필요한 것으로 추측할 수 있다.
4.4. Effect of Global Convolution Kernel
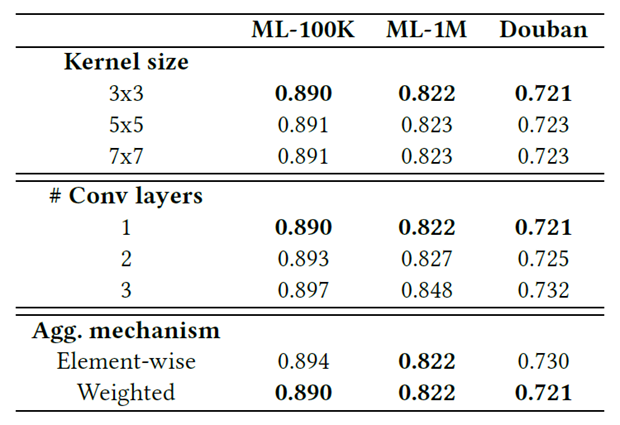
위 Table 2에서는 3가지 Dataset에서 (1) 다른 Convolution Kernel 크기 (2) 다른 Convolution Layer 수 (3) 다른 Kernel Aggregation Mechanism을 달리한 실험 결과이다.
(1) Convolution Kernel 크기
3x3 크기의 Kernel에서 성능이 좋았다. 논문에서는 이를 전체 데이터 Matrix에서 일반화 가능한 패턴을 추출하기 위해 더 작은 Kernel 크기로 더 많은 지역적인 특징에 집중하는 것이 효과적이라고 기술
(2) Convolution Layer 수
Convolution Layer는 1개일 때 성능이 가장 좋았다.
(3) 다른 Kernel Aggregation Mechanism
Kernel Aggregation을 할 때는 Feature-Indicative Weight를 사용하는 것이 효과적이었다.
5. Conclusion
적은 Resource 환경에서도 Sparse한 Rating Matrix의 중요한 Feature를 잡아내고 개선하기 위해 Pretrain 단계에서의 Local Kernel, Fine Tuning 단계에서의 Global Kernel을 모두 활용하였다. 이를 통해 Side Information 없이도 여러 Dataset에서 SOTA를 달성하였고, Cold-Start 문제에서도 좋은 성능을 보였다.
<참고자료>
https://github.com/usydnlp/Glocal_K/blob/main/GLocal_K.ipynb
GitHub - usydnlp/Glocal_K: This repository contains code for paper GLocal-K: Global and Local Kernels for Recommender Systems, p
This repository contains code for paper GLocal-K: Global and Local Kernels for Recommender Systems, published in CIKM 2021 - GitHub - usydnlp/Glocal_K: This repository contains code for paper GLoca...
github.com
세 줄 요약
1. Side Information을 사용하지 않고 Feature Extraction에 집중하는 GLocal-K 모델 제안
2. AE 구조를 기반으로 Pretrain, Fine Tuning 과정에서 2개의 Kernel을 사용해 중요한 Feature를 추출
3. 여러 Dataset에서 SOTA를 달성하였고 추후 Matrix Completion에서 Kernel을 통합하는 연구에 기여
