[Paper Review] Model Soup 논문 이해하기
『 Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. 2022. 』
Github : https://github.com/mlfoundations/model-soups
GitHub - mlfoundations/model-soups
Contribute to mlfoundations/model-soups development by creating an account on GitHub.
github.com
이번 논문은 학부 연구생 활동을 하며 읽은 Model soup 논문이다. 이 논문에서는 기존에 사용하던 앙상블 기법이 k개의 모델을 활용할 때 그에 비례하여 Inference 시간이 k배 증가한다는 단점을 지적하며, 여러개의 model weight를 평균 내어 Inference 시간을 줄이는 Model soup 방법을 제안한다.
최신 연구는 큰 데이터로 Pre-trained 된 모델을 받아 Fine-tuning 하는 트렌드를 따른다. 이러한 Fine-tuning 과정은 일반적으로 여러 Pre-trained 모델에 대해 테스트한 뒤 가장 성능이 좋은 모델을 남기고 나머지 모델은 버리는 방식을 취하는데, 이 방법은 몇가지 단점을 가진다.
1. 높은 computational cost가 들더라도 여러 모델을 앙상블한 결과가 단일 모델보다 성능이 좋다.
2. Fine-tuning한 모델은 해당 task에서 성능이 좋더라도 target distribution에서 벗어날 경우 성능이 떨어진다.
따라서 본 논문에서는 이러한 단점을 극복하여 정교하고 강건한 모델인 Model Soup를 제안한다. 지금까지는 validation accuracy가 높은 하나의 Fine-tuned 모델을 선택했다면 Model Soup 방법은 Fine-tuned 된 여러 모델들의 weight들을 평균내어 사용한다.
Method

기존에 사용하던 Ensemble 방법은 k개의 모델을 합쳐 사용하기 때문에 위의 Table과 같이 O(k)의 시간복잡도를 가지지만, Model Soup로 단순히 weight들을 평균내어 사용한다면 O(1)의 시간 복잡도를 가지게 된다. 이렇게 weight를 평균내는 아이디어는 같은 Pretrained 모델에서 initialization된 모델들은 같은 error(loss) landscape를 가지고 있고, 서로 다른 Parameter로 학습한 모델의 Ensemble이 성능을 향상시키기 때문에 사용하였다.
※ 가중치를 평균내는 아이디어
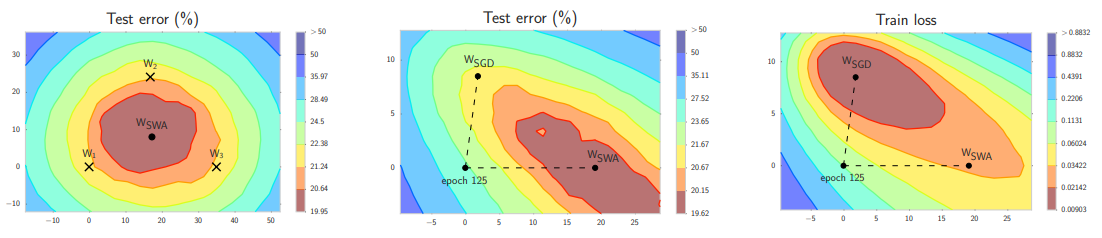
[Izmailov et al. 2018] 논문에서 제안된 Stochastic Weight Averaging(SWA) 방법에서는 single optimization trajectory에서 weight를 평균낼 때 성능이 좋아지는 것을 보여준다. 예를 들어 왼쪽의 Test error 그림에서 보이는 W1, W2, W3 값을 평균 낼 경우, error 값이 해당 landscape에서 가장 낮은 bound로 이동하는 것을 볼 수 있다.
또한 [Neyshabur et al. 2020] 논문에서는 동일한 Initialization에서 최적화 된 모델들은 같은 basin을 향한다고 설명한다.
위 두가지 아이디어가 논문의 주요한 Motivation이다. 여러 종류의 하이퍼 파라미터로 학습시킨 모델들은 한가지 Pre-trained 모델에서 기인하였기 때문에 결국 같은 landscape의 basin을 향하고 있고, 이 모델들의 weight를 평균 내어 더 낮은 bound로 weight를 이동시킬 수 있는 것이다.
가장 일반적인 weight averaging 방법으로는 Uniform하게 평균내는 방법이 있지만, 본 논문에서 main으로 소개하는 방식은 Greedy soup 방식이다. 이 방법은 아래에서 자세히 소개하도록 하겠다.
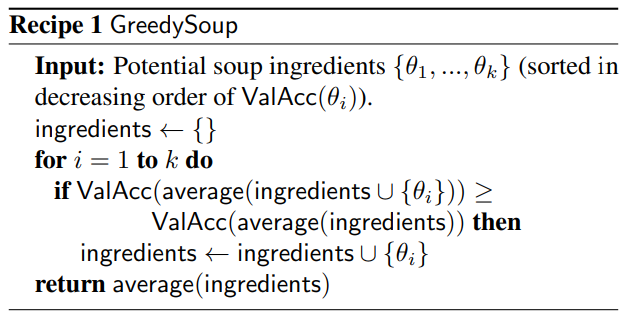
우선 가장 기본적인 Uniform Soup 방법은 모델이 k개가 있을 때 단순히 weight를 각 모델의 weight / k의 합으로 계산하는 방법이다. 단순하지만, 성능이 낮은 모델도 성능이 높은 모델과 같은 취급을 한다는 단점이 존재한다.
따라서 본 논문에서는 Greedy Soup 방법을 제안하는데, 이 방법은 만약 모델이 k개가 존재할 때 모델을 ValAcc 순으로 내림차순 정렬한 후 가장 성능이 높은 모델의 weight부터 추가해가며 추가한 요소들로 계산한 ValACC가 기존의 요소들만으로 ValACC를 계산했을 때보다 성능이 좋을 때에만 해당 모델을 선택하는 방법이다. (변수 선택 과정의 전진선택법과 비슷하다)
마지막으로는 더 advanced한 방법인 Learned Soup 방법을 소개한다. Learned Soup는 Greedy Soup 방식에서 Sequential Constraint를 제거하고 validation set을 한번만 통과하는 방법으로 gradient-based minibatch optimization으로 weight를 구성하는 모델을 선택하는 방법이다. 하지만 이 방법은 사용하려는 모든 모델을 동시에 메모리에 올려야 하기 때문에 큰 네트워크를 구성하는데 방해가 되는 비효율적인 방법이다.

실제로 Model Soup를 사용하여 Accuracy를 측정해 본 결과, 위의 그림과 같이 단일 모델을 사용할 때보다 더 좋은 성능을 얻을 수 있었다. (5 distribution shifts : ImageNet-V2, ImageNet-R, ImageNet-Sketch, ObjectNet, ImageNet-A)
Experiments
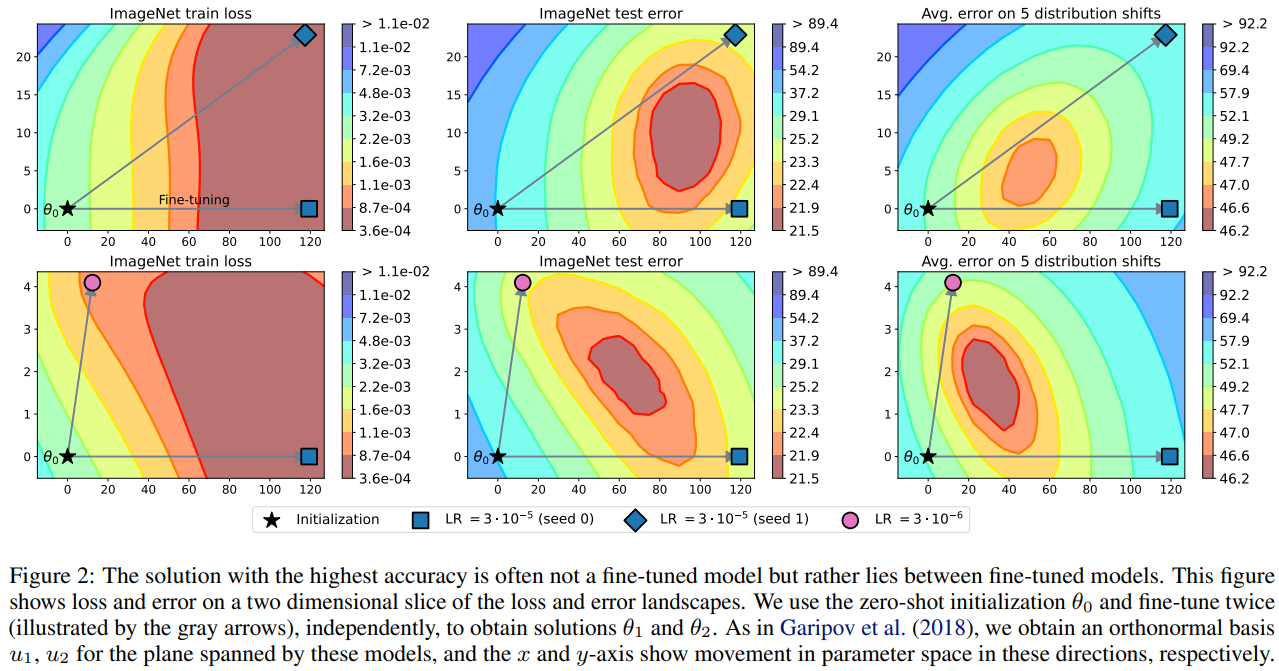
위 그림은 Landscape의 두 weight를 평균 내었을 때 실제로 성능이 더 좋아지는지를 보여준 그림이다. 위 줄의 그림은 2가지 Fine-tuning 모델을 seed만 다르게 하여 보여주었고, 밑 줄의 그림은 다른 Learning Rate로 학습한 모델의 결과를 보여준다. Initialization에서 이동한 두 모델을 interpolation 할 경우 lower bound에 가까운 곳에 영역이 형성되는 것을 확인할 수 있다. (두 점을 선으로 연결하여 가운데 점을 찍는다고 생각)
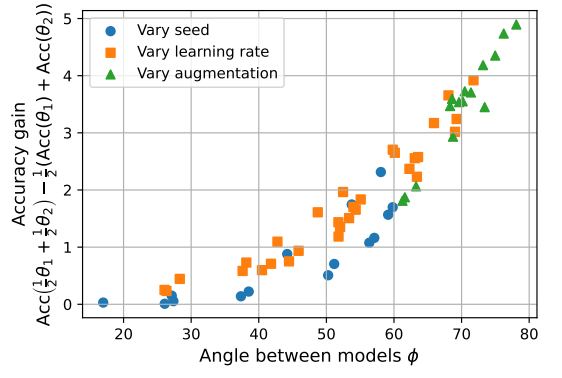
위 그림은 어떤 모델들을 averaging 했을 때 좋은 결과가 나올지를 파악하기 위해 두 모델간의 Angle과 Accuracy gain을 측정한 결과이다. Seed, Learning Rate, Augmentation이 다른 방법들 간의 Angle 값을 계산하였고, 여기서 Accuracy gain은 각 weight를 $\theta_1$, $\theta_2$로 두고 (두 값의 평균 값으로 계산한 Accuracy) - (각 $\theta$ 값에서 계산한 Accuracy의 평균 값)으로 계산한다.
결국 실험을 통해 Angle이 클 수록 Accuracy gain이 커지고, 사잇각이 90도에 가까운 2가지 모델을 사용할 때 성능이 좋아진다는 것을 확인할 수 있다.
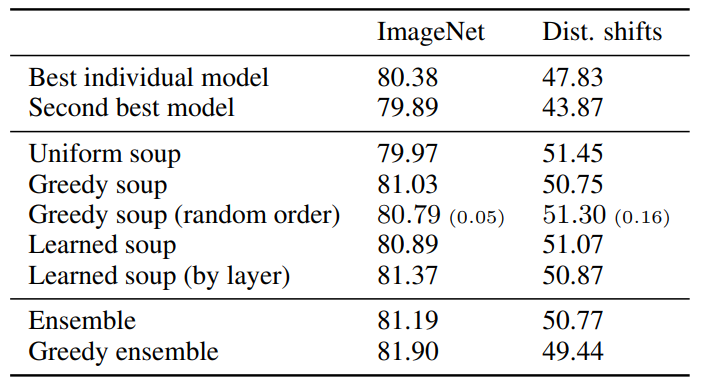
위 표는 CLIP ViT-B/32로 Pretrained 된 모델을 랜덤 하이퍼 파라미터로 Fine-Tuning한 모델에 Model Soup를 적용한 결과를 보여준다. Greedy Soup을 사용했을 때 단일 모델을 사용한 것보다 결과가 좋아진 것을 확인할 수 있고, 성능 순이 아닌 random order를 사용했을 때 성능이 더 안좋아진 것도 확인할 수 있다. Ensemble의 경우에는 Model Soup 방법보다 성능이 좋지만 Inference time이 k배로 증가하는 단점이 존재한다.
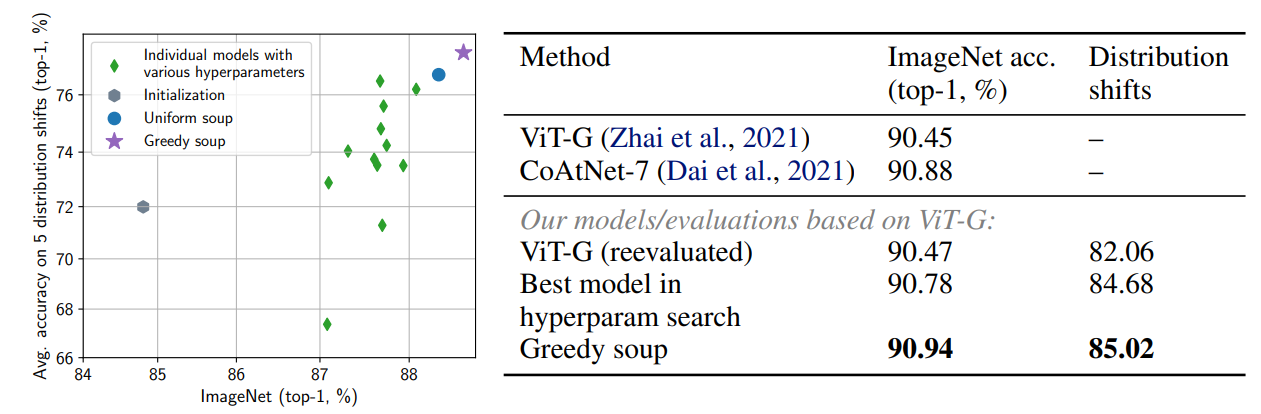
Align 데이터와 JFT-3B 데이터로 실험을 진행했을 때(J.2.2. / J.2.3)에도 Greedy Soup 방법이 좋은 성능을 보이는 것을 확인할 수 있다.
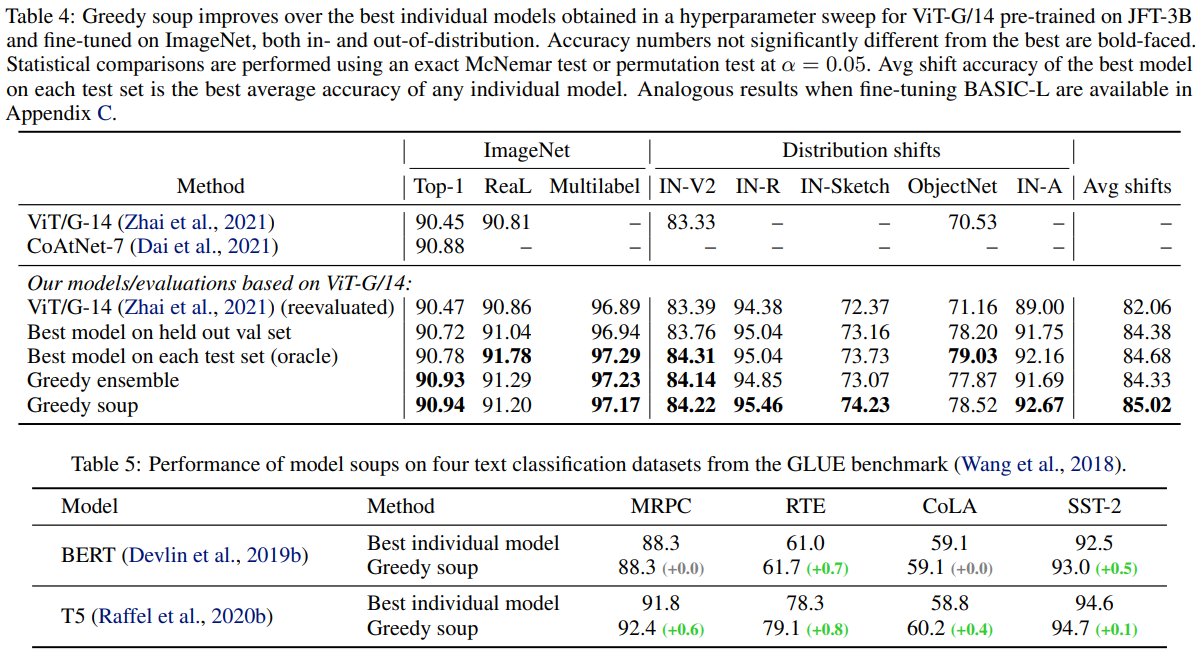
Learning rate, Decay Schedule, loss function, data augmentation 등 여러 하이퍼파라미터를 다르게 한 58개의 모델을 사용하여 실험하였고 그 결과 Greedy soup(그 중 14개 모델 사용)의 결과가 Distribution shift에도 강하고 성능 또한 높게 나오는 것을 확인할 수 있다.
Image task뿐만 아니라 Text classifacation task에서 또한 성능 향상을 확인할 수 있다. 대부분의 방법에서 Best individual model보다 Greedy soup를 사용한 모델의 성능이 좋았다.
Limitation
1. Applicability
: 초 거대 data로 실험을 진행했기 때문에 작은 data로 Model Soup를 진행할 경우 성능 향상 정도가 약하다
2. Calibration
: Ensemble 기법은 model의 calibration을 향상시킬 수 있지만 Model Soup는 그렇지 않다.
※ Model Calibration
: 모델의 출력값이 실제 confidence를 반영하게 만드는 것으로, 모델의 예측 값이 실제 확률을 반영하는 것을 의미한다.
https://arxiv.org/pdf/1706.04599.pdf
<참고자료>
https://www.youtube.com/watch?v=Uxj0Kp37mkw
세 줄 요약
1. Ensemble의 효과를 가지며 Inference time을 획기적으로 줄일 수 있는 Model Soup 모델 제안
2. 좋은 모델만 선택해 가중치를 평균내는 Greedy Soup 방식으로 Image, Text task에서 높은 성능을 얻음
3. Applicability, Calibration 같은 한계점이 아직 존재
