[X:AI] Inception-v2, v3논문 이해하기
INCEPTION
Inception은 ILSVRC 2014(ImageNet Large-Scale Visual Recognition Challenge)에서 1등을 차지한 GoogLeNet에서 사용된 핵심 구조의 이름으로『Going deeper with convolutions』논문을 통해 그 특징을 파악할 수 있다. 실제로 논문의 이름은 영화 "인셉션"에서 유래한 밈에서 따왔다고 한다. (실제 영화에서 언급된 말은 아닌듯..)

오늘 소개할 내용은 Inception-v2, v3가 소개된 논문이 메인이기 때문에 우선은 Inception에 대한 간단한 정보만 짚고 넘어가겠다. Inception module의 구조는 아래 그림과 같으며 주된 아이디어는 여러개의 convolution filter를 이용해 feature map을 효과적으로 추출하는 것이다.
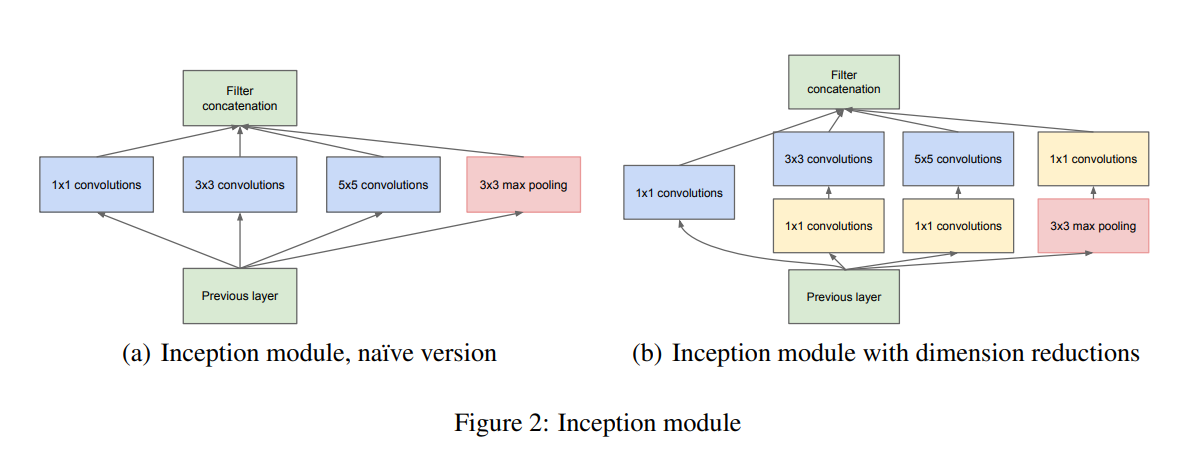
하지만 (a) 그림과 같이 단순히 convolution만 진행할 경우 연산량이 굉장히 많아지기 때문에 이를 해결하고자 1x1 convolution을 추가하였다. 이는 Network In Network(NIN) 논문의 방법을 차용한 것으로, feature map을 flatten하기 전에 1x1 convolution layer를 사용해 채널과 연산량을 획기적으로 줄일 수 있다.

위 그림은 GoogLeNet의 모델 구조로 9개의 Inception 모듈을 활용해 Deep한 Network를 구축한 것을 확인할 수 있다. 또한 Train 과정에만 사용하는 Auxiliary Classifier가 존재하는데, 이는 네트워크의 깊이가 깊어질 수록 Gradient Vanishing 문제가 생기기 때문에 이를 극복하기 위해 네트워크 중간에서 FC layer를 거쳐 학습 과정에서의 오차를 학습할 수 있도록 도와준다. 이때 Auxiliary Classifier는 최종 오차에 대한 영향력이 없어지는 것을 막기 위해 loss 값의 30% 정도만을 최종 loss에 추가한다.
『 Rethinking the Inception Architecture for Computer Vision. 2015. 』
Convolution Network가 대부분의 Vision Task에서 주류로 자리잡았지만, 아직 한계점이 많이 존재하기에 더 작은 모델과 효율적인 계산을 위한 방법을 찾고싶어 쓰여진 논문이다. GoogLeNet과 비슷한 성능을 보였던 VGG 모델의 구조가 단순하지만 parameter의 수가 훨씬 많다는 점에 주목하여 parameter의 수가 적고 구조가 단순한 모델을 구현하고자 하였다.
논문에서 소개하는 주요 기법은 다음과 같다.
1. Factorizing Convolution
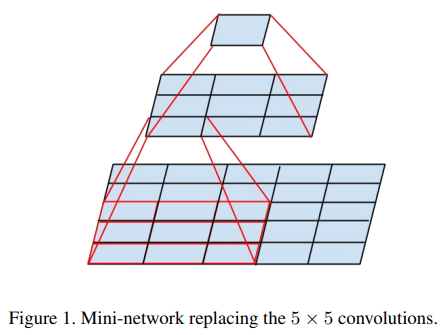
Spatial filter가 큰 Convolution은 더 많은 계산량을 필요로 한다. 예를 들어 같은 수의 필터를 사용하는 5 x 5 convolution 연산은 3 x 3 convolution 연산보다 25 / 9 = 2.78배 정도의 비용이 더 들게 된다. 따라서 논문에서는 5 x 5 convolution을 더 적은 parameter를 가진 multi-layer로 바꾸려하는데, 이 과정이 Vision Network를 구축하는 것이기 때문에 translation invariance를 2-layer convolution에서 다시 이용하더라도 문제가 없다.
※ Translation Invariance
: Input이 변하더라도 변함없이 학습 패턴을 파악해 동일한 output을 가지는 convolution의 특징
https://ganghee-lee.tistory.com/43
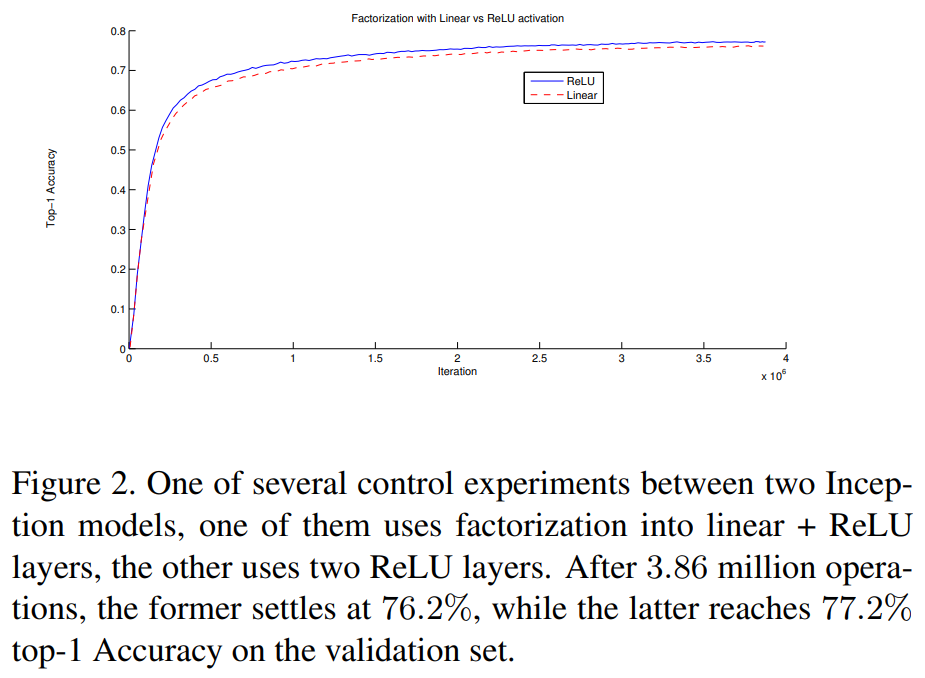
따라서 5 x 5 convolution을 2개의 3 x 3 convolution layer로 factorize할 수 있고 이 때 2개의 3 x 3 convolution layer는 가중치를 공유하기 때문에 더 적은 파라미터를 가진다. 첫 번째 3 x 3 convolution layer에는 linear activation, 두 번째에는 ReLU activation을 적용한 경우와 모두 ReLU activation을 사용한 경우를 테스트 했을 때 위 그림처럼 모두 ReLU를 사용했을 때가 더 좋은 성능을 보였다.

결국 기존 왼쪽의 GoogLeNet 구조에서 사용한 5 x 5 convolution을 3 x 3 convolution 2-layer 구조로 Factorize 하였다.
2. Spatial Factorization into Asymmetric Convolutions

위에서는 3 x 3 convolution으로 factorization하는 것의 장점을 소개하였는데 그렇다면 더 작게 분해할 수는 없을까? 본 논문에서는 2 x 2 convolution같이 대칭형 convolution으로 fatorization하는 것 보다 n x 1 형태의 비대칭 convolution이 더 좋은 결과를 보인다고 말한다. 따라서 위의 그림처럼 3 x 3 convolution을 1 x 3, 3 x 1로 분해할 수 있고 이 경우 $\frac{3+3}{9} = 0.66$로 33% 정도의 연산량이 줄어든다고 한다. (2 x 2 convolution의 경우에는 $\frac{4+4}{9} = 0.89$로 11%만큼 연산량 감소)
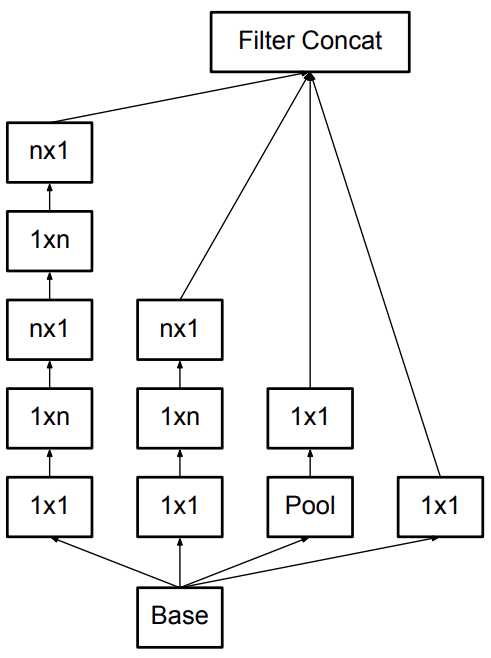
따라서 n x n convolution을 모두 n x 1, 1 x n convolution으로 대체하면 위와같은 Inception 모듈이 만들어진다.
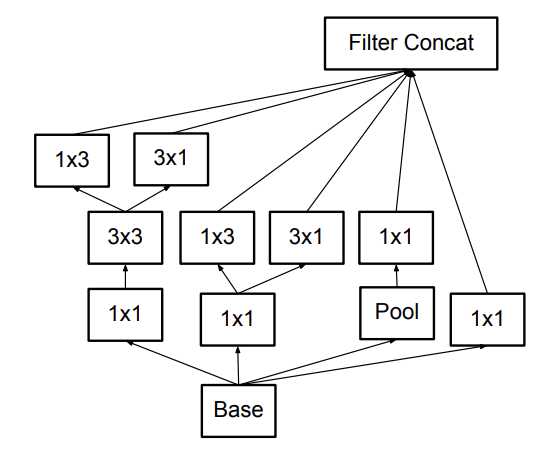
위 그림은 Filter bank size를 확장한 Inception 모듈로 grid size가 가장 작아졌을 때 사용한다.
3. Utility of Auxiliary Classifiers
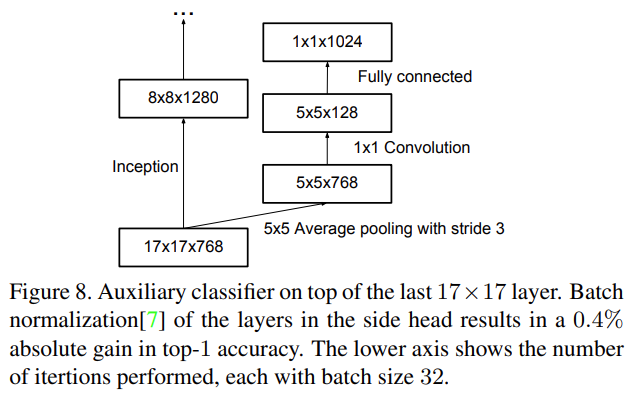
GoogLeNet은 Train 과정에서 Auxiliary Classifier를 도입하여 Gradient Vanishing 문제를 해결하려 하였다. 하지만 실험 결과 하위의 Auxiliary branch를 제거하더라도 최종 성능에 큰 차이를 보이지 않았고, 오히려 Auxiliary Classifier에 Dropout이나 Batch Normalization을 사용하였을 때 성능이 좋아진다고 한다. 이는 Auxiliary Classifier가 성능 향상보다 정규화 효과가 있을 것이라는 추측의 근거가 된다.
4. Efficient Grid Size Reduction
일반적으로 CNN에서는 Feature map의 크기를 줄이기 위해 pooling을 사용한다. 하지만 pooling은 연산량을 줄이는 대신 신경망의 representation 또한 감소시킨다는 문제가 존재한다.
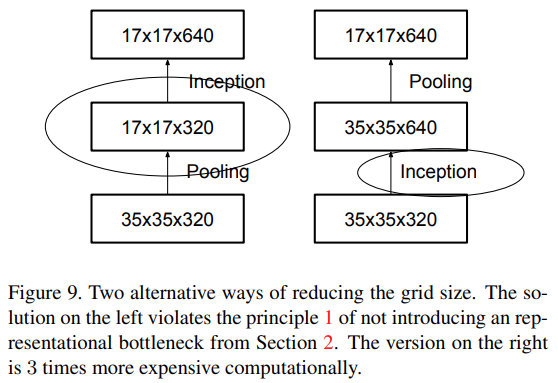
이 문제를 해결하기 위해 convolution과 pooling의 순서를 바꾼다면 위 그림의 왼쪽과 같이 연산량은 줄어들지만 Representation이 낮아지고 Representational Bottleneck을 야기한다. 반대로 오른쪽은 연산량이 3배나 많다.
※ Representational Bottleneck
: CNN에서 주로 사용하는 Pooling으로 인해 Feature map의 size가 줄어들면서 정보량이 줄어드는 현상
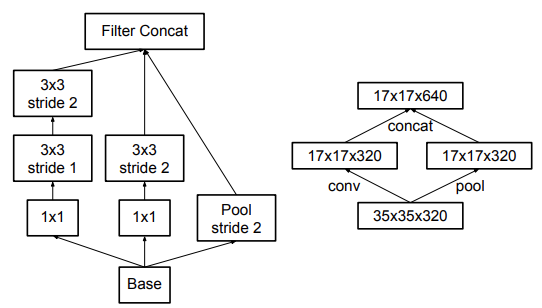
따라서 논문에서는 Representational Bottleneck을 피하고 연산량도 줄일 수 있는 구조를 제안한다. 이는 위의 그림과 같이 stride가 2인 pooling layer와 convolution layer를 병렬로 사용해 concatenate하는 구조로 Representation을 감소시키지 않고 25%만큼 연산량을 줄일 수 있다고 한다.
지금까지 소개한 주요 방법들을 결합하여 논문에서는 새로운 아키텍처인 Inception-v2를 제안한다.
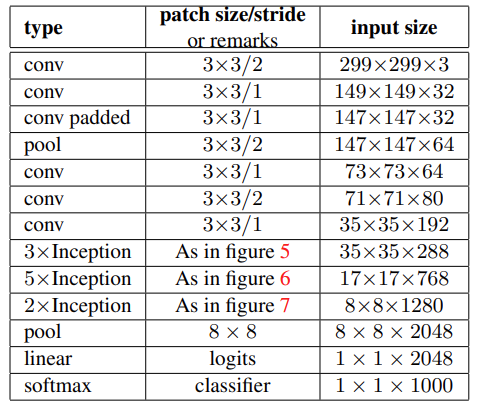
Inception-v2의 구조는 위와 같고 총 42층으로 구성되어 있지만 연산량이 GoogLeNet보다 약 2.5배 많고 VGG보다 더 효율적이다.
추가적으로 논문에서는 Label Smoothing 방식을 소개한다. 일반적으로 Classification Network에서 Train을 진행할 때 정답은 1, 정답이 아닌 값은 0인 one hot vector를 Label로 사용하는데 반해 이 방법은 0 대신에 작은 값을 Label로 사용하는 방식이다.
$$ y^{LS}_k = y_k(1-\alpha) + \alpha/K$$
K = 클래스 개수
$\alpha$ = Smoothing parameter
예를 들면 [0, 0, 0, 0, 1] 값을 위 식에 대입할 경우 ($\alpha$ = 0.1) K=5 이므로 기존에 0이 었던 값은 0(1-0.1) + 0.1/5 가 되어 0.02의 값을 가지고 기존에 1이었던 값은 1(1-0.1) + 0.1/5 가 되어 0.92가 된다. 따라서 전체 Label은 [0.02, 0.02, 0.02, 0.02, 0.92] 로 바뀌고 이전보다 정답에 대한 확신이 줄어든다.
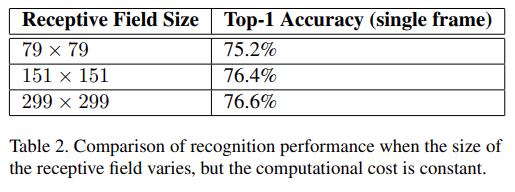
또한 낮은 해상도의 Input에 대한 성능을 위 그림처럼 3가지의 Receptive Field Size로 나누어 테스트 해 보았고 학습 시간은 오래 걸리지만 성능은 높은 해상도와 거의 비슷하다.
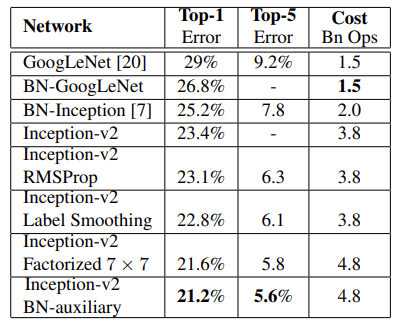
마지막으로는 Inception-v3 모델을 소개한다. Inception-v2 모델에 앞서 소개한 기법들을 모두 적용한 모델로 BN-Auxiliary, RMSProp, Label Smothing, Factorized 7x7 을 모두 적용하였다. 위 표의 가장 마지막 네트워크가 Inception-v3의 결과이다.
<참고자료>
https://hyunsooworld.tistory.com/40
Inception v1,v2,v3,v4는 무엇이 다른가 (+ CNN의 역사)
- References https://youngq.tistory.com/40 https://junklee.tistory.com/111 https://medium.com/@msmapark2/vgg16-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-very-deep-convolutional-networks-for-large-scale-image-recognition-6f748235242a https://velog.io/@whgurwns2
hyunsooworld.tistory.com
https://sike6054.github.io/blog/paper/third-post/
(Inception-v3) Rethinking the inception architecture for computer vision 번역 및 추가 설명과 Keras 구현
sike6054.github.io
세 줄 요약
1. Parameter의 수를 줄이고 구조를 단순화 할 수 있는 Inception 모델 제안
2. Factorization, Asymmetric Convolution, Auxiliary 제거 등의 기법으로 모델 구축
3. Label Smoothing을 이용해 성능을 높인 v3 버전, 추가로 2016년에 나온 Inception-v4가 존재
